本文主要是介绍Keras深度学习框架实战(3):EfficientNet实现stanford dog分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、通过EfficientNet进行微调以实现图像分类概述
通过EfficientNet进行微调以实现图像分类,是一个使用EfficientNet作为预训练模型,并通过微调(fine-tuning)来适应特定图像分类任务的过程。一下是对相关重要术语的解释。
- EfficientNet:这是一个高效的卷积神经网络(CNN)架构,旨在通过统一缩放网络深度、宽度和分辨率等维度来优化性能和效率。EfficientNet有多个预训练的变体,如EfficientNet-B0到EfficientNet-B8,它们在多个图像分类任务上取得了很好的效果。
- 微调(Fine-tuning):在深度学习中,微调通常涉及使用预训练模型(如EfficientNet)的权重作为起点,并在特定数据集上进一步训练该模型。微调可以加速训练过程,因为它利用了预训练模型在大量数据上学到的通用特征。
- 图像分类:这是计算机视觉中的一个基本任务,涉及将输入图像分配给预定义的一组类别中的一个。例如,一个图像分类模型可能被训练来识别图像中的对象(如猫、狗、汽车等)或场景(如森林、海滩、城市等)。
1.1 EfficientNet简介
EfficientNet,最初由Tan和Le在2019年提出,是目前最高效的模型之一(即在ImageNet和常见的图像分类迁移学习任务上达到最先进的准确率时所需的浮点运算量(FLOPs)最少)。
最小的基本模型类似于MnasNet,后者通过显著更小的模型达到了接近最高水平的性能。通过引入一种启发式的方法来缩放模型,EfficientNet提供了一系列模型(B0到B7),这些模型在各种规模上代表了效率和准确性的良好组合。这种缩放启发式方法(复合缩放,详情参见Tan和Le,2019)允许以效率为导向的基本模型(B0)在每个尺度上超越其他模型,同时避免了广泛的超参数网格搜索。
模型的最新更新总结可以在这里找到,其中应用了各种增强方案和半监督学习方法来进一步提高模型在ImageNet上的性能。这些模型的扩展可以通过更新权重而无需改变模型架构来使用。
1.2 EfficientNet的B0到B7变体
(如果你只对使用这些模型感兴趣,可以跳过本节中关于“复合缩放”的详细解释)
基于原始论文,人们可能会认为EfficientNet是一个通过任意选择论文中Eq.(3)中的缩放因子来创建的连续模型家族。然而,分辨率、深度和宽度的选择也受到许多因素的限制:
分辨率:分辨率如果不能被8、16等整除,会导致某些层边界附近的零填充,从而浪费计算资源。这尤其适用于模型的较小变体,因此B0和B1的输入分辨率被选为224和240。
深度和宽度:EfficientNet的构建块要求通道大小是8的倍数。
资源限制:当深度和宽度可以继续增加时,内存限制可能会限制分辨率。在这种情况下,增加深度和/或宽度但保持分辨率仍然可以提高性能。
因此,EfficientNet模型的每个变体的深度、宽度和分辨率都是精心挑选的,并已被证明能产生良好的结果,尽管它们可能与复合缩放公式显著不同。因此,Keras实现(详细如下)仅提供这8个模型,B0到B7,而不是允许任意选择宽度/深度/分辨率参数。
1.3 Keras中的EfficientNet实现
自Keras v2.3起,已经内置了EfficientNet B0到B7的实现。要使用EfficientNetB0对ImageNet的1000类图像进行分类,可以运行:
from tensorflow.keras.applications import EfficientNetB0
model = EfficientNetB0(weights='imagenet')
这个模型接受形状为(224, 224, 3)的输入图像,输入数据的范围应该在[0, 255]之间。标准化是模型的一部分。
由于在ImageNet上训练EfficientNet需要大量的资源和一些不属于模型架构本身的技巧,因此Keras实现默认加载了通过AutoAugment训练获得的预训练权重。
对于B0到B7的基础模型,输入形状是不同的。以下是每个模型所需的输入形状列表:
以下是B0到B7基础模型的分辨率的表格翻译:
| 基础模型 | 分辨率 |
|---|---|
| EfficientNetB0 | 224 |
| EfficientNetB1 | 240 |
| EfficientNetB2 | 260 |
| EfficientNetB3 | 300 |
| EfficientNetB4 | 380 |
| EfficientNetB5 | 456 |
| EfficientNetB6 | 528 |
| EfficientNetB7 | 600 |
当模型用于迁移学习时,Keras实现提供了一个选项来移除顶层:
model = EfficientNetB0(include_top=False, weights='imagenet')
