mfcc专题

语音特征提取方法 (二)MFCC
下面总结的是第四个知识点:MFCC。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。 在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。 搞清语音是怎么产生的对于我们理解语音有很大
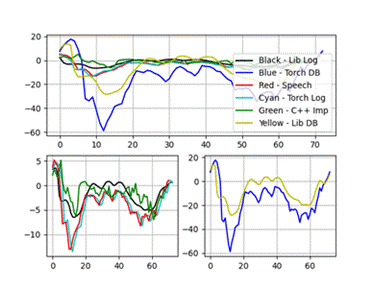
MFCC C++实现与Python库可视化对比
MFCC C++实现与Python库对比 MFCC理论基础 在音频、语音信号处理领域,我们需要将信号转换成对应的语谱图(spectrogram),将语谱图上的数据作为信号的特征。语谱图的横轴x为时间,纵轴y为频率,(x,y)对应的数值代表在时间x时频率y的幅值。通常的语谱图其频率是线性分布的,但是人耳对频率的感受是对数的(logarithmic),即对低频段的变化敏感,对高频段的变化迟钝,所以

C++调用Python和numpy第三方库计算MFCC音频特征实现封装发布
文章目录 项目简介环境准备执行步骤1.新建python虚拟环境2.虚拟环境运行下python代码3.迁移虚拟环境4.编写Cmakelists.txt5.编写C++代码6.编译项目7.测试 项目简介 深度学习程序的边缘部署以性能绝佳的C++为主(⊙﹏⊙),但遇到项目开发周期短,则以功能优先,一些复杂的算法和处理用C++写怕不是得写到天荒地老,于是C++调用python以及第三方

ASR-MFCC特征的物理意义
文章目录 一.MFCC简介二.MFCC特征提取过程三.MFCC的物理含义 一.MFCC简介 梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,简称MFCC)是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示: 式中f为频率,单位为Hz。下图展示了Mel频率与线性频率的关系
MFCC(梅尔倒频谱系数)总结
看了很多MFCC的资料,经常过一段时间就忘了。现在总结一下其中的要点,便于今后翻看。 MFCC(梅尔倒频谱系数)是在1980年由Davis和Mermelstein搞出来的。MFCC是一种人工(hand crafted)特征,可以用于语音识别等。当年在语音领域取得了重大的成就,后来出现了深度学习,这种deep learned特征就是另一说了。虽然现在深度学习如日中天,也取得了非常好的效果,但是MF

语音信号处理(2):文本相关的声纹识别系统(MFCC、VQ)
本文基于Matlab设计实现了一个文本相关的声纹识别系统,可以判定说话人身份。简单理解即为一个声纹锁(类似指纹锁)。整个系统的源代码,可以从这里下载:【基于Matlab的声纹锁】 系统原理 a.声纹识别 这两年随着人工智能的发展,不少手机App都推出了声纹锁的功能。这里面所采用的主要就是声纹识别相关的技术。声纹识别又叫说话人识别,它和语音识别存在一点差别。

基于语音信号MFCC特征提取和GRNN神经网络的人员身份检测算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 MFCC特征提取 4.2 GRNN神经网络概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 MATLAB2022a 3.部分核心程序 .................................................

如何利用kaldi提自己想要的特征(mfcc plp pitch)
群里的@卡丁王一直想用kaldi提自己想要的特征,但是他老是出现错误。我自己试验下,下面是具体流程,希望你有所收获。 首先,确保你的s5文件夹有conf local step utils文件夹。然后你把你的数据保存为test文件夹,比如test文件夹里有test1.wav test2.wav test3.wav。 然后,新建个data文件夹,data文件夹新建个test文件夹,这个test

语音识别--基于MFCC和多层感知机的语音情感识别
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟 🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿 个人网站:https://jerry-jy.co/ ❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我 语音识别--基于MFCC和多层感知机的语音情感识别 基于MFCC和多
python使用隐马尔可夫模型识别波形数据MFCC特征
python使用隐马尔可夫模型识别振动波形数据MFCC特征 1、简介 隐马尔可夫模型非常擅长对时间序列数据进行建模。 由于振动波形数据是时间序列信号,HMM能够满足波形分类需求。 隐马尔可夫模型是表示观察序列的概率分布的模型。假设输出是由隐藏状态生成的。 2、数据预处理 假设已经有做FIR处理的波形数据存放在MySQL数据库中,存放的格式是一维数组,可以通过python

