本文主要是介绍使用平行轴图显示鸢尾花(iris)的四个特征数据(创新实验室联合纳新测试题),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
也是扯淡,创新实验室纳个新还要出题考试。
出题就出题吧,还出得这么难。
再难也得做啊。。。
先上题:
1.数学建模
(1)使用平行轴图显示鸢尾花(iris)的四个特征数据;
(2)尝试使用其他方法优化呈现(可文字叙述,选作);
啥是鸢尾花?
iris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
我也是醉了。。。
这玩意上哪儿找啊?难不成matlab自带?
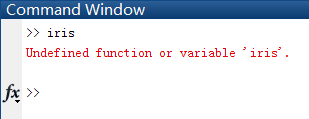
too young...
只好下载了一个,2k的文件居然还要我1积分,真是世风日下,人心不古啊。。。
下载下来打开看看:
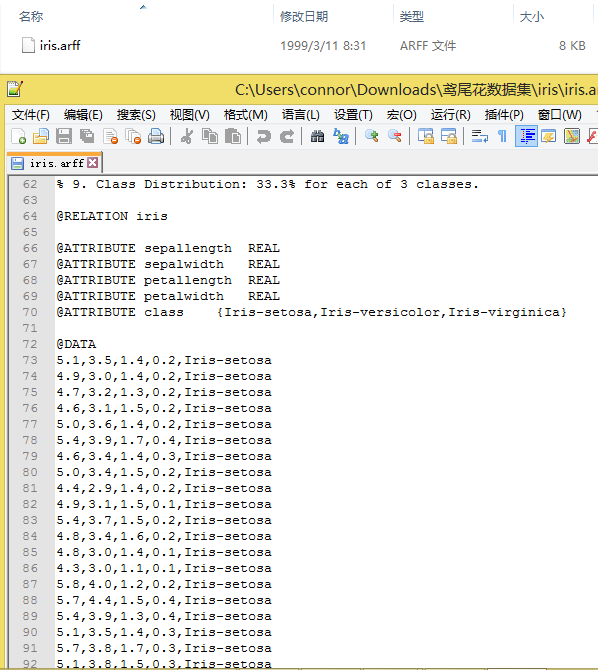
这堆东西是个啥?arrf又是啥?
我去。。。我的第一个stackoverflow居然就献给这个东西了。。。
http://stackoverflow.com/questions/6952315/how-to-load-arff-format-file-to-matlab
Is there any package to load .arff format file into matlab?The .arff format is used in Weka for running machine learning algorithm.
Yes, there are a few MATLAB interfaces for WEKA files on MATLAB File Exchange, I normally use this one: http://www.mathworks.com/matlabcentral/fileexchange/21204-matlab-weka-interface where you have a saveARFF() and a loadARFF() functions.
| | any examples on how it is used? – mike_x_ Oct 4 '14 at 15:01 | ||
| | If you unzip the fileexchange files into your working directory you can use loadARFF in this way: data = loadARFF('myfile.arf'). – Matteo De Felice Oct 6 '14 at 7:14 | ||
| | I get an error but i ll check again. I have unzipped it and added the folder with subfolders in the path, by clicking the button "set path". Is it correct? Do i have to do anything else so as to import the toolkit? |
把这个下载下来看看:
http://www.mathworks.com/matlabcentral/fileexchange/21204-matlab-weka-interface
嗯,看着挺靠谱的。
添加路径:
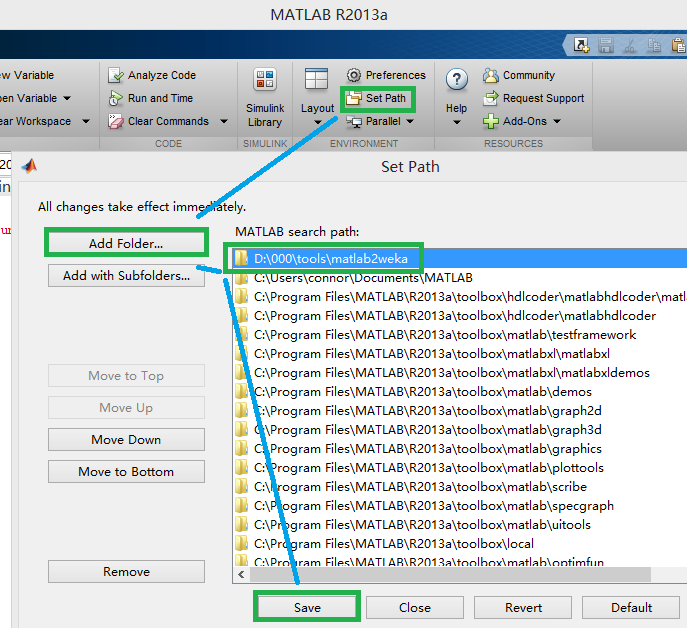

Error: File: loadARFF.m Line: 9 Column: 12
Arguments to IMPORT must either end with ".*" or else specify a fully qualified class name:
"weka.core.converters.ArffLoader" fails this test.
