iris专题

golang学习笔记——Gin、Beego、Iris、Echo框架学习资料
Gin Gin文档-中文 Gin文档-英文 Beego Beego文档-中文 Beego文档-英文 应用例子 Iris Iris文档-中文 Iris文档-英文 Echo Echo文档-中文 Echo文档-英文 Echo中间件
拖拽传图 Iris + DropzoneJS
Iris官方其实很厚道,有很多有用的例子,而社区则是文档多于实战。源于官方示例库([英文源文])(https://github.com/kataras/iris/tree/master/_examples/tutorial/dropzonejs),本文采用 DropzoneJS and Go实现图片上传,后端裁剪,前端呈现,代码量少但胜在实用,适合新同学实战。 涉及的点 Dropzone

Java 实现 BP 神经网络完成 Iris 数据分类
继了解了 BP 神经网络的原理后,笔者之前用 Java 实现三层的 BP 神经网络完成 Iris 鸢尾花数据集的分类预测,特此记录了实现过程,附源码。 1. Iris 鸢尾花数据集 Iris 也称鸢尾花卉数据集,是一类多重变量分析的数据集,来自 UCI 机器学习库,下载地址请戳这里。通过 sepal length(花萼长度),sepal width (花萼宽度),petal length (花

FCM聚类算法详解(Python实现iris数据集)
参考:https://blog.csdn.net/on2way/article/details/47087201 模糊C均值(Fuzzy C-means)算法简称FCM算法,是一种基于目标函数的模糊聚类算法,主要用于数据的聚类分析。理论成熟,应用广泛,是一种优秀的聚类算法。本文关于FCM算法的一些原理推导部分介绍,加上自己的理解和在课题项目中的应用以文字的形式呈现出来。 首先介绍一下模糊这个概
Cache和IRIS 数据库 分页查询(指定起始页)
全网几乎没有Cache数据库和IRIS数据库的分页查询(指定起始页),因此排了不少坑总结了可实行的方案。 目录 一、Cache数据库分页查询(指定起始页)二、IRIS数据库分页查询(指定起始页) 一、Cache数据库分页查询(指定起始页) Cache分页查询的参考文章 参考文章一 参考文章二 /*** (只有2011.1版本以后的cache数据库支持%VID分页查询)
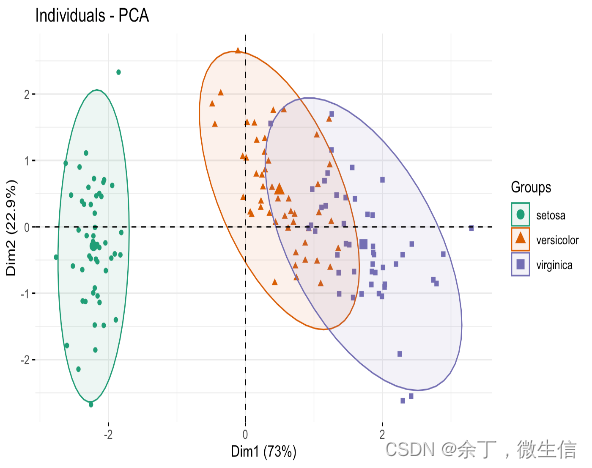
同样都是鸾尾花iris数据,为什么PCA图相反?
PCA简介 主成分分析(principle component analysis)是一种线性降维方法。它利用正交变换对一系列可能相关的变量的观测值进行线性变换,从而投影为一系列线性不相关变量的值,这些不相关变量称为主成分(Principal Components)。PCA是一种对数据进行简化分析的技术,可以有效地找出数据中最“主要”的元素和结构,去除噪音和冗余,将原有的复杂数据降维,揭示隐藏在复

IRIS国际铁路行业标准简介
IRIS,是国际铁路行业标准英文International Railway Industry Standard的缩写,它是一套铁路行业质量管理体系标准,是铁路行业的质量评估(管理)体系。它是在ISO 9001:2008的基础上,针对铁路行业的特殊要求而由欧洲铁路联盟于2006年5月18日发布实施的,并得到了四大系统制造商(庞巴迪、西门子、阿尔斯通和AnsaldoBreda)的大力宣传和支持。和航天

Fisher判别示例:鸢尾花(iris)数据(R)
先读取iris数据,再用程序包MASS(记得要在使用MASS前下载好该程序包)中的线性函数lda()作判别分析: data(iris) #读入数据iris #展示数据attach(iris) #用变量名绑定对应数据library(MASS) #加载MASS程序包ld=lda(Species~Sepal.Length+Sepal.Width+Petal.Len gth+Pe
IRIS / Chronicles 数据结构备忘录
数据结构的内容主要涉及到索引和全局变量。 这部分的内容的问题在于概念多,和普通的数据库对应的内容也不太一样,需要花点时间了解。 networked items 有关英文的解释是: Networked items that point to databases that use padded-string IDs always store the external (unpadded) f
第四十二章 保护与 IRIS 的 Web 网关连接 - Windows
文章目录 第四十二章 保护与 IRIS 的 Web 网关连接 - Windows`Kerberos` 的 `Windows Web` 网关配置 `Kerberos` 的 `UNIX®` `Web` 网关配置`Kerberos` 的 `UNIX® Web` 网关配置基于 `SSL/TLS` 的身份验证和数据保护 第四十二章 保护与 IRIS 的 Web 网关连接 - Windows
IRIS / Chronicles 定义 Item Response Type 字段属性
Response Type 在关系数据库中可能没有这个选项,我们对关系数据库表中的数据返回的数据就是是数据,通常不再做过多定义。 但是 IRIS 会对返回的数据也做一些定义,这个就是我们说的 Response Type。 Single (单一) 这个好说,就是返回一条数据。 这个就和我们的关系数据库差不多,你返回的数据就是数据,不管你这个数据是多少行。 Multiple (多条) 这里
IRIS / Chronicles 中的 Packing 字段型属性
Packing 的用途就是把一堆通常放一起的数据打包的意思。 这样做的目的就是降低交互。 还是用姓名这个间的的例子,为了我们能够拆分姓和名,我们通常有 Item 姓和 Item 名。 为什么这样,英文和中文其实差不多的,中文有复姓,比如说欧阳。 用名字:欧阳锋来举例。 那么我们针对姓名,我们在姓字段存储欧阳,名字段存储 锋。 如果我们需要获得完整的姓名,那么我们就可以把这 2 个 It
Chronicles 和 IRIS 是什么关系
这个公司就是 EPIC,他们自己写了一个基于 Caché 数据库的管理工具,然后起名叫做 Chronicles。 对于大部分人来说,直接用 IRIS 就可以了,并不需要使用 EPIC 的 Chronicles 数据库管理工具。 2020 年合并使用的新闻 在 2020年10月13日 intersystems 发布的新闻。EPIC 宣布从2020年08月开始,EPIC 将会使用 InterSy
机器学习--KNN算法应用,iris鸢尾花数据集的分类
数据集介绍 Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过 花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类. 用KNN分类Iris数据集 from sklearn.datasets import loa
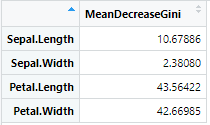
基于R语言和iris数据集实现随机森林模型及测试应用
基于R语言和iris数据集实现随机森林模型及测试应用 测试应用R代码 #加载随机森林模型库> library("randomForest")#加载iris数据集> data(iris)> head(iris)# 设置训练数据和标签 t_data <- iris[, -5] t_labels <- iris[, 5] # 训练随机森林模型 rf_model <- random
Gin和Iris等Web框架及redis与go的连接使用
参考链接 首先安装go 然后配置环境变量 Windows 修改环境变量和网络代理 前面两句相当于修改环境变量中的参数,然后才能下载。 版本为go1.13以后似乎才有效 go env -w GO111MODULE=ongo env -w GOPROXY=https://goproxy.cn,directgo get -u github.com/gin-gonic/gingo get gi

在IRIS中联合运用OCR与NLP技术
根据IDC的报道,超过80%的信息是基于NoSQL的,尤其是文本文件。当数字服务或应用程序不能处理所有这些信息时,企业就会遭受损失。为了面对这一挑战,可以使用OCR技术。OCR使用机器学习和/或训练的图像模式将图像像素转化为文本。这一点很重要,因为许多文件被扫描成PDF格式的图像,或者许多文件中包含有文本的图像。因此,OCR是一个重要的步骤,可以从文件中获得所有可能的数据。 为了实现OCR,可以

第十章 配置 IIS 以与 Web 网关配合使用 (Windows) - 映射 InterSystems IRIS 文件扩展名
文章目录 第十章 配置 IIS 以与 Web 网关配合使用 (Windows) - 映射 InterSystems IRIS 文件扩展名映射`IRIS`文件扩展名映射其他文件类型操作和管理 `Web` 网关 第十章 配置 IIS 以与 Web 网关配合使用 (Windows) - 映射 InterSystems IRIS 文件扩展名 映射IRIS文件扩展名 注意:请勿使用“添
IRIS、Cache系统类汉化
文章目录 系统类汉化简介标签说明汉化系统包说明效果展示类分类%Library包下的类重点类非重点类弃用类数据类型类工具类 使用说明 系统类汉化 简介 帮助小伙伴更加容易理解后台系统程序方法使用,降低代码的难度。符合本土化中文环境的开发和维护,有助于在中文区域推广和使用IRIS。系统类全部人工校对翻译,超长描述尽量折叠在一屏上显示方便查看。每个系统类按功能打上标签,降低学习成
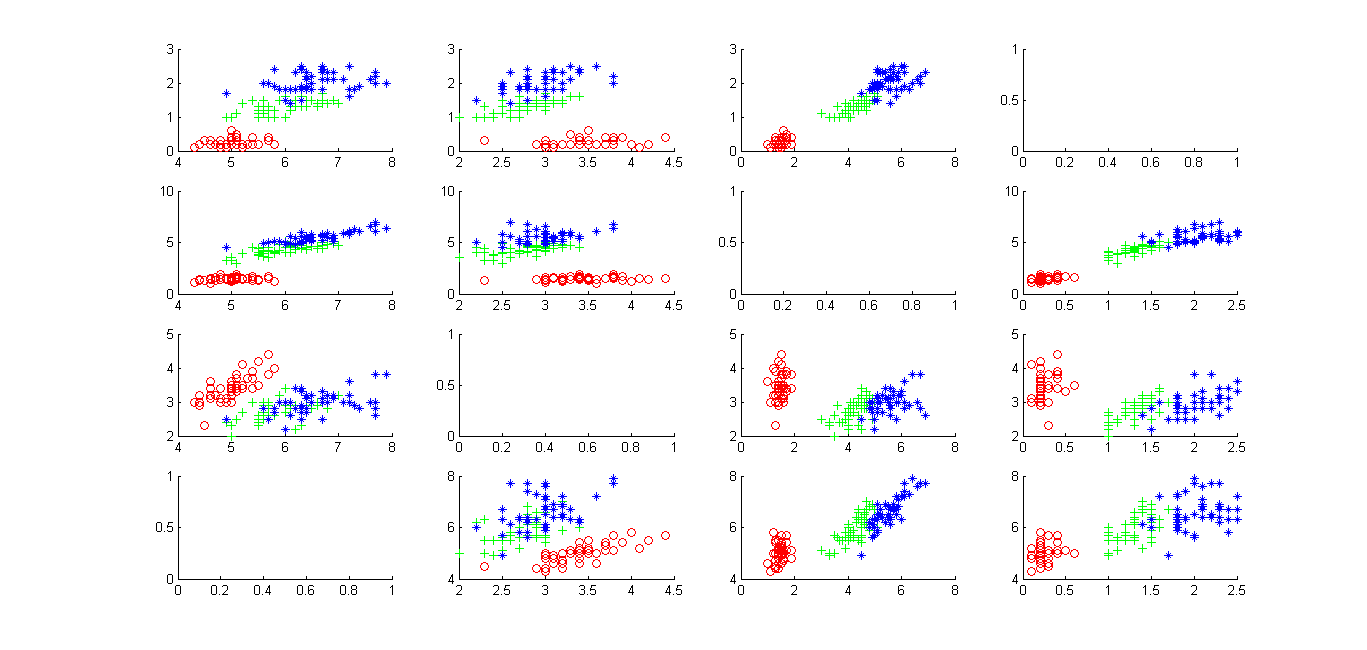
使用平行轴图显示鸢尾花(iris)的四个特征数据(创新实验室联合纳新测试题)
也是扯淡,创新实验室纳个新还要出题考试。 出题就出题吧,还出得这么难。 再难也得做啊。。。 先上题: 1.数学建模 (1)使用平行轴图显示鸢尾花(iris)的四个特征数据; (2)尝试使用其他方法优化呈现(可文字叙述,选作); 。。。。。。。 啥是鸢尾花? Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。 iris以鸢尾花的特征作
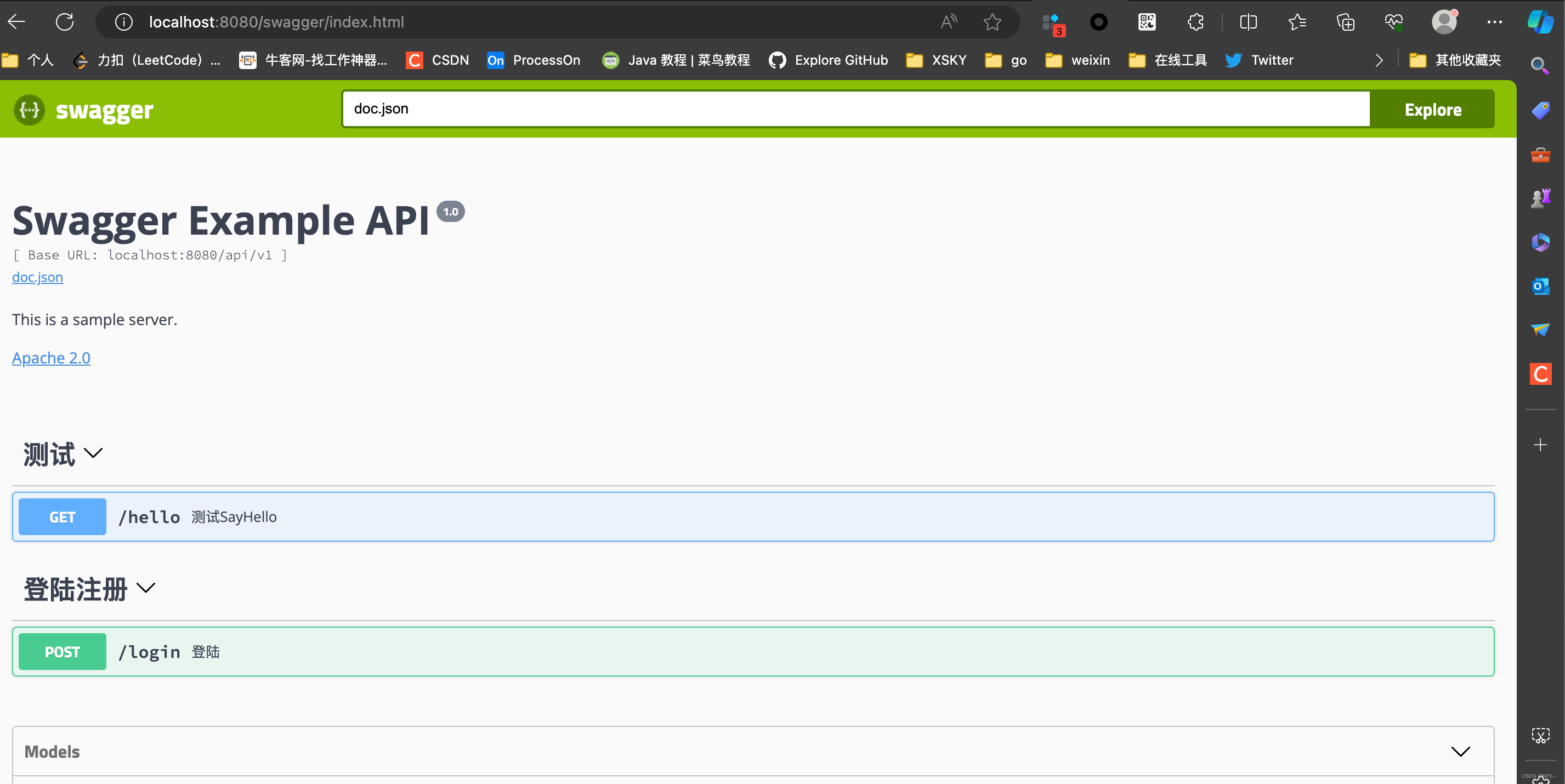
golang 引入swagger(iris、gin)
golang 引入swagger(iris、gin) 在开发过程中,我们不免需要调试我们的接口,但是有些接口测试工具无法根据我们的接口变化而动态变化。文档和代码是分离的。总是出现文档和代码不同步的情况。这个时候就可以在我们项目中引入swagger,方便后期维护以及他人快速上手项目 0 下载swagger # 1 安装swagger# 在go.mod目录所在位置执行命令go get
编写fisher线性判别函数,实现Iris Data Set的数据分类
Fisher线性判决函数 简介实验要求实验环境环境搭建中遇到的问题及解决方案1.安装时报Non-zero exit code (1)2.package的安装 实验过程查看原文 简介 Iris Data Set(鸢尾属植物数据集)是历史较为久远的数据集,它首次出现在著名的英国统计学家和生物学家Ronald Fisher 1936年的论文《The use of multiple m
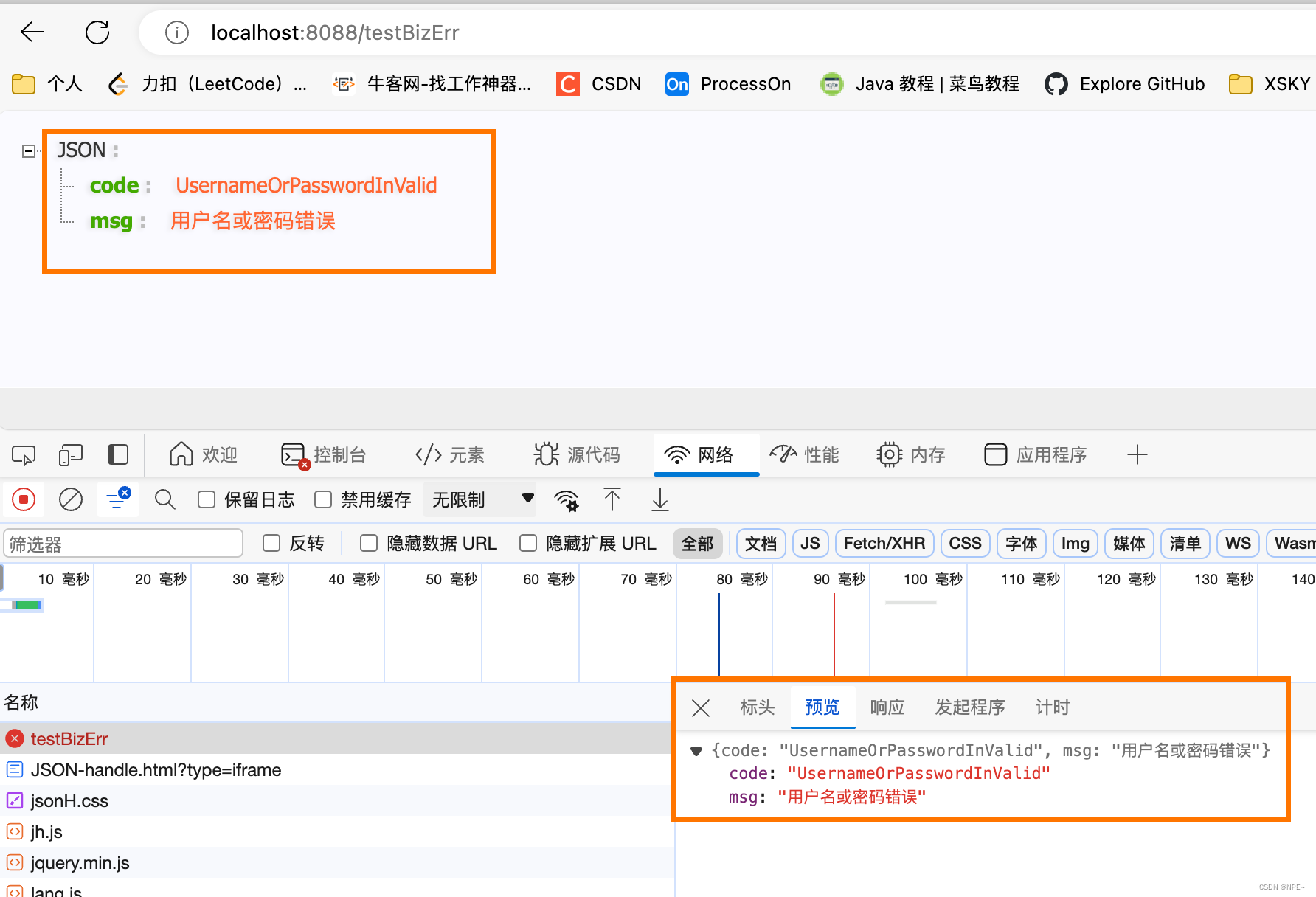
golang封装业务err(结合iris)
golang封装业务err 我们有时在web开发时,仅凭httpStatus以及msg是不方便维护和体现我们的业务逻辑的。所以就需要封装我们自己的业务错误。 自定义biz_err维护err map:errorResponseMap、errorHttpStatusMap 注意:本文主要以演示为主,主要是让大家熟悉封装自定义错误的思路,故而封装的较为简单。大家可根据自己公司需求来进行拓展。
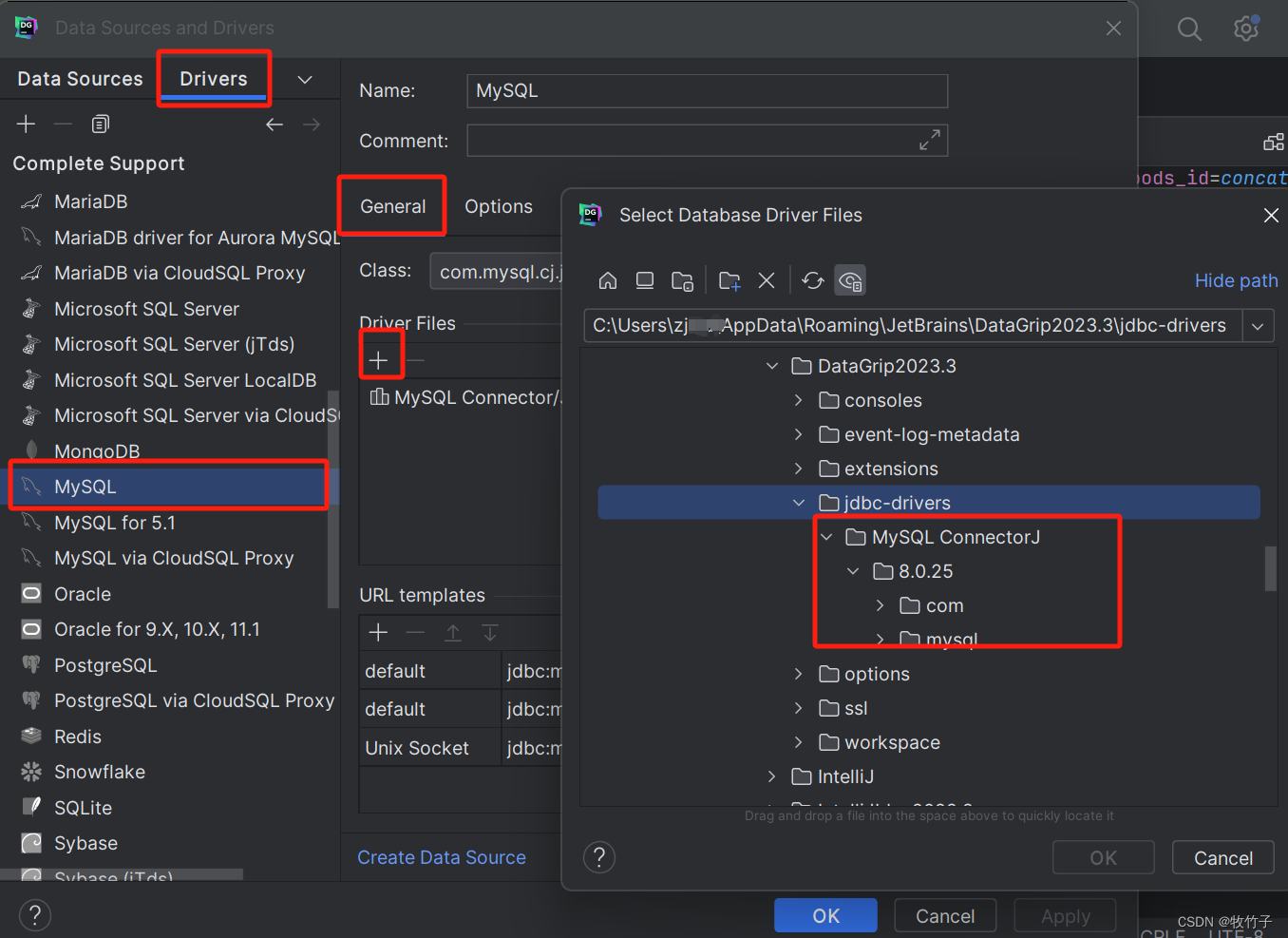
dataGrip连接数据库mysql和intersystems的iris
文章目录 前言创建新项目选择对应的数据库产品类型新建数据库资源连接sql命令窗体手动配置本地驱动 前言 intersystems公司的产品iris是cache的升级版本,目前绝大多数数据库工具都没法连接这个数据库 datagrip下载地址 https://download-cdn.jetbrains.com.cn/datagrip/datagrip-2023.3.3.exe

EDA-数据探索-pandas自带可视化-iris
# 加载yellowbrick数据集import osimport pandas as pdFIXTURES = os.path.join(os.getcwd(), "data")df = pd.read_csv(os.path.join(FIXTURES,"iris.csv"))df.head() sepal_lengthsepal_widthpetal_lengthpe
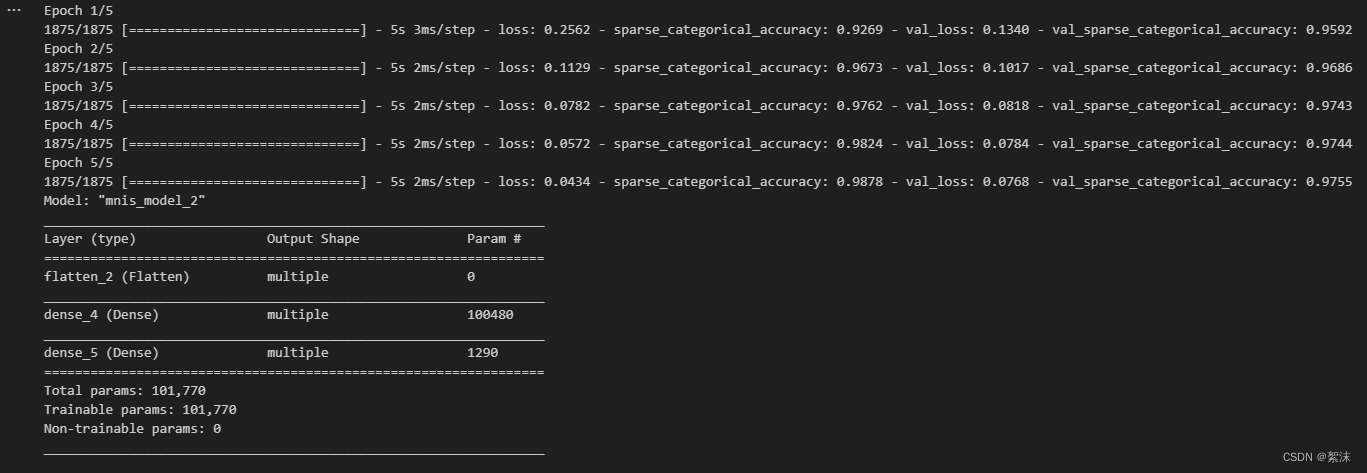
深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 认识网络的构建结构 在神经网络的构建过程中,都避不开以下几个步骤: 导入网络和依赖模块原始数据处理和清洗加载训练和测试数据构建网络结构,确定网络优化方法将数据送入网络进行训练,同时判断预测效果保存模型部署算法,使用新的数据进行预测推