基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(三)
目录 前言引言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建1)定义模型结构2)优化损失函数 3. 模型训练及保存1)模型训练2)模型保存3)映射保存 相关其它博客工程源代码下载其它资料下载 前言 博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰
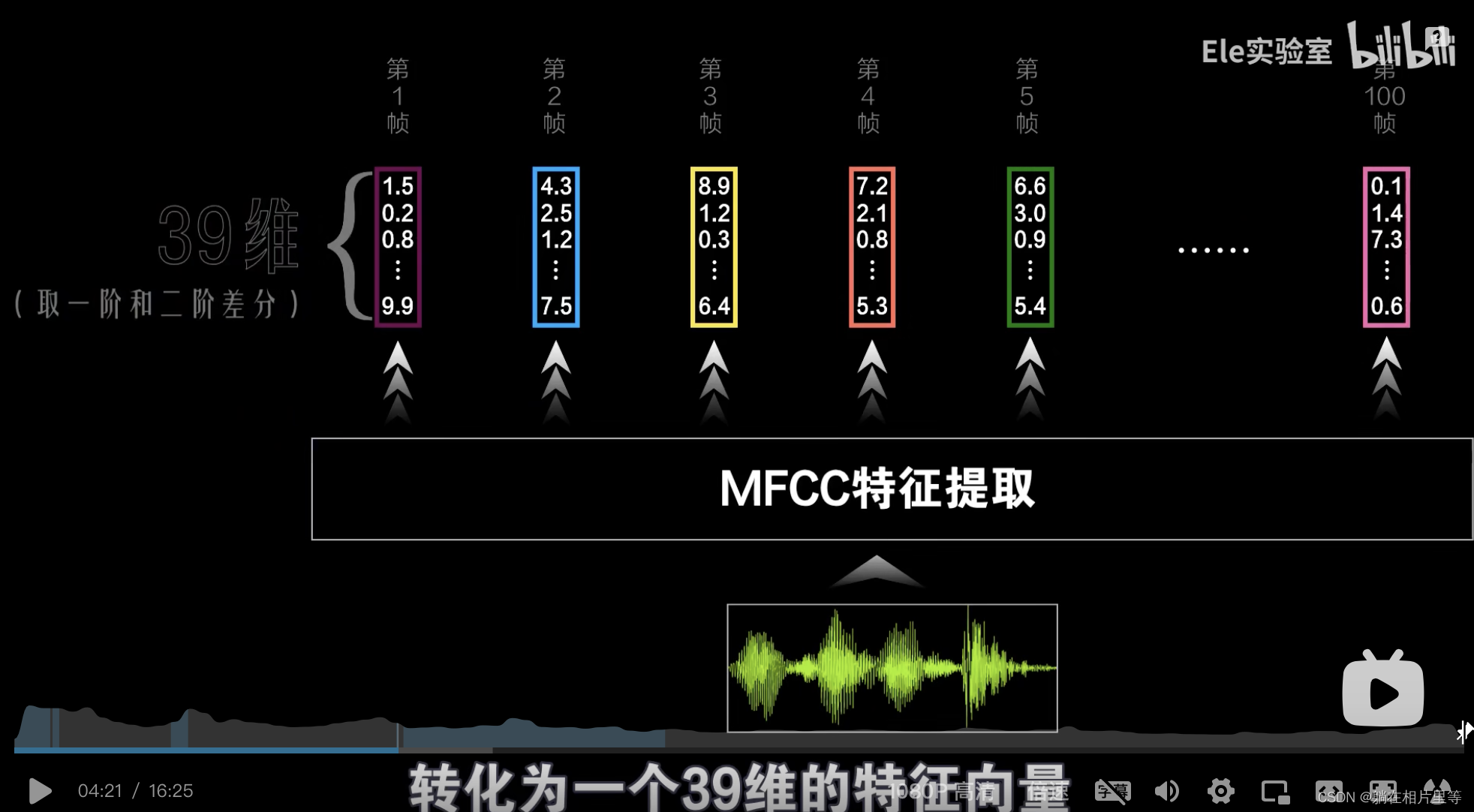
语音识别中MFCC频谱和如何得到频谱图的图示讲解
关于语音识别 音乐识别中 MFCC频谱图如何得到的 最详细的视频 视频链接放在这里,求求你们愿意打开视频的话,就看一眼吧···是在b站上的 要是我入门的时候看到这个视频真的是幸福死了. 😃😃 链接: link 本来不想写关于模数转换、采样、傅立叶变换这些的,但还是记录一下吧。我是一下子get到了这个MFCC图是怎么来的,如果你已经知道了如何分帧,加窗,如何得到整个MFCC频谱图只需要直接看下面
基于MFCC和SVM的语音、音乐 、情感声音的分类预测和鉴别识别方法
图 原始的输入界面 图 进行卷积方法去噪声的代码 SVM的语音分析和识别的研究 可以录制原始的声音,然后采取卷积的方法进行去噪声,进而可以提取mfcc的特征, 通过svm的方法进行分类得到类别, Mfcc的特征提取需要进行提取有关内容 采取别的语音的时候的结果 得到了特