这个选项排除了最后一层的Dense层,该层将倒数第二层的1280个特征转化为对1000个ImageNet类别的预测。通过用自定义层替换顶层,可以在迁移学习的工作流程中将EfficientNet用作特征提取器。
在模型构造函数中另一个值得注意的参数是drop_connect_rate,它控制用于随机深度的dropout率。这个参数在微调时作为额外正则化的切换器,但不会影响已加载的权重。例如,当需要更强的正则化时,可以尝试:
model = EfficientNetB0(weights='imagenet', drop_connect_rate=0.4)
默认值为0.2 。
2、数据准备
本文将演示将EfficientNetB0用于斯坦福狗数据集。
EfficientNet能够处理广泛的图像分类任务。这使其成为迁移学习的良好模型。作为一个端到端的例子,我们将展示如何在斯坦福狗数据集上使用预训练的EfficientNetB0。
斯坦福狗数据集的下载地址如下:
http://vision.stanford.edu/aditya86/ImageNetDogs/
2.1 设置
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf # For tf.data
import matplotlib.pyplot as plt
import keras
from keras import layers
from keras.applications import EfficientNetB0# IMG_SIZE is determined by EfficientNet model choice
IMG_SIZE = 224
BATCH_SIZE = 64
2.2 加载数据
本文的演示从tensorflow_datasets(以下简称TFDS)加载数据。Stanford Dogs数据集在TFDS中作为stanford_dogs提供。它包含20,580张图像,这些图像属于120个狗品种类别(其中12,000张用于训练,8,580张用于测试)。
只需更改下面的dataset_name,您还可以尝试将此笔记本用于TFDS中的其他数据集,如cifar10、cifar100、food101等。当图像远小于EfficientNet的输入大小时,我们可以简单地对输入图像进行上采样。Tan和Le在2019年的研究表明,即使输入图像保持较小,增加分辨率的迁移学习结果也会更好。
dataset_name = "stanford_dogs"
(ds_train, ds_test), ds_info = tfds.load(dataset_name, split=["train", "test"], with_info=True, as_supervised=True
)
NUM_CLASSES = ds_info.features["label"].num_classes
当数据集包含各种大小的图像时,我们需要将它们调整为统一的大小。Stanford Dogs数据集仅包含至少200x200像素大小的图像。在这里,我们将图像调整为EfficientNet所需的输入大小。
ize = (IMG_SIZE, IMG_SIZE)
ds_train = ds_train.map(lambda image, label: (tf.image.resize(image, size), label))
ds_test = ds_test.map(lambda image, label: (tf.image.resize(image, size), label))
2.3 图像可视化
以下是展示前9张图像及其标签的代码:
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt# 加载Stanford Dogs数据集
dataset, info = tfds.load('stanford_dogs', with_info=True, split='train[:1%]') # 只加载一小部分数据进行可视化# 获取类别名称
class_names = info.features['label'].names# 从数据集中提取图像和标签
images, labels = next(iter(dataset.batch(9))).numpy()# 绘制图像
fig, axs = plt.subplots(3, 3, figsize=(12, 12))# 遍历前9个图像
for i, ax in enumerate(axs.flatten()):ax.imshow(images[i] / 255.0) # 归一化到[0, 1]范围ax.set_title(class_names[labels[i]])ax.axis('off')plt.show()