。。。。。。。
还得下这个开发环境。。。
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
我的java版本不够,果断下载第一个。

安装完之后还报错。。。。。。。
受 saber大牛文章指教:
http://blog.csdn.net/xywlpo/article/details/6531025
——————————————————————————————————————
不要以为下载下来就能用,你会在如下地方报错:
if(~wekaPathCheck),wekaOBJ = []; return,end
import weka.core.converters.ArffLoader;
import java.io.File;
Tricky的事情就是得把weka.jar加入到matlab的classpath.txt列表。classpath.txt在哪儿?到matlab的command窗口敲:
>> which classpath.txt
/Applications/MATLAB_R2010b.app/toolbox/local/classpath.txt
这个是在mac下的结果,windows估计也有类似的文件结构。然后就是到classpath.txt里加入一行,weka.jar的绝对路径,例如:
/Applications/weka-3-6-4.app/Contents/Resources/Java/weka.jar
好了,matlab的借口就配置好了。
这里还有个问题,保存的ARFF中类别信息(class)是numrical型,不是枚举型,至少调用LibSVM会报错。
得手工修改(我的数据有7类):
@attribute class numeric => @attribute class {1,2,3,4,5,6,7}
OK,matlab这边这下没问题了。
——————————————————————————————————————————————
同时参考了以下文章:
http://blog.sina.com.cn/s/blog_890c6aa30101av9x.html
——————————————————————————————————————————————
——————————————————————————————————————————————
java还得添加环境变量,当真麻烦。。。
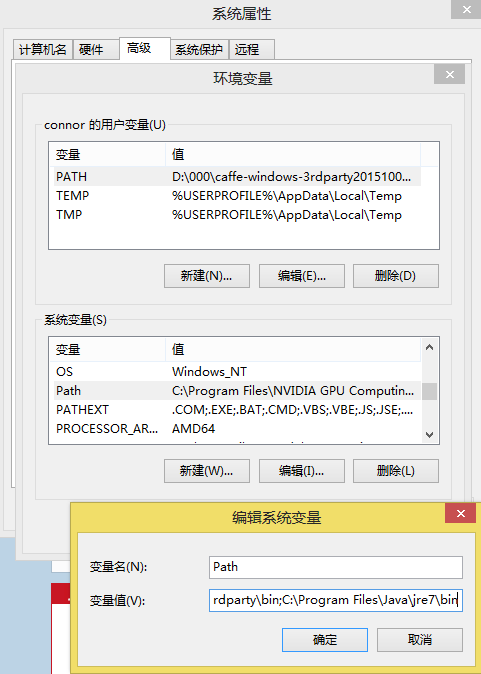
添加java路径:
还得把反斜杠换成斜杠。。。
D:\000\tools\Weka-3-6\weka.jar
又报错了 。。。
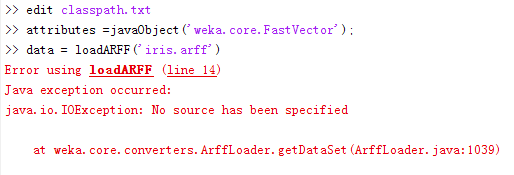
把arff文件复制到当前路径下,解决:
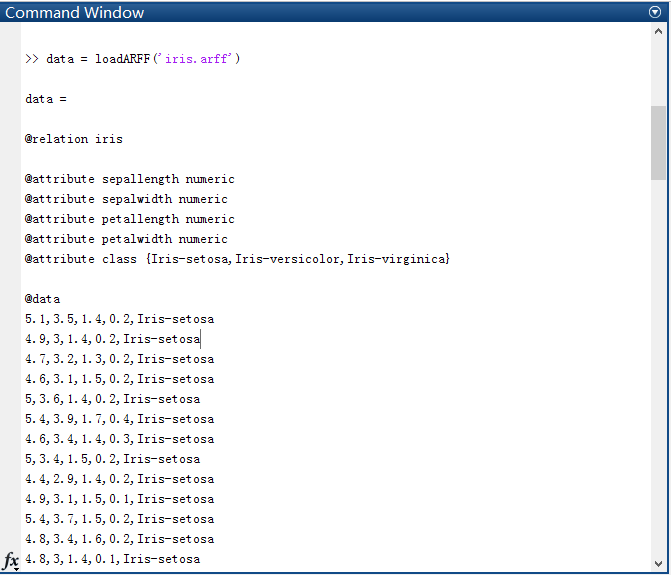
下面用格式转换命令:
[mdata,featureNames,targetNDX,stringVals,relationName] =weka2matlab(data);
====================================我是分割线========================================================
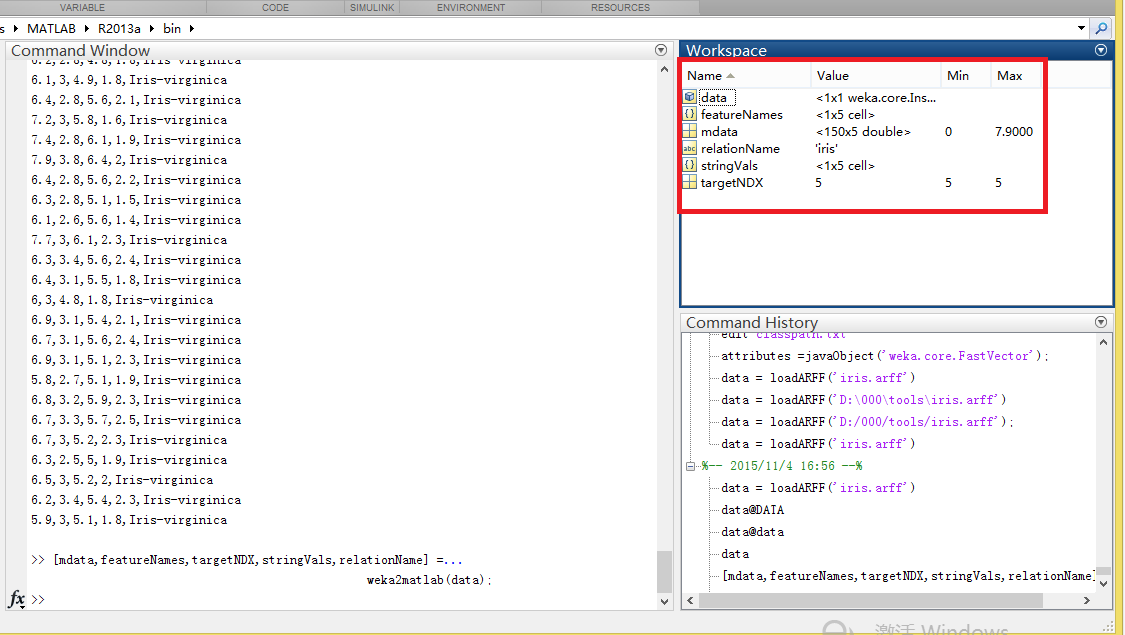
把mdata保存一下,这样,鸢尾花(iris)数据集就可以直接使用了。
————————————————————————————————————————————
我已经将txt格式的鸢尾花数据集上传到我的资源,在matlab下可以一句话加载。
资源:http://download.csdn.net/detail/u013657981/9241121
matlab命令:load('iris.txt')
————————————————————————————————————————————
我们要用mdata矩阵画平行轴图
啥又是平行轴图?
