本文主要是介绍IRIS / Chronicles 数据结构备忘录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据结构的内容主要涉及到索引和全局变量。
这部分的内容的问题在于概念多,和普通的数据库对应的内容也不太一样,需要花点时间了解。
networked items
有关英文的解释是:
Networked items that point to databases that use padded-string IDs always store the external (unpadded) form of the target record’s .1 item. This eliminates the padding factor dependency, which could be changed through a data conversion. If the database networked to uses numeric IDs, then the value stored in the item is identical to the record’s ID.
说人话就是对于一个 Item 是 networked 的话,这个 Item 中存储的数据就是根据 .1 这个 Item external (unpadded) 来的。
这里有 2 个概念,.1 这个 Item 可以存字符串,.1 这个Item 也可以存全是数字,当如果 .1 存储是全是数字的话,networked 的存储数据和 .1 中的数据是相同的。
但是,因为 padded 的问题,针对 String 的 Padded 的时候,会在字符串前面加空格,这会导致在数据转换的时候可能会不一致。
这个知识点就想表达的意思就是可能数据在转换的时候会不一致。
Chronicles Locators
Chronicles Locators describe the subscripts used to define nodes in Chronicles Data Globals. The 5 standard locators are INI, ID, DAT, Item # and Line #. In addition to being subscripts to globals, the locators are also used as input to various routines and utilities, as well as arguments to Chronicles API.
Chronicles Locators 主要用途就是把数据从 Chronicles Data Globals 读取出来。要读取 Chronicles Data Globals 中的数据,需要有 5 个参数:INI, ID, DAT, Item # 和 Line #。
用中文来翻译的话,这个应该叫做 Chronicles 数据全局。
Chronicles Data Globals 可以认为是 Chronicles 和 M 语言全局变量中的一个映射。
根据我们对 Chronicles 数据库的了解,Chronicles 将会把数据映射到 M 语言的全局变量中,然后提供语言级别的调用,这个和我们常用的关系数据库不一样,因为我们不可能把数据库中的内容全部映射到一个程序语言的全局变量中,这会导致溢出的。
但 Chronicles 这个数据就是这样操作的。
Remember to look before you leap; view your test data before writing code to load it, so you know what to expect. To create your test data, use Chronicles. To see the raw data and locators along with most translations, use the Record Viewer. The important locators can be seen in the chart below and will be critical to loading in the next section.
Determine the number of lines of data in an item
Multiple, related and related-multiple response items maintain a line count within line 0 of the item. This line 0 line count is not necessary for a single response item because single response items (by definition) may not have more than one line.
Multiple, related 和 related-multiple 这 3 个 Response Type 中的数字分别有不同的意思。
Multiple, related 的 Line 0 表示的是一共有多少个 Line。
related-multiple 的 Line 0 表示的内容也是 Count 这个 Line 的数量,但是后面用一个 2 维数组来表示了。比如说,1,0 的值如果是 1 的话,表示这个 RM 只有一个 Line。
那对应的下一个 Line # 就是 1,1。
如果 1,0 的值为 2 的话,就表示这个 RM 会有 2 个 Line。
那么对应的好后续值分别为 1,1 和 1,2。

哪怕就是采用上面的表示方式,related-multiple 还是有一个 Line 为 0 的东西,这个表示的是这个 related-multiple 下面一共有多少条记录。
总结来说,当 Line # 为 0 的时候表示的就是数量。
Explain what is used to identify contacts in Chronicles Data Globals that store information over time
Contacts are identified by DAT. The DAT is derived from the internal format of the date subtracted from a constant (121531) to ensure that when using a natural sort order the most recent information is returned first.
在 Chronicles Data Globals 中,就是在 M 语言的全局变量中,Contacts 数据是通过 DAT 来进行定义的。
这里就有一个计算方法了,DAT=121531-DTE。
所以随着时间的推移,DAT 在系统中的数值是越来越小的,等于在系统中是递减的,然后在显示的时候排序就是小的在前面,这样能够保证最新的数据在最前面,按照 DAT 从小到大的方式来显示。
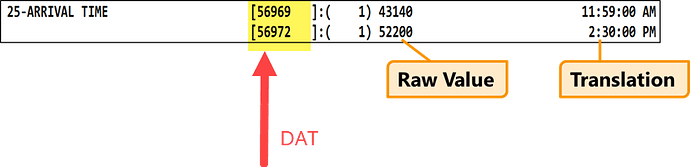
上图显示了 DAT 的排序情况。
IRIS / Chronicles 数据结构备忘录 - 数据库 - iSharkFly数据结构的内容主要涉及到索引和全局变量。 这部分的内容的问题在于概念多,和普通的数据库对应的内容也不太一样,需要花点时间了解。 networked items有关英文的解释是: Networked items that point to databases that use padded-string IDs always store the external (unpadded) form of the target rec…![]() https://www.isharkfly.com/t/iris-chronicles/15621
https://www.isharkfly.com/t/iris-chronicles/15621
这篇关于IRIS / Chronicles 数据结构备忘录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