请注意,程序添加了.numpy()来从TensorFlow的数据集中提取NumPy数组,以便于绘图。程序还将图像归一化到[0, 1]的范围,因为matplotlib的imshow函数期望图像数据在这个范围内。此外,程序中使用了split='train[:1%]'来仅加载一小部分训练数据,以便快速可视化。如果程序员想要查看更多图像,可以更改这个切片操作来加载更多的数据。

2.4 数据增强
程序可以使用预处理层(preprocessing layers)API来进行图像增强。
在训练深度学习模型时,数据增强是一种常见的技术,它通过应用随机变换来增加训练数据的多样性,从而提高模型的泛化能力。在TensorFlow中,可以使用Keras的预处理层(preprocessing layers)API来实现各种图像增强技术,如随机旋转、裁剪、缩放、翻转等。这些增强操作可以在训练过程中实时应用于输入图像,以生成新的、变化多样的训练样本。
img_augmentation_layers = [layers.RandomRotation(factor=0.15),layers.RandomTranslation(height_factor=0.1, width_factor=0.1),layers.RandomFlip(),layers.RandomContrast(factor=0.1),
]def img_augmentation(images):for layer in img_augmentation_layers:images = layer(images)return images
这个Sequential模型对象既可以作为我们稍后构建的模型的一部分,也可以作为函数来预处理输入模型之前的数据。将它们用作函数可以方便地可视化给定图像的增强结果。在这里,程序绘制了给定图像经过增强后的9个示例结果。
这意味着程序员可以创建一个预处理序列(Sequential model),该序列定义了一系列图像增强步骤。然后,可以将这个预处理序列作为模型的一部分,也可以将其作为独立的函数来预处理图像,以便在将图像输入到模型之前进行可视化或检查。将增强步骤作为函数应用,程序员可以很容易地看到不同的增强效果是如何影响原始图像的。
for image, label in ds_train.take(1):for i in range(9):ax = plt.subplot(3, 3, i + 1)aug_img = img_augmentation(np.expand_dims(image.numpy(), axis=0))aug_img = np.array(aug_img)plt.imshow(aug_img[0].astype("uint8"))plt.title("{}".format(format_label(label)))plt.axis("off")

2.5 准备输入数据
一旦我们验证了输入数据和增强功能都工作正常,就准备训练用的数据集。输入数据会被调整到统一的大小(IMG_SIZE)。标签将被编码为独热(也称为分类)编码。数据集将被批量处理。
注意:在某些情况下,使用prefetch和AUTOTUNE可能会提高性能,但这取决于环境和所使用的具体数据集。请参阅这个指南以获取更多关于数据管道性能的信息。
在TensorFlow中,通常会使用tf.data API来准备数据,并利用诸如map, batch, prefetch, 和 shuffle等方法来提高数据处理效率。此外,当进行图像分类任务时,使用tf.keras.utils.to_categorical来将整数标签转换为独热编码也是很常见的做法。对于图像大小调整,可以使用tf.image.resize函数。
# One-hot / categorical encoding
def input_preprocess_train(image, label):image = img_augmentation(image)label = tf.one_hot(label, NUM_CLASSES)return image, labeldef input_preprocess_test(image, label):label = tf.one_hot(label, NUM_CLASSES)return image, labelds_train = ds_train.map(input_preprocess_train, num_parallel_calls=tf.data.AUTOTUNE)
ds_train = ds_train.batch(batch_size=BATCH_SIZE, drop_remainder=True)
ds_train = ds_train.prefetch(tf.data.AUTOTUNE)ds_test = ds_test.map(input_preprocess_test, num_parallel_calls=tf.data.AUTOTUNE)
ds_test = ds_test.batch(batch_size=BATCH_SIZE, drop_remainder=True)