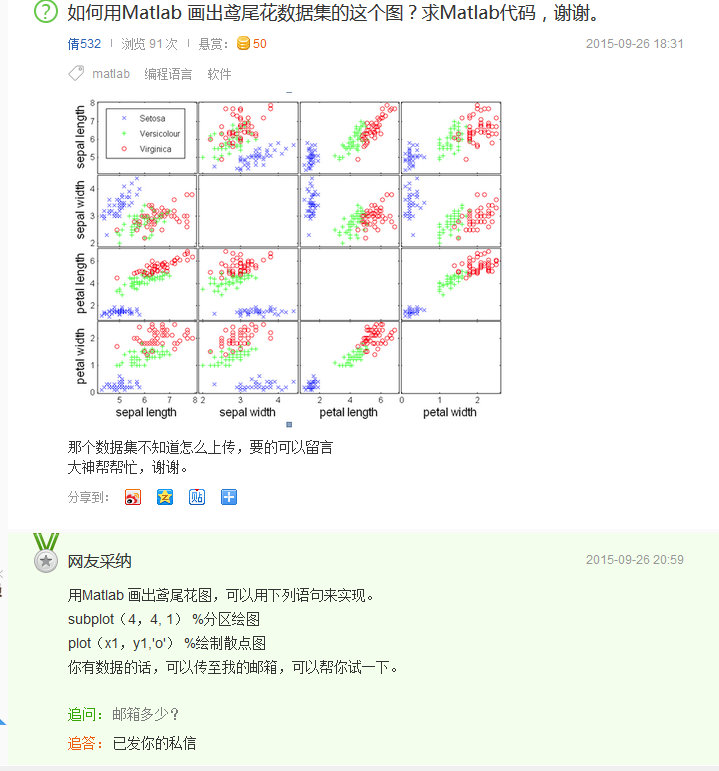
看来大概是这么个东西:
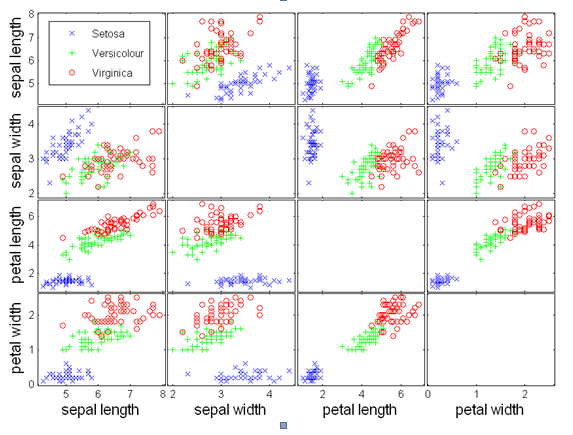
看看这个东西是怎么画出来的:
用Matlab 画出鸢尾花图,可以用下列语句来实现。 subplot(4,4, 1) %分区绘图 plot(x1,y1,'o') %绘制散点图 你有数据的话,可以传至我的邮箱,可以帮你试一下。
嗯,思路大概是,用
subplot(4,4, 1)分成16个区
以下四个变量:
sepallength
sepalwidth
petallength
petalwidth
分别为
x1,x2,x3,x4
再来一遍
y1,y2,y3,y4
Iris-setosa,Iris-versicolor,Iris-virginica 是三类,用不同的颜色和形状表示。
iris矩阵是150*5
思路呢,是这么个思路:
每一行是一个数据点(样本),每个样本第五个元素(第五列)是类别标签。
那就把0,1,2三类挑出来,
就是iris(第五列为0的行,的所有列)
然后自己跟自己对应着画图就可以了。
subplot排版略麻烦:
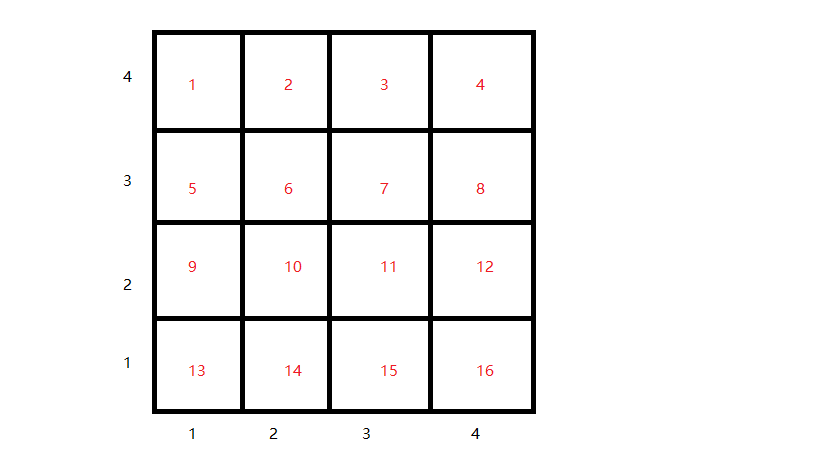
代码是这样的:
Iris_setosa=iris(iris(:,5)==0,:);
Iris_versicolor=iris(iris(:,5)==1,:);
Iris_virginica=iris(iris(:,5)==2,:);
subplot(4,4,1);
%第一列的所有行,第四列的所有行
scatter(Iris_setosa(:,1),Iris_setosa(:,4),'red');
hold on
scatter(Iris_versicolor(:,1),Iris_versicolor(:,4),'g','+');
hold on
scatter(Iris_virginica(:,1),Iris_virginica(:,4),'b','*');subplot(4,4,5);scatter(Iris_setosa(:,1),Iris_setosa(:,3),'red');
hold on
scatter(Iris_versicolor(:,1),Iris_versicolor(:,3),'g','+');
hold on
scatter(Iris_virginica(:,1),Iris_virginica(:,3),'b','*');subplot(4,4,9);scatter(Iris_setosa(:,1),Iris_setosa(:,2),'red');
