鸢尾花专题

【机器学习】任务二:波士顿房价的数据与鸢尾花数据分析及可视化
目录 1.实验知识准备 1.1 NumPy 1.2 Matplotlib 库 1.3 scikit-learn 库: 1.4 TensorFlow 1.5 Keras 2.波士顿房价的数据分析及可视化 2.1波士顿房价的数据分析 2.1.1 步骤一:导入所需的模块和包 2.1.2 步骤二:从 Keras 库中加载波士顿房价数据集 2.1.3 步骤三:加载本地 CSV 数据集

【实战教程】用scikit-learn玩转KNN:鸢尾花数据集的分类之旅
KNN(K-Nearest Neighbors)算法是一种简单直观的监督学习算法,被广泛应用于分类和回归任务中。本文将带你一步步了解如何使用Python中的scikit-learn库实现KNN算法,并通过鸢尾花数据集来进行实战演练。让我们一起探索如何用KNN算法对鸢尾花进行分类吧! 1. 准备工作 首先,我们需要安装必要的库。如果你还没有安装scikit-learn,可以通过以下命令进行安

【机器学习】鸢尾花分类:机器学习领域经典入门项目实战
学习机器学习,就像学习任何新技能一样,最好的方法之一就是通过实战来巩固理论知识。鸢尾花分类项目是一个经典的入门项目,它不仅简单易懂,还能帮助我们掌握机器学习的基本步骤和方法。 鸢尾花数据集(Iris Dataset)早在1936年就由英国生物学家 Ronald A. Fisher 引入。这个数据集包含了150个鸢尾花样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)和1个目标变量

基于BP神经网络对鸢尾花数据集分类
目录 1. 作者介绍2. 关于理论方面的知识介绍2.1 BP神经网络原理2.2 BP神经网络结构 3. 关于实验过程的介绍,完整实验代码,测试结果3.1 鸢尾花数据集介绍3.2 代码演示3.3 结果演示 4. 问题与分析 1. 作者介绍 侯硕,男,西安工程大学电子信息学院,2023级研究生 研究方向:机器视觉与人工智能 电子邮件:1302088912@qq.com 徐达,男,西

鸢尾花分类和手写数字识别(K近邻)
鸢尾花分类 from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitimport pandas as pdimport mglearn# 加载鸢尾花数据集iris = load_iris()X_train, X_test, y_train, y_test = tr

基于鸢尾花数据集实施自组织神经网络聚类分析
基于鸢尾花数据集实施自组织神经网络聚类分析 1. 自组织神经网络的基础知识2. 鸢尾花数据集的自组织分类3. SOM的无监督聚类 1. 自组织神经网络的基础知识 自组织神经网络也称自组织映射(SOM)或自组织特征映射(SOFM),是一种使用非监督式学习来产生训练样本的输入空间的一个低维(通常是二维)离散化的表示的人工神经网络(ANN)。自组织映射与其他人工神经网络的不同之处在于它

鸢尾花分类-pytorch实现
前言 本文用pytorch实现了鸢尾花分类,数据不多,只做代码展示用,后续有升级版本。 代码 '''-*- coding: utf-8 -*-@File : main.py@Author: Shanmh@Time : 2024/05/06 上午9:37@Function:'''import torchfrom sklearn import datasetsimp
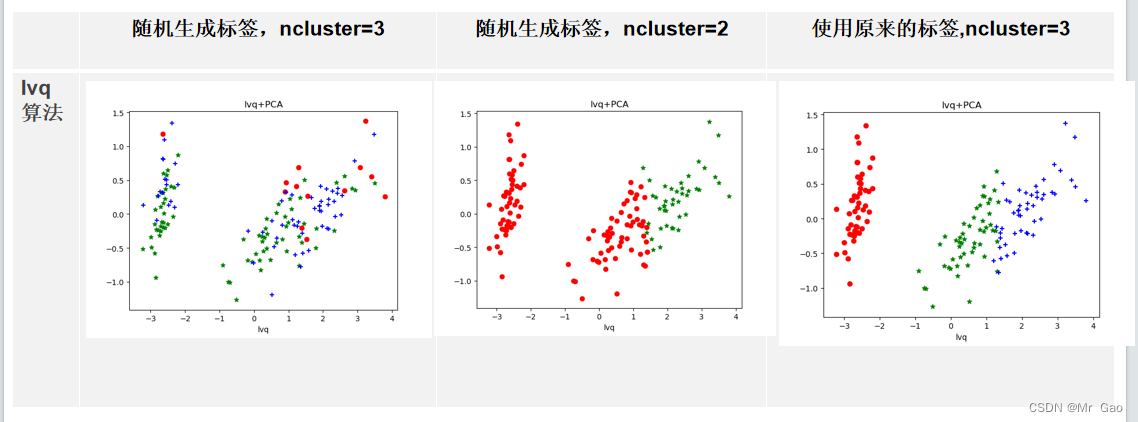
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比
基于鸢尾花数据集的四种聚类算法(kmeans,层次聚类,DBSCAN,FCM)和学习向量量化对比 注:下面的代码可能需要做一点参数调整,才得到所有我的运行结果。 kmeans算法: import matplotlib.pyplot as plt # 导入matplotlib的库import numpy as np # 导入numpy的包from sklearn import datase

【Python】使用Pandas和随机森林对鸢尾花数据集进行分类
我在鼓楼的夜色中 为你唱花香自来 在别处 沉默相遇和期待 飞机飞过 车水马龙的城市 千里之外 不离开 把所有的春天 都揉进了一个清晨 把所有停不下的言语变成秘密 关上了门 莫名的情愫啊 请问 谁来将它带走呢 只好把岁月化成歌 留在山河 🎵 鹿先森乐队《春风十里》 在本教程中,我们将演示如何使用pandas库来处理数据,并利用scikit-lea