3、从零开始进行模型训练
我们从头开始构建一个具有120个输出类别的EfficientNetB0模型:
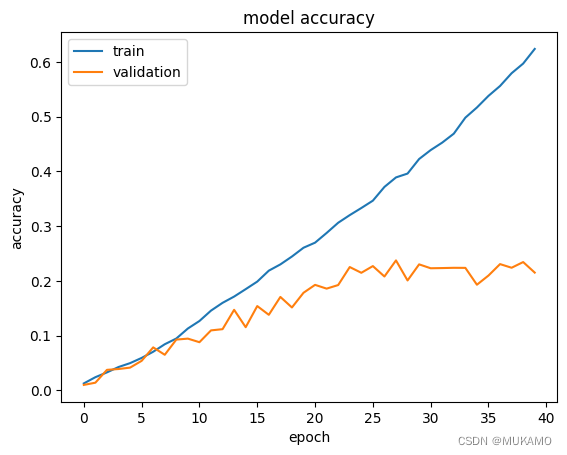
注意:准确率会增长得非常慢,并且可能会出现过拟合。
EfficientNet是一种预训练的深度学习模型架构,它在多个图像分类任务上都取得了很好的效果。然而,当从头开始训练EfficientNet模型时,由于需要从头学习所有参数,因此训练过程可能会相对较长,并且可能会因为训练数据不足而出现过拟合现象。为了缓解这个问题,可以使用数据增强、正则化技术(如Dropout、L2正则化等)和早停(early stopping)等方法来减少过拟合的风险。同时,也可以使用预训练的EfficientNet模型作为特征提取器,并在此基础上进行微调(fine-tuning),以加快训练速度并提高模型的性能。
model = EfficientNetB0(include_top=True,weights=None,classes=NUM_CLASSES,input_shape=(IMG_SIZE, IMG_SIZE, 3),
)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])model.summary()epochs = 40 # @param {type: "slider", min:10, max:100}
hist = model.fit(ds_train, epochs=epochs, validation_data=ds_test)
以下表格包含了模型的所有层:
| Layer (type) | Output Shape | Param # | Connected to |
|---|---|---|---|
| input_layer | (None, 224, 224, 3) | 0 | - |
| Rescaling | (None, 224, 224, 3) | 0 | input_layer[0][0] |
| Normalization | (None, 224, 224, 3) | 7 | rescaling[0][0] |
| stem_conv_pad | (None, 225, 225, 3) | 0 | normalization[0][0] |
| stem_conv (Conv2D) | (None, 112, 112, 32) | 864 | stem_conv_pad[0][0] |
| stem_bn | (None, 112, 112, 32) | 128 | stem_conv[0][0] |
| stem_activation | (None, 112, 112, 32) | 0 | stem_bn[0][0] |
| block1a_dwconv | (None, 112, 112, 32) | 288 | stem_activation[0][0] |
| block1a_bn | (None, 112, 112, 32) | 128 | block1a_dwconv[0][0] |
| block1a_activation | (None, 112, 112, 32) | 0 | block1a_bn[0][0] |
| … | … | … | … |
| block6c_add (Add) | (None, 7, 7, 192) | 0 | block6c_drop[0][0], block6b_add[0][0] |
| block6d_expand_conv | (None, 7, 7, 1152) | 221,184 | block6c_add[0][0] |
| block6d_expand_bn | (None, 7, 7, 1152) | 4,608 | block6d_expand_conv[0][0] |
| block6d_expand_activation | (None, 7, 7, 1152) | 0 | block6d_expand_bn[0][0] |
| block6d_dwconv | (None, 7, 7, 1152) | 28,800 | block6d_expand_activation[0][0] |
| block6d_bn | (None, 7, 7, 1152) | 4,608 | block6d_dwconv[0][0] |
| block6d_activation | (None, 7, 7, 1152) | 0 | block6d_bn[0][0] |
| block6d_se_squeeze | (None, 1152) | 0 | block6d_activation[0][0] |
| block6d_se_reshape | (None, 1, 1, 1152) | 0 | block6d_se_squeeze[0][0] |
| block6d_se_reduce | (None, 1, 1, 48) | 55,344 | block6d_se_reshape[0][0] |
| block6d_se_expand | (None, 1, 1, 1152) | 56,448 | block6d_se_reduce[0][0] |
| block6d_se_excite | (None, 7, 7, 1152) | 0 | block6d_activation[0][0], block6d_se_expand[0][0] |
| block6d_project_conv | (None, 7, 7, 192) | 221,184 | block6d_se_excite[0][0] |
| block6d_project_bn | (None, 7, 7, 192) | 768 | block6d_project_conv[0][0] |
| block6d_drop | (None, 7, 7, 192) | 0 | block6d_project_bn[0][0] |
| block6d_add (Add) | (None, 7, 7, 192) | 0 | block6d_drop[0][0], block6c_add[0][0] |
| block7a_expand_conv | (None, 7, 7, 1152) | 221,184 | block6d_add[0][0] |
| block7a_expand_bn | (None, 7, 7, 1152) | 4,608 | block7a_expand_conv[0][0] |
| block7a_expand_activation | (None, 7, 7, 1152) | 0 | block7a_expand_bn[0][0] |
| block7a_dwconv | (None, 7, 7, 1152) | 10,368 | block7a_expand_activation[0][0] |
| block7a_bn | (None, 7, 7, 1152) | 4,608 | block7a_dwconv[0][0] |
| block7a_activation | (None, 7, 7, 1152) | 0 | block7a_bn[0][0] |
| block7a_se_squeeze | (None, 1152) | 0 | block7a_activation[0][0] |
| block7a_se_reshape | (None, 1, 1, 1152) | 0 | block7a_se_squeeze[0][0] |
| block7a_se_reduce | (None, 1, 1, 48) | 55,344 | block7a_se_reshape[0][0] |
| block7a_se_expand | (None, 1, 1, 1152) | 56,448 | block7a_se_reduce[0][0] |
| block7a_se_excite | (None, 7, 7, 1152) | 0 | block7a_activation[0][0], block7a_se_expand[0][0] |
| block7a_project_conv | (None, 7, 7, 320) | 368,640 | block7a_se_excite[0][0] |
| block7a_project_bn | (None, 7, 7, 320) | 1,280 | block7a_project_conv[0][0] |
| top_conv (Conv2D) | (None, 7, 7, 1280) | 409,600 | block7a_project_bn[0][0] |
| top_bn | (None, 7, 7, 1280) | 5,120 | top_conv[0][0] |
| top_activation | (None, 7, 7, 1280) | 0 | top_bn[0][0] |
| avg_pool (GlobalAveragePooling2D) | (None, 1280) | 0 | top_activation[0][0] |
| top_dropout | (None, 1280) | 0 | avg_pool[0][0] |
| predictions (Dense) | (None, 120) | 153,720 | top_dropout[0][0] |
请注意,"…" 表示中间层已被省略,以避免冗长。如果需要中间层的详细信息,请告知我,我将提供完整的数据。