梅尔倒谱系数MFCC由浅入深(超详细)
MFCC梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients) 在语音识别(Speech Recognition)和话者识别(Speaker Recognition)方面,最常用到的语音特征就是梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,简称MFCC)。根据人耳听觉机理的研究发现,人耳对不同频率的声
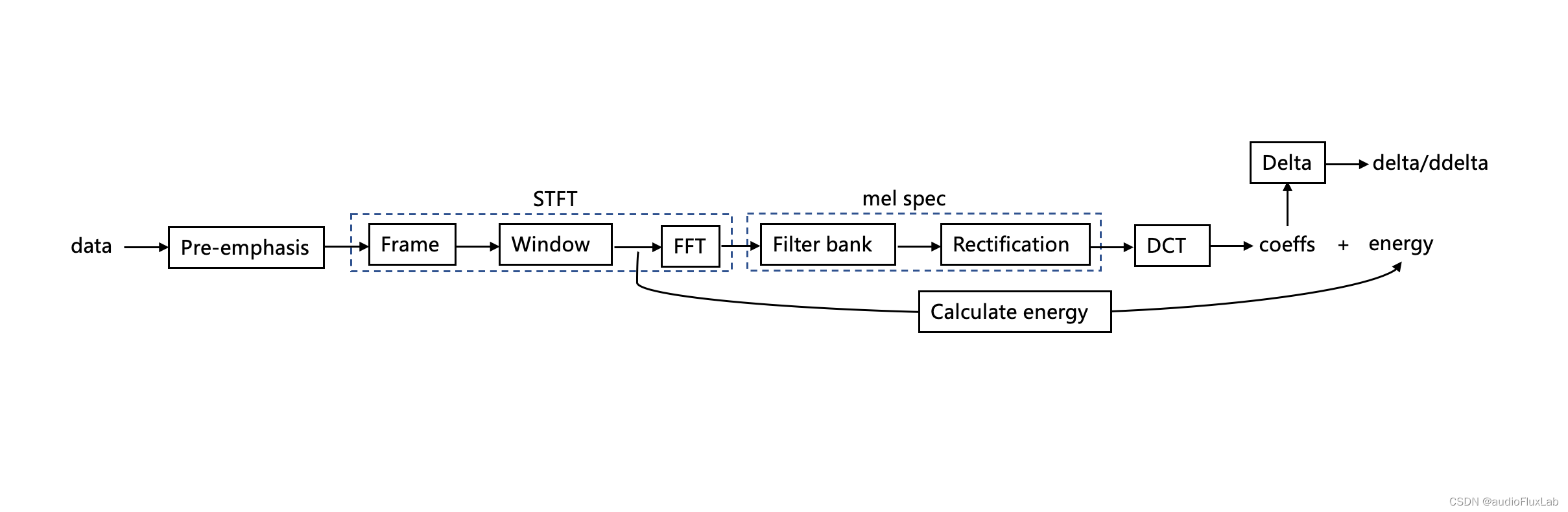
Mel频谱和MFCC深入浅出
目录 前言算法流程1. 预加重(Pre-emphasis)2. 分帧(Frame)3. 加窗(Window)4. 短时傅里叶变换(STFT)5. 滤波器组过程(Filter bank)6. 非线性校正(Rectification)7. 离散余弦变换(DCT)8. 能量和delta 相关细节1. weight-A计权2. overlap重叠3. window窗函数4. rectificati
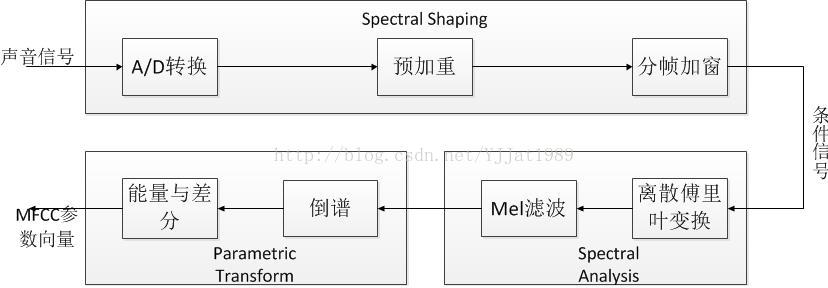
声音特征提取 MFCC向量
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好的代表声音的特征,因此,必须将声音波形转换为声学特征向量。目前有许多声音特征提取方法,如梅尔频率倒谱系数MFCC、线性预测倒谱系数LPCC、多媒体内容描述接口MPEG7等,其中MFCC是基于倒谱的,更符合人的听觉原理,因而是最普遍、最有效的声音特征提取算法。在提取MFCC前,需要对声音
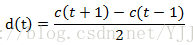
声音特征提取:MFCC向量
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好的代表声音的特征,因此,必须将声音波形转换为声学特征向量。目前有许多声音特征提取方法,如梅尔频率倒谱系数MFCC、线性预测倒谱系数LPCC、多媒体内容描述接口MPEG7等,其中MFCC是基于倒谱的,更符合人的听觉原理,因而是最普遍、最有效的声音特征提取算法。在提取MFCC前,需要对声音做前期处理,包括模数转换、预加重和加窗。

