stanford专题

深度学习 --- stanford cs231学习笔记四(训练神经网络的几个重要组成部分之一,激活函数)
训练神经网络的几个重要组成部分 一 1,激活函数(activation functions) 激活函数是神经网络之于线性分类器的最大进步,最大贡献,即,引入了非线性。这些非线性函数可以被分成两大类,饱和非线性函数和不饱和非线性函数。 1,1 饱和非线性函数 1,1,1 Sigmoid 原函数: 函数的导数: sigmoid函数的性质:

深度学习 --- stanford cs231学习笔记五(训练神经网络的几个重要组成部分之二,数据的预处理)
训练神经网络的几个重要组成部分 二 2 Data Preprocessing数据的预处理 数据预处理的几种方法 2,1 数据的零点中心化 数据的零点中心化的目的就是为了把数据的整体分布拉回到原点附近,也就是让数据的整体均值变为0。 2,2 数据的标准化 数据的标准化这个词比较难理解,从统计学的角度讲,经过这一步的处理,原
深度学习 --- stanford cs231 编程作业(assignment1,Q3: softmax classifier)
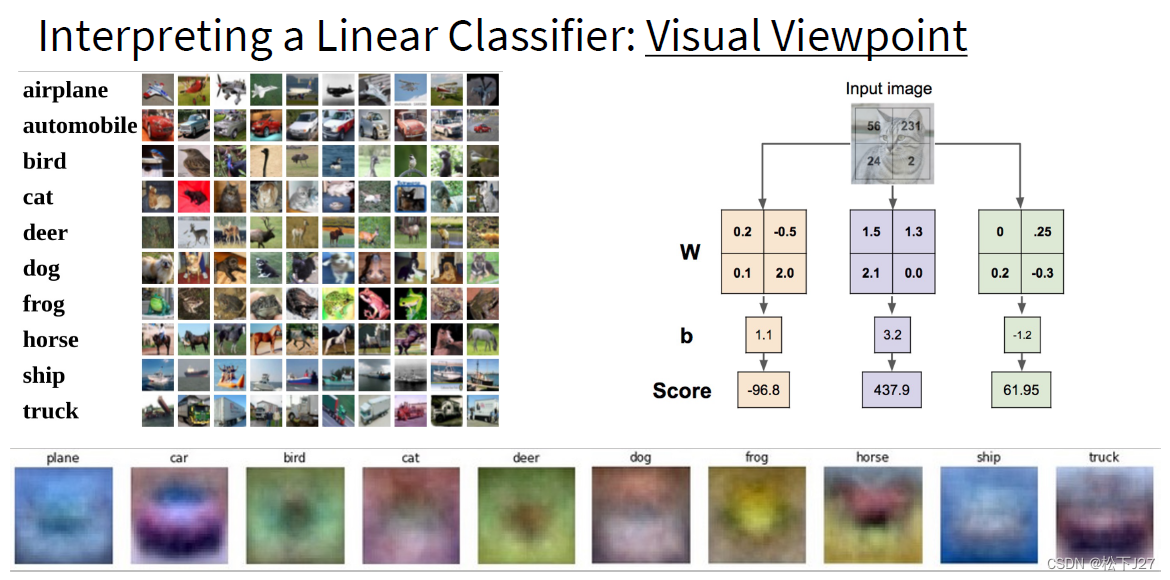
stanford cs231 编程作业(assignment1,Q3: softmax classifier softmax classifier和svm classifier的assignment绝大多部分都是重复的,这里只捡几个重点。 1,softmax_loss_naive函数,尤其是dW部分 1,1 正向传递 第i张图的在所有分类下的得分

Llama模型家族之Stanford NLP ReFT源代码探索 (三)reft_model.py代码解析
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
Llama模型家族之Stanford NLP ReFT源代码探索 (二)Intervention Layers层
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3

深度学习 --- stanford cs231 编程作业(assignment1,Q2: SVM分类器)
stanford cs231 编程作业之SVM分类器 写在最前面: 深度学习,或者是广义上的任何学习,都是“行千里路”胜过“读万卷书”的学识。这两天光是学了斯坦福cs231n的一些基础理论,越往后学越觉得没什么。但听的云里雾里的地方也越来越多。昨天无意中在这门课的官网上无意中看到了对应的assignments。里面的问题和code都设计的极好!自己在做作业的时候,也才
Keras深度学习框架实战(3):EfficientNet实现stanford dog分类
1、通过EfficientNet进行微调以实现图像分类概述 通过EfficientNet进行微调以实现图像分类,是一个使用EfficientNet作为预训练模型,并通过微调(fine-tuning)来适应特定图像分类任务的过程。一下是对相关重要术语的解释。 EfficientNet:这是一个高效的卷积神经网络(CNN)架构,旨在通过统一缩放网络深度、宽度和分辨率等维度来优化性能和效率。Effi

使用Stanford-CoreNLP命令行进行分词
接上文 https://blog.csdn.net/guotong1988/article/details/136652691 java -cp "stanford-corenlp-4.5.6/*" edu.stanford.nlp.international.arabic.process.ArabicTokenizer normArDigits,normArPunc,normAlif,remo

StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 2.1理论知识之前已经说明:http://www.cnblogs.com/wjy-lulu/p/7010258.html 2.2公式的推导 2.2.1. Jense
StanFord ML 笔记 第八部分
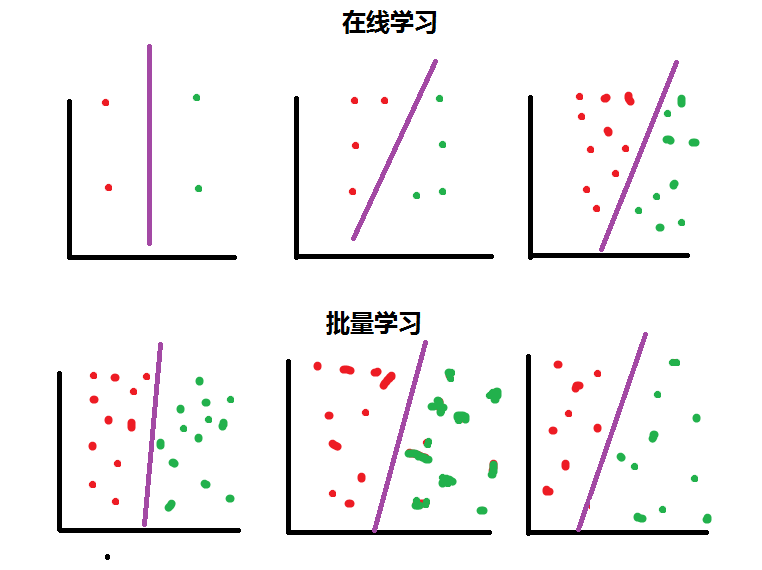
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 解释之前,先说明这样做的目的:如果一个模型我们只打算对现有数据用一次就不再用了,那么正则化没必要了,因为我们没打算在将来他还有用,正则化的目的是为了让模型的
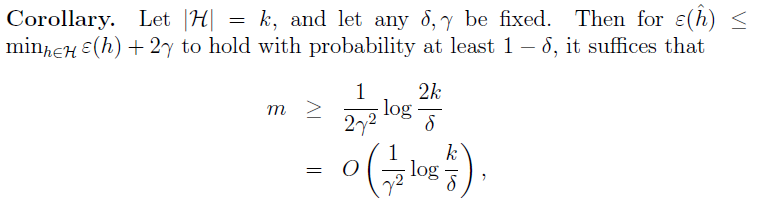
StanFord ML 笔记 第六部分第七部分
第六部分内容: 1.偏差/方差(Bias/variance) 2.经验风险最小化(Empirical Risk Minization,ERM) 3.联合界(Union bound) 4.一致收敛(Uniform Convergence) 第七部分内容: 1. VC 维 2.模型选择(Model Selection) 2017.11.3注释:这两个部分都是讲述理论
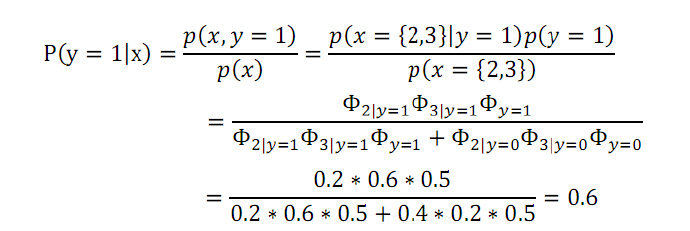
StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图。 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate Bernoulli Event Model,以下简称 NB-MBEM)。该模型有多种扩展,一种是在上一篇笔记中已经提到的每个分量的多值化,即将p(x
Stanford斯坦福 CS 224R: 深度强化学习 (3)
基于模型的强化学习 强化学习(RL)旨在让智能体通过与环境互动来学习最优策略,从而最大化累积奖励。传统的强化学习方法如Q-learning、策略梯度等,通过大量的试错来学习值函数或策略,样本效率较低。而基于模型的强化学习(MBRL)则利用对环境的预测模型来加速学习过程,大大提高了样本利用率。本章我们将系统地介绍MBRL的基本原理、核心算法、实现技巧以及代表性应用。 1. 采样优化入门 在探讨

Stanford斯坦福 CS 224R: 深度强化学习 (5)
离线强化学习:第一部分 强化学习(RL)旨在让智能体通过与环境交互来学习最优策略,从而最大化累积奖励。传统的RL训练都是在线(online)进行的,即智能体在训练过程中不断与环境交互,实时生成新的状态-动作数据,并基于新数据来更新策略。这种在线学习虽然简单直观,但也存在一些局限性: 在线交互的样本效率较低,许多采集到的数据未被充分利用对于一些高风险场景(如自动驾驶),在线探索可能会带来安全隐患

Stanford-Coursera 算法Week1 笔记
题外话:全文免费放心食用,作者在此求个 三连+关注 1. Integer Multiplication(引入) (很小的时候我们就学过:两个数字相乘的算法——将输入(两个数字)转换为输出(它们的乘积)的一组定义良好的规则;算法就是类似的:一个计算问题(输入和期望的输出),然后描述一个或多个解决该问题的算法) 1)定义计算问题:在整数乘法问题中,输入是两个n位数,我们称之为x和y, x和y的长

深度学习 --- stanford cs231学习笔记(一)
stanford cs231学习笔记(一) 1,先是讲到了机器学习中的kNN算法,然后因为kNN分类器的一些弊端,引入了线性分类器。 kNN算法的三大弊端: (1),计算量大,当特征比较多时表示性差 (2),训练时耗时少,且计算需求低,反而是对测试数据分类时,计算需求量大。 (3),衡量两幅图像之间的差异时,衡量方式单一,例如L1,L2距离。且仅有的这两种方法效果都

Stanford哈工大 编译原理
文章目录 1 introduction to compilers2 Lexical analysis2.1 regular language & formal language(P9+P10+P11) 3 Parsing(P18)3.1 CFG: context-free grammar(P19+P20)3.2 derivation: 派生、推导(P20) 4 Semantic analys

Stanford CS231N
文章目录 1 introduction to convolutional neural network2 Image classification pipeline2.1 nearest neighbors classifier/KNN2.2 Linear classification 3 loss function and optimization3.1 loss function of

UCB CS162 Stanford CS144 Information Theory(Math monk)
文章目录 1 Introduction2 History and Structure of OS3 Concurrency: processes, threads, and address spaces4 thread dispatching(派遣)1 IP service model2 TCP service model 1 Introduction http://inst.e
Stanford CS230学习笔记(二):Lecture 2 Basics, Logistic Regression and Vectorization
事先声明:本文是写给自己看的,发在这里是因为掘金图床真的好方便orz(是的之前在掘金上,但是后来掘金的文中代码块标红,好难看!),本系列将按照我自己的逻辑整理,知识点并没有全写上,还可能会出现随心所欲中英文混杂的情况,公式也打算截图,如果你碰巧看到我的想要照着看也不是不行,但网上总结得比我好的太多了,甚至可以去找找看Stanford自己整理的笔记,内容很全,不过是全英文的,而且排版有点反人类 深
Stanford Parser 标签说明
词性解释 CC: conjunction, coordinatin 表示连词 CD: numeral, cardinal 表示基数词 DT: determiner 表示限定词 EX: existential there 存在句 FW: foreign word 外来词 IN: preposition or conjunction, subordinating 介词或从属连词 JJ: adj
博弈论 斯坦福game theory stanford week 5.1_
title: 博弈论 斯坦福game theory stanford week 5-1 tags: note notebook: 6- 英文课程-15-game theory --- 博弈论 斯坦福game theory stanford week 5-1 练习 1. Question 1 Two players play the following normal form game. 1
使用Stanford NLP工具实现中文命名实体识别
一、 系统配置 Eclipseluna、 JDK 1.8+ 二、分词介绍 使用斯坦福大学的分词器,下载地址http://nlp.stanford.edu/software/segmenter.shtml,从上面链接中下载stanford-segmenter-2014-10-26,解压之后,如下图所示 data目录下有两个gz压缩文件,分别是ctb.gz和pku.gz,其
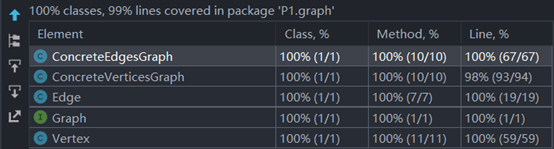
哈工大软件构造Lab2导读 - Stanford 6.031 Problem Set 2: Poetic Walks
文章目录 前言一、P1-Problem 1:编写测试用例1.GraphStaticTest2.GraphInstanceTest 二、实现两个ADT1.AF,RI,Safety from Rep exposure .etc2.checkRep ( )3.方法的具体实现4.实现Graph.empty ( ) 三、Poetic Walks1.题目意思梳理(结合MIT页面和spec看)2.编写测试