import matplotlib.pyplot as plt训练模型的速度相对较快。这可能让人误以为可以轻松地从头开始在任何想要的数据集上训练EfficientNet。然而,在较小的数据集上训练EfficientNet,尤其是像CIFAR-100这样分辨率较低的数据集,会面临过拟合的重大挑战。因此,从头开始训练需要非常谨慎地选择超参数,并且很难找到合适的正则化方法。这也会在资源上提出更高的要求。绘制训练和验证准确率图表可以清楚地看到,验证准确率停滞在一个较低的值上。这段文字主要强调了从头开始训练EfficientNet模型可能面临的挑战,包括过拟合问题、超参数选择的难度以及资源需求的增加。同时,通过绘制训练和验证准确率图表,可以直观地看到模型在验证集上的表现并不理想,准确率提升有限。
def plot_hist(hist):plt.plot(hist.history["accuracy"])plt.plot(hist.history["val_accuracy"])plt.title("model accuracy")plt.ylabel("accuracy")plt.xlabel("epoch")plt.legend(["train", "validation"], loc="upper left")plt.show()plot_hist(hist)
4、从预训练权重进行迁移学习
为改善第三节从零开始训练模型的不足,在这里,我们使用在ImageNet上预训练的权重来初始化模型,并在我们自己的数据集上对其进行微调。
def build_model(num_classes):inputs = layers.Input(shape=(IMG_SIZE, IMG_SIZE, 3))model = EfficientNetB0(include_top=False, input_tensor=inputs, weights="imagenet")# Freeze the pretrained weightsmodel.trainable = False# Rebuild topx = layers.GlobalAveragePooling2D(name="avg_pool")(model.output)x = layers.BatchNormalization()(x)top_dropout_rate = 0.2x = layers.Dropout(top_dropout_rate, name="top_dropout")(x)outputs = layers.Dense(num_classes, activation="softmax", name="pred")(x)# Compilemodel = keras.Model(inputs, outputs, name="EfficientNet")optimizer = keras.optimizers.Adam(learning_rate=1e-2)model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])return model
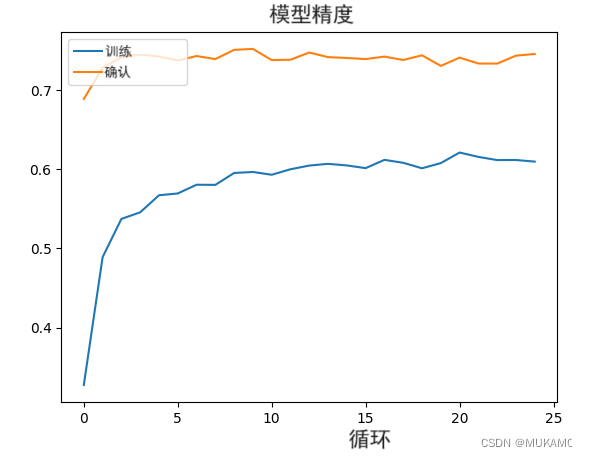
4.1 训练顶层
迁移学习的第一步是冻结所有层并仅训练顶层。在这一步中,可以使用相对较大的学习率(如1e-2)。请注意,验证准确率和损失通常会比训练准确率和损失要好。这是因为正则化很强,它只会抑制训练时的指标。
请注意,收敛可能需要多达50个epoch,具体取决于所选的学习率。如果未应用图像增强层,验证准确率可能只能达到约60%。
model = build_model(num_classes=NUM_CLASSES)epochs = 25 # @param {type: "slider", min:8, max:80}
hist = model.fit(ds_train, epochs=epochs, validation_data=ds_test)
plot_hist(hist)
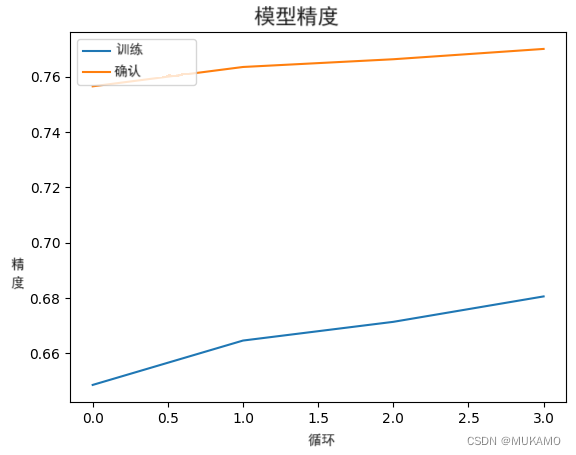
4.2 解冻其它层
第二步是解冻一定数量的层并使用较小的学习率来训练模型。在这个例子中,我们展示了如何解冻所有层,但具体取决于数据集,可能只解冻所有层的一部分会更合适。
当使用预训练模型进行特征提取的效果足够好时,这一步在验证准确率上的提升会非常有限。在我们的例子中,我们只看到了很小的提升,因为ImageNet预训练已经让模型接触到了大量的狗的图片。
另一方面,当我们在与ImageNet差异更大的数据集上使用预训练权重时,这个微调步骤可能至关重要,因为特征提取器也需要做出相当大的调整。如果选择CIFAR-100数据集作为例子,这种情况可以得到体现,其中微调可以将EfficientNetB0的验证准确率提升约10%,达到80%以上。
关于模型冻结/解冻的一个旁注:设置模型的trainable属性将同时设置该模型所属的所有层的trainable属性。只有当层本身和包含它的模型都是可训练的,该层才是可训练的。因此,当我们需要部分冻结/解冻一个模型时,我们需要确保模型的trainable属性被设置为True。
