knn专题

openCV中KNN算法的实现
《openCV中KNN算法的实现》KNN算法是一种简单且常用的分类算法,本文主要介绍了openCV中KNN算法的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的... 目录KNN算法流程使用OpenCV实现KNNOpenCV 是一个开源的跨平台计算机视觉库,它提供了各

机器学习--KNN算法
knn算法针对有监督学习,分为2种:聚类和回归 第1种:聚类 #导包(聚类)from sklearn.neighbors import KNeighborsClassifier#构建数据x = [[3],[6],[8]]y=[3,7,6]#实例化模型knn=KNeighborsClassifier(n_neighbors=1)#训练knn.fit(x,y)#预测print(

KNN-机器学习实战系列(一)
开门见山,本文单说KNN: 作为机器学习实战书籍介绍的第一个算法,有一些值得说道的地方: 1:什么是KNN? 机器学习的一些基本知识和概念不加叙述了,直接给出KNN的白话定义:给定M个样本,每个样本均有N个数字衡量的属性,而每个样本均带有自身的标签: 这里,为什么需要数字化定义属性呢?这方便了我们衡量指标的计算,我们可以使用距离这一可用数学表达式实现的概念,来阐述何谓近邻。 而KNN,英
【HDU】5021 Revenge of kNN II 树状数组
传送门:【HDU】5021 Revenge of kNN II 题目分析:【HDU】4995 Revenge of kNN的升级版,这次取消的K<=10的限制。 但是依旧可以做! 首先我们将点按照横坐标从小到大排序,然后对于每次查询,我们先二分距离mid,然后再二分查找在X-mid,X+mid里面有多少数,如果小于K则抬升下界,如果大于K+1则降低上界,如果等于K则直接更新,还有就是正

机器学习项目——基于机器学习(决策树 随机森林 朴素贝叶斯 SVM KNN XGBoost)的帕金森脑电特征识别研究(代码/报告材料)
完整的论文代码见文章末尾 以下为核心内容和部分结果 问题背景 帕金森病(Parkinson’s Disease, PD)是一种常见的神经退行性疾病,其主要特征是中枢神经系统的多巴胺能神经元逐渐丧失,导致患者出现运动障碍、震颤、僵硬等症状。然而,除运动症状外,帕金森病患者还常常伴有一系列非运动症状,其中睡眠障碍是最为显著的非运动症状之一。 脑电图(Electroencephalogram, E
k近邻(kNN)算法的Python实现(基于欧氏距离)
k近邻算法是机器学习中原理最简单的算法之一,其思想为:给定测试样本,计算出距离其最近的k个训练样本,将这k个样本中出现类别最多的标记作为该测试样本的预测标记。 k近邻算法虽然原理简单,但是其泛华错误率却不超过贝叶斯最有分类器错误率的两倍。所以实际应用中,k近邻算法是一个“性价比”很高的分类工具。 基于欧式距离,用Python3.5实现kNN算法: 主程序: from numpy impor

KNN分类器-Java实现
KNN,即K近邻算法。其基本思想或者说是实现步骤如下: (1)计算样本数据点到每个已知类别的数据集中点的距离 (2)将(1)中得到的距离按递增顺序排列 (3)选取(2)中前K个点(即与当前样本距离最小的K个已知类别的数据点) (4)统计(3)中得到的K个点所在类别的出现频率 (5)返回(4)中出现频率最高的类别作为样本点的预测类别 在给出具体实现代码之前,说明一点:Java下的矩阵操作
python K-Nearest Neighbor KNN算法
1、最初的邻近算法,分类算法,基于实例的学习,懒惰学习。 2、算法步骤: a、为了判断未知实例类别,选择所有已知的实例作为参考 b,选择参数k c,计算未知实例和所有已知实例的距离 d,选择最近k个已知实例 e,根据少数服从多数,让未知实例归类为k个中最多的类别 公式:E(x,y)=(xi-yi)^2求和之后再开方 import mathdef ComputeEuclidean

【机器学习】K近邻(K-Nearest Neighbors,简称KNN)的基本概念以及消极方法和积极方法的区别
引言 K近邻(K-Nearest Neighbors,简称KNN)算法是一种基础的机器学习方法,属于监督学习范畴 文章目录 引言一、K近邻(K-Nearest Neighbors,简称KNN)1.1 原理详述1.1.1 距离度量1.1.2 选择k值1.1.3 投票机制 1.2 实现步骤1.3 参数选择1.4 应用场景1.5 优缺点1.5.1 优点1.5.2 缺点 1.6 k-近邻代
ES 近一年新版本,关于knn的新功能与优化
近一年,es发布了很多个版本。本文,主要整理了es关于knn搜索相关的优化项。 也放了官方文档的链接。 8.8 版本 What’s new in 8.8 | Elasticsearch Guide [8.8] | Elastic Reciprocal Rank Fusion (RRF) 改添加了倒数排名融合 (RRF),它遵循将结果集合并在一起的基本公式,sum(1/(k+
最近邻算法(KNN)
【算法分析】 KNN是本次实验第一个需要实现的方法,不算太难,但是要求是k=1,或者代码中根据测试集来自动识别最好的k值。本次实现只是采用了k=1的情况。 何谓K近邻算法,即K-NearestNeighbor algorithm,简称KNN算法, K个最近的邻居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。也即是给定一个训练数据集,对新的输入实例(或者说是给定的数据集),在训练数据