hold on
scatter(Iris_versicolor(:,1),Iris_versicolor(:,2),'g','+');
hold on
scatter(Iris_virginica(:,1),Iris_virginica(:,2),'b','*');subplot(4,4,13);subplot(4,4,2);
%第一列的所有行,第四列的所有行
scatter(Iris_setosa(:,2),Iris_setosa(:,4),'red');
hold on
scatter(Iris_versicolor(:,2),Iris_versicolor(:,4),'g','+');
hold on
scatter(Iris_virginica(:,2),Iris_virginica(:,4),'b','*');subplot(4,4,6);scatter(Iris_setosa(:,2),Iris_setosa(:,3),'red');
hold on
scatter(Iris_versicolor(:,2),Iris_versicolor(:,3),'g','+');
hold on
scatter(Iris_virginica(:,2),Iris_virginica(:,3),'b','*');subplot(4,4,10);subplot(4,4,14);scatter(Iris_setosa(:,2),Iris_setosa(:,1),'red');
hold on
scatter(Iris_versicolor(:,2),Iris_versicolor(:,1),'g','+');
hold on
scatter(Iris_virginica(:,2),Iris_virginica(:,1),'b','*');subplot(4,4,3);
%第一列的所有行,第四列的所有行
scatter(Iris_setosa(:,3),Iris_setosa(:,4),'red');
hold on
scatter(Iris_versicolor(:,3),Iris_versicolor(:,4),'g','+');
hold on
scatter(Iris_virginica(:,3),Iris_virginica(:,4),'b','*');subplot(4,4,7);subplot(4,4,11);scatter(Iris_setosa(:,3),Iris_setosa(:,2),'red');
hold on
scatter(Iris_versicolor(:,3),Iris_versicolor(:,2),'g','+');
hold on
scatter(Iris_virginica(:,3),Iris_virginica(:,2),'b','*');subplot(4,4,15);scatter(Iris_setosa(:,3),Iris_setosa(:,1),'red');
hold on
scatter(Iris_versicolor(:,3),Iris_versicolor(:,1),'g','+');
hold on
scatter(Iris_virginica(:,3),Iris_virginica(:,1),'b','*');subplot(4,4,4);subplot(4,4,8);
%第一列的所有行,第四列的所有行
scatter(Iris_setosa(:,4),Iris_setosa(:,3),'red');
hold on
scatter(Iris_versicolor(:,4),Iris_versicolor(:,3),'g','+');
hold on
scatter(Iris_virginica(:,4),Iris_virginica(:,3),'b','*');subplot(4,4,12);scatter(Iris_setosa(:,4),Iris_setosa(:,2),'red');
hold on
scatter(Iris_versicolor(:,4),Iris_versicolor(:,2),'g','+');
hold on
scatter(Iris_virginica(:,4),Iris_virginica(:,3),'b','*');subplot(4,4,16);scatter(Iris_setosa(:,4),Iris_setosa(:,1),'red');
hold on
scatter(Iris_versicolor(:,4),Iris_versicolor(:,1),'g','+');
hold on
scatter(Iris_virginica(:,4),Iris_virginica(:,1),'b','*');结果是这样的:
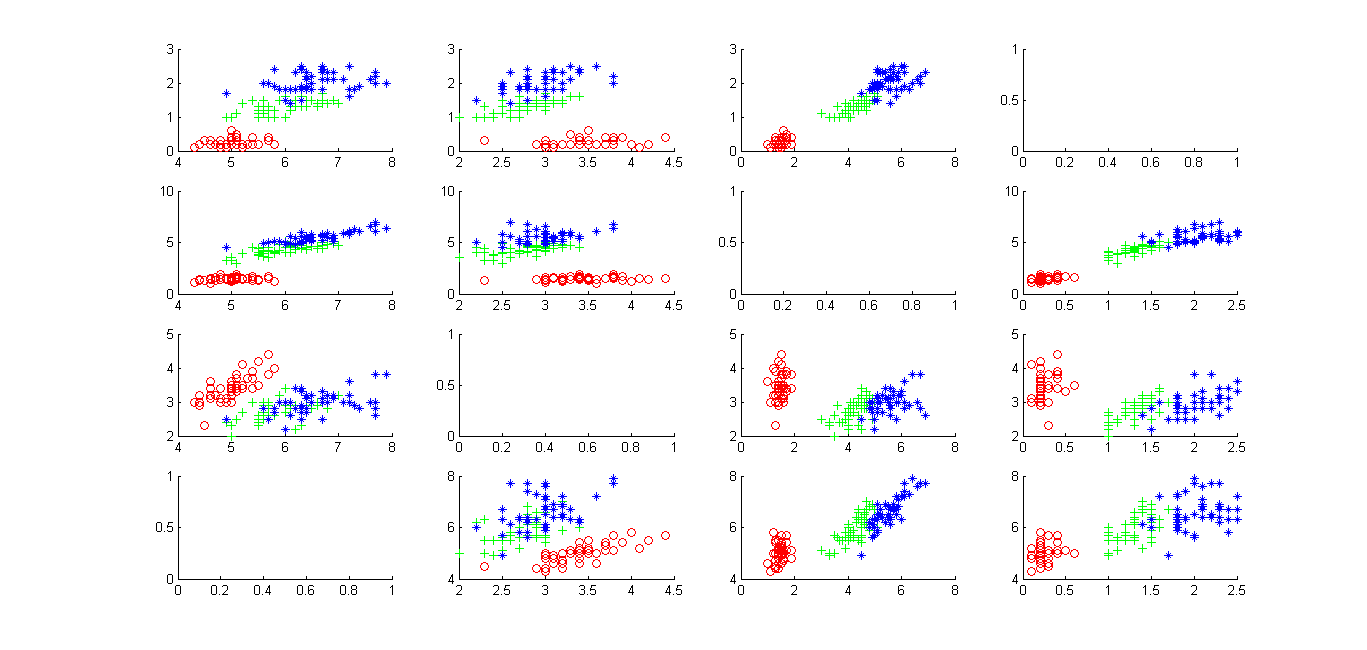
这篇关于使用平行轴图显示鸢尾花(iris)的四个特征数据(创新实验室联合纳新测试题)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