def unfreeze_model(model):# We unfreeze the top 20 layers while leaving BatchNorm layers frozenfor layer in model.layers[-20:]:if not isinstance(layer, layers.BatchNormalization):layer.trainable = Trueoptimizer = keras.optimizers.Adam(learning_rate=1e-5)model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])unfreeze_model(model)epochs = 4 # @param {type: "slider", min:4, max:10}
hist = model.fit(ds_train, epochs=epochs, validation_data=ds_test)
plot_hist(hist)
4.3 微调EfficientNet要点
在解冻层时:
-
BatchNormalization层需要保持冻结(更多细节)。如果它们也被设置为可训练的,解冻后的第一个epoch将显著降低准确率。
-
在某些情况下,只解冻部分层而不是全部层可能更有益。当使用更大的模型如B7时,这样做将大大加快微调过程。
-
每个块需要全部打开或关闭。这是因为架构包括从每个块的第一层到最后一层的快捷连接。不尊重块也会显著损害最终性能。
利用EfficientNet的其他提示:
-
EfficientNet的较大变体并不保证性能的提升,特别是对于数据量较少或类别较少的任务。在这种情况下,选择的EfficientNet变体越大,调整超参数就越困难。
-
**EMA(指数移动平均)**在从头开始训练EfficientNet时非常有用,但在迁移学习中帮助不大。
-
不要使用原始论文中的RMSprop设置进行迁移学习。迁移学习中的动量和学习率太高。它很容易破坏预训练权重并使损失爆炸。一个简单的检查方法是看同一epoch后损失(作为分类交叉熵)是否显著大于log(NUM_CLASSES)。如果是,那么初始学习率/动量太高。
-
较小的批处理大小有利于验证准确率,可能是因为有效地提供了正则化。
5、总结
今天我们对EfficientNet进行了深入的讨论,以下是对讨论的总结:
EfficientNet概述
EfficientNet是一个高效且可扩展的卷积神经网络模型家族,它通过系统地平衡网络深度、宽度和分辨率,以较小的模型尺寸实现了出色的性能。EfficientNet模型在多个基准测试中均取得了显著的性能提升,包括ImageNet分类、CIFAR-100分类以及COCO目标检测等。
EfficientNet的特点
-
系统平衡:EfficientNet通过一种复合缩放方法,同时缩放网络的深度、宽度和分辨率,以在给定计算资源下实现最佳性能。
-
高效性:EfficientNet使用了MobileNetV2中的MBConv(Mobile inverted bottleneck convolution)作为其构建块,结合了深度可分离卷积和Squeeze-and-Excitation模块,从而实现了高效计算和参数利用。
-
可扩展性:EfficientNet具有多个不同规模的变体,包括EfficientNetB0到EfficientNetB8,这些变体在模型大小和性能之间提供了灵活的权衡。
迁移学习与微调EfficientNet
-
冻结与解冻层:在迁移学习中,首先冻结所有层并仅训练顶层是一种常见做法。随着训练的进行,可以逐步解冻更多层以进行微调。然而,需要注意的是,在解冻过程中,BatchNormalization层应保持冻结以避免性能下降。
-
学习率调整:在微调过程中,学习率的选择至关重要。初始阶段可以使用较大的学习率以加速训练,但随后应逐渐减小学习率以进行更精细的调整。
-
数据增强:在迁移学习中,数据增强对于提高模型的泛化能力非常重要。通过使用如随机裁剪、翻转、旋转等数据增强技术,可以增加模型的鲁棒性。
使用EfficientNet的注意事项
-
模型大小与任务匹配:较大的EfficientNet变体并不总是能保证更好的性能,特别是在数据较少或类别较少的任务中。因此,在选择模型时,需要根据具体任务和数据集来权衡模型大小和性能。
-
优化器与学习率设置:对于迁移学习任务,不建议使用原始论文中的RMSprop优化器和较高的学习率。相反,使用更稳定的优化器(如Adam或SGD)和较低的学习率通常更为合适。
-
正则化技术:在微调过程中,可以考虑使用正则化技术(如Dropout、Weight Decay等)来防止过拟合。这些技术可以帮助模型在训练过程中更好地泛化到未见过的数据。
EfficientNet是一个强大且灵活的卷积神经网络模型家族,适用于各种计算机视觉任务。通过合理的迁移学习策略和微调技巧,可以充分发挥EfficientNet的性能优势。
这篇关于Keras深度学习框架实战(3):EfficientNet实现stanford dog分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