Elasticsearch向量检索(KNN)千万级耗时长问题分析与优化方案
最终效果 本文分享,ES千万级向量检索耗时分钟级的慢查询分析方法,并分享优化方案。通过借助内存加速,把查询延迟从分钟级降低到毫秒级别。 方案缺点是对服务器内存有比较大的依赖! 主要问题:剔除knn插件,此插件在做ANN检索时,构建查询语句耗时长。 1.背景 1.1 资源背景 es.8.8版本 2个es节点 ; 堆内存31g; 服务器内存资源充足(100+); HDD磁盘 该优化是在
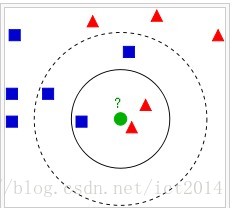
k近邻分类算法(kNN)
注明:部分内容来自维基百科 In pattern recognition, the k-Nearest Neighbors algorithm (ork-NN for short) is anon-parametric method used forclassification andregression. In both cases, the input consists of the k c

【机器学习】5. K近邻(KNN)
K近邻(KNN) 1. K-Nearest Neighbour1.1 特点:计算复杂1.2 K的设置1.3 加权近邻 Weighted nearest neighbor1.4 决策边界 Decision boundaryVoronoi region 2. KNN总结 1. K-Nearest Neighbour K: 超参数(hyperparameter) 定义一种距离,参考
分类学习-KNN分类
#导入数据from sklearn.datasets import load_irisiris = load_iris() #使用加载器读取数据并且存入变量irisprint(iris.data.shape) #打印数据print(iris.DESCR)#分割数据from sklearn.cross_validation import train_t
【实战教程】用scikit-learn玩转KNN:鸢尾花数据集的分类之旅
KNN(K-Nearest Neighbors)算法是一种简单直观的监督学习算法,被广泛应用于分类和回归任务中。本文将带你一步步了解如何使用Python中的scikit-learn库实现KNN算法,并通过鸢尾花数据集来进行实战演练。让我们一起探索如何用KNN算法对鸢尾花进行分类吧! 1. 准备工作 首先,我们需要安装必要的库。如果你还没有安装scikit-learn,可以通过以下命令进行安

KNN算法与模型选择及调优
KNN算法-分类 1 样本距离判断 (1)欧式距离 欧式距离(Euclidean distance),也称为欧氏度量,是用来衡量两个点之间直线距离的方法。 (2)曼哈顿距离 曼哈顿距离(Manhattan distance),也称为城市街区距离,是在网格状坐标系统中,从一个点到另一个点的距离之和。 2 KNN 算法原理 K-近邻算法(K-Nearest Neighbo

aNN 与 kNN:了解它们在向量搜索中的区别和作用
作者:来自 Elastic Elastic Platform Team 在当今的数字时代,数据呈指数级增长,且日益复杂,高效搜索和分析这一浩瀚信息海洋的能力从未如此重要。但同时也从未如此具有挑战性。这就像大海捞针,但挑战在于针的形状不断变化。这就是向量搜索作为游戏规则改变者出现的地方,它改变了我们与大型数据集的交互方式。它通过将数据转换为向量(多维空间中的数学表示)来实现这一点,从而实现更细
KNN(K-NearestNeighbor)算法
KNN是最简单的分类算法之一。通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。其算法的描述为: 1. 计算测试数据与各个训练
使用MapReduce实现knn算法
算法的流程 (1)首先将训练集以共享文件的方式分发到各个map节点 (2)每一个map节点主要<LongWritable ,Text,,LongWritable,ListWritable<DoubleWritable>> LongWritable 主要就是文件的偏移地址,保证唯一。ListWritable主要就是最近的类别。 Reduce节点主要计算出,每一个要预测节点的类别。 packa

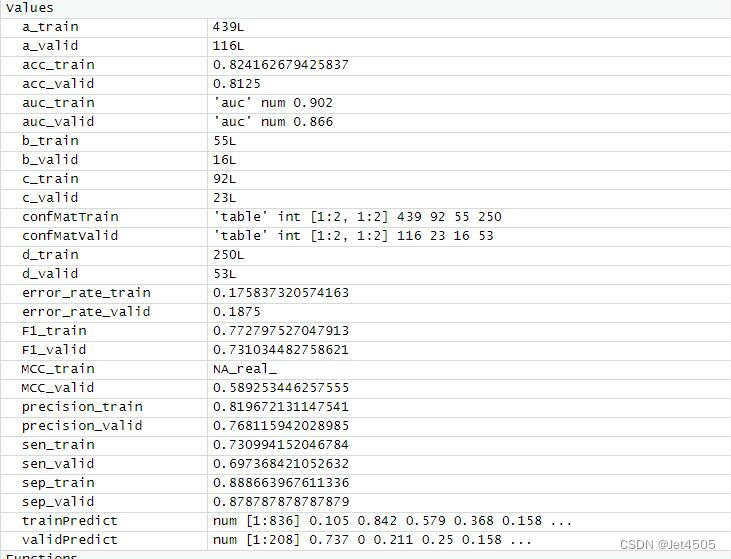
第100+12步 ChatGPT学习:R实现KNN分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现KNN分类 (1)导入数据 我习惯用RStudio自带的导入功能: (2)建立KNN模型 # Load necessary librarieslib
AI学习指南机器学习篇-KNN的优缺点
AI学习指南机器学习篇-KNN的优缺点 在机器学习领域中,K最近邻(K-Nearest Neighbors,KNN)算法是一种十分常见的分类和回归方法之一。它的原理简单易懂,但在实际应用中也存在一些优缺点。本文将重点探讨KNN算法的优缺点,并结合具体示例来说明KNN算法在处理异常值敏感、计算复杂度高等方面的问题。 KNN算法简介 KNN算法是一种基于实例的学习方法,它利用已知类别标记的训练数

MIA------KNN
#encoding:utf-8'''Created on 2015年4月28日@author: zju'''from numpy import *import operatordef createDataSet():group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])labels = ['A', 'A', 'B', 'B']r