语谱图(五) Mel_语谱图之MFCC系数(上)
搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的shape(形状?)决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。声道的形状在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。 也就是说MFCC 最初的出现,是为了描述音频信号短时功率谱
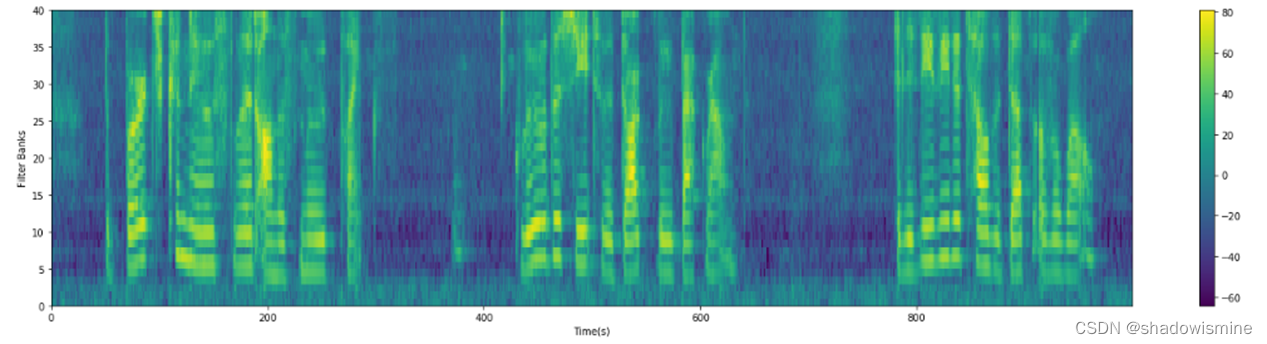
Fbank及MFCC学习
Fbank:FilterBank:人耳对声音频谱的响应是非线性的,Fbank就是一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。获得语音信号的fbank特征的一般步骤是:预加重、分帧、加窗、短时傅里叶变换(STFT)、mel滤波、去均值等。对fbank做离散余弦变换(DCT)即可获得mfcc特征。 MFCC(Mel-frequency cepstral coeffic
Python实现RNN算法对MFCC特征的简单语音识别
Python实现RNN算法对MFCC特征的简单语音识别 1、实现步骤 借助深度学习库 TensorFlow/Keras 来构建模型 1.对标签进行编码,将文本标签转换为整数标签。 2.对 MFCC 特征数据进行填充或截断,使其长度一致,以便于输入到 RNN 模型中 3.如果是二维数据需要转成三维: SimpleRNN输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数
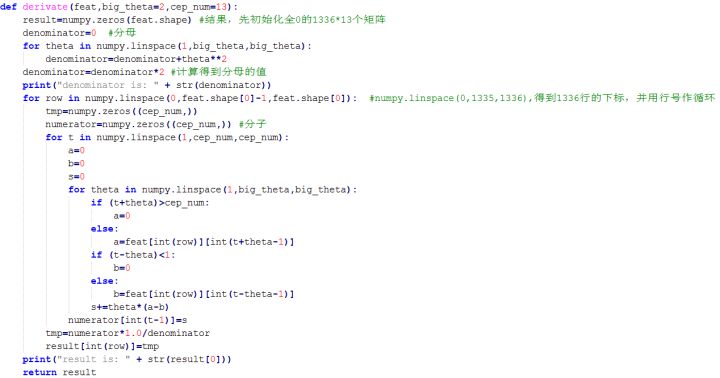
MFCC特征参数提取
记忆力不好,做个随笔,怕以后忘记。 网上很多关于MFCC提取的文章,但本文纯粹我自己手码,本来不想写的,但这东西忘记的快,所以记录我自己看一个python demo并且自己本地debug的过程,在此把这个demo的步骤记下来,所以文章主要倾向说怎么做,而不是道理论述。由于python的matplotlib.pyplot库没有下载成功不会画图,文中大部分图片是我网上找的。 必备基础知知识: