本文主要是介绍深度学习 --- stanford cs231学习笔记(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
stanford cs231学习笔记(一)
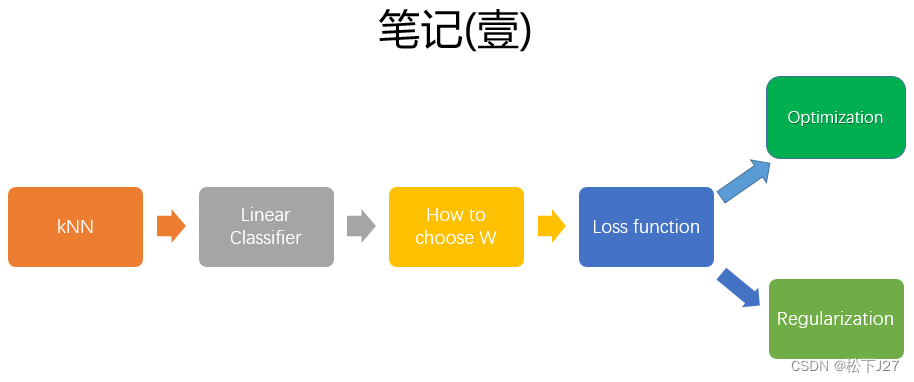
1,先是讲到了机器学习中的kNN算法,然后因为kNN分类器的一些弊端,引入了线性分类器。
kNN算法的三大弊端:
(1),计算量大,当特征比较多时表示性差
(2),训练时耗时少,且计算需求低,反而是对测试数据分类时,计算需求量大。
(3),衡量两幅图像之间的差异时,衡量方式单一,例如L1,L2距离。且仅有的这两种方法效果都不理想。
2,引入线性分类器

把图像的二维矩阵拉成一长条,变成一个向量x。对每个向量乘以一组权重系数W,得到一个分类的得分。也就是说,如果有10个类别的话,权重矩阵W就有10行。每行的权重系数对应了一个种类,比如说第一行对应的是猫的权重系数,那么第一行乘以x后,得到的值就是猫的得分。第二行是人,第二行乘以x后,就能得到对人的打分。依此类推,最终会得到10类的打分。

上图为一个简化模型,假设图像只有4个像素,且总共只有3个类别的打分结果。可以看得出,这个打分结果是错误的,Dog的得分最高。而cat反而得了最低分。
3,如何选择正确的W,才能让相应类别的图像打分最高而在其他类型的图像上打分低?答案就是损失函数Loss function,用于衡量正对当前所使用的W矩阵分类的打分结果,有多么的unhappy不满意。

3,1,损失函数有两种,一种是SVM loss(也叫hinge loss),分数越高表示越unhappy,即越不满意。

其中和
表示经过Wx计算后的分数向量score vector,根据这种方式计算后得到的结果分别是:



最终得到L函数的均值,对svm loss而言,分数越高,说明分类结果越不好。

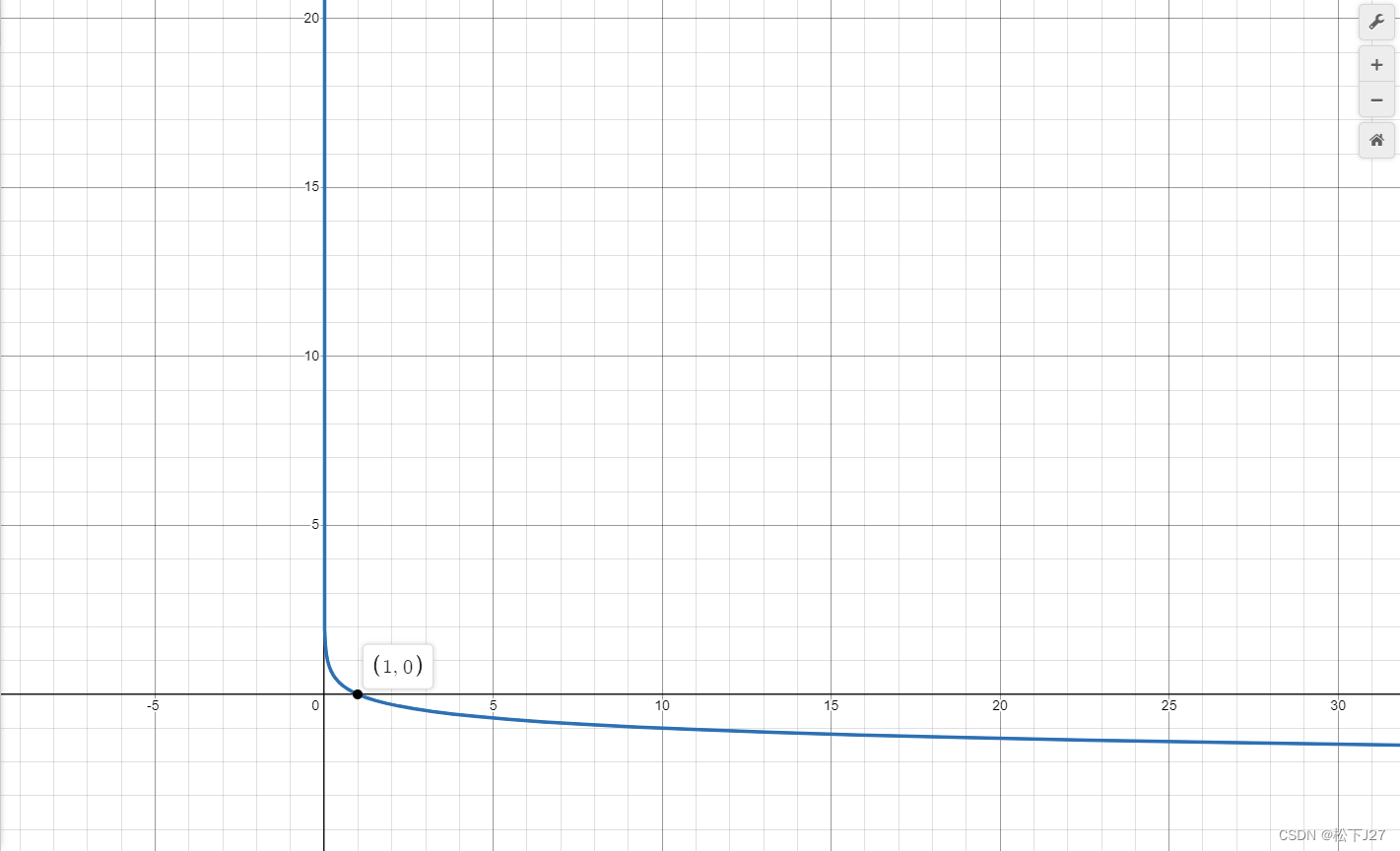
3,2,另一种损失函数叫softmax(也叫cross-entropy loss),他把分数转化成了概率函数,然后再对这个概率函数求了一个负自然对数。

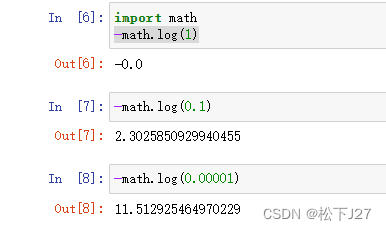
负自然对数函数的图像如下图所示,又因为概率函数的值域在0~1之间,因此,最终L函数的值域应该是在正无穷大到0之间。概率越低损失函数越大,概率越大,也就是越接近1,损失函数的值越接近0。

4,Loss function用于如何评估权重W的合理性,相当于是一个“体检指标”。指标高了,说明W有病了,如果指标越低,则说明W越健康。如何有效的利用Loss函数去优化W呢?这时optimization就出现了,也叫优化函数。
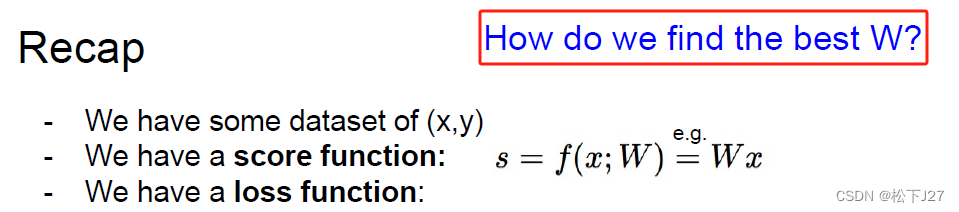
既然,我们的目标是让损失函数L最小化,我们就应该试着找到怎么改变W才能让L减小的最多。这里用到了求极限的概念,也就是通过让W增加一个很小的变化h,然后观察L值的变化。
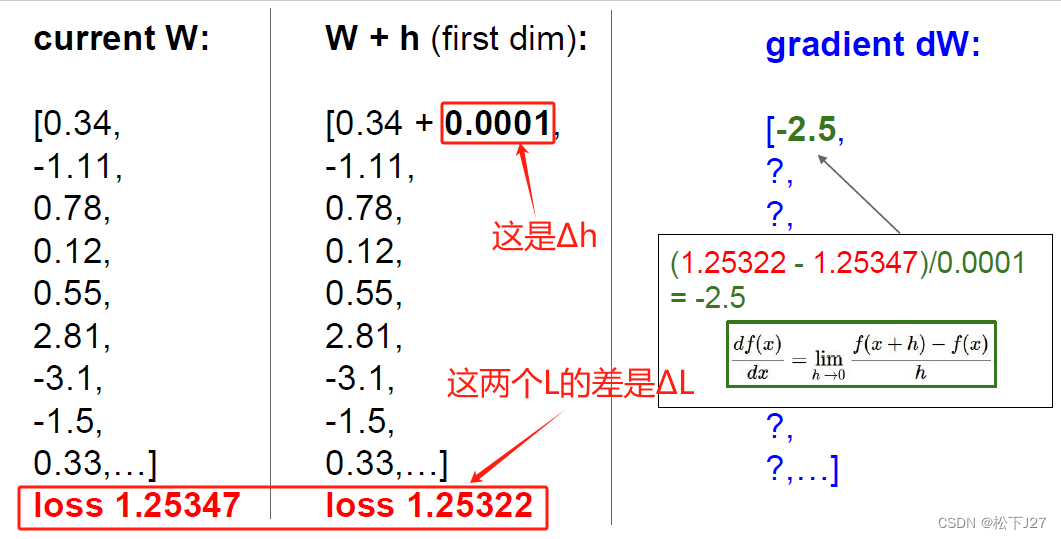
5,改变W后L的变化有可能变大,也有可能变小。而我们的目的是希望找到让L减小最快的W。这时,就引出了optimization优化。
常见的优化方式是梯度下降法,梯度下降法的原理是源于函数f在点P处的梯度一定是函数f在P点处的所有方向导数中增加最大的方向导数。因此,我们要想让函数f减小的最多,我们只需让自变量x沿着这一方向变化即可。

6,为了防止过拟合,在Loss函数中还可以加入Regularization正则化函数。

他能够使得拟合出来的函数尽可能的简单。

(全文完)
--- 作者,松下J27
参考文献(鸣谢):
1,Stanford University CS231n: Deep Learning for Computer Vision
2,https://zh.wikipedia.org/wiki/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B3%95
版权声明:所有的笔记,可能来自很多不同的网站和说明,在此没法一一列出,如有侵权,请告知,立即删除。欢迎大家转载,但是,如果有人引用或者COPY我的文章,必须在你的文章中注明你所使用的图片或者文字来自于我的文章,否则,侵权必究。 ----松下J27
这篇关于深度学习 --- stanford cs231学习笔记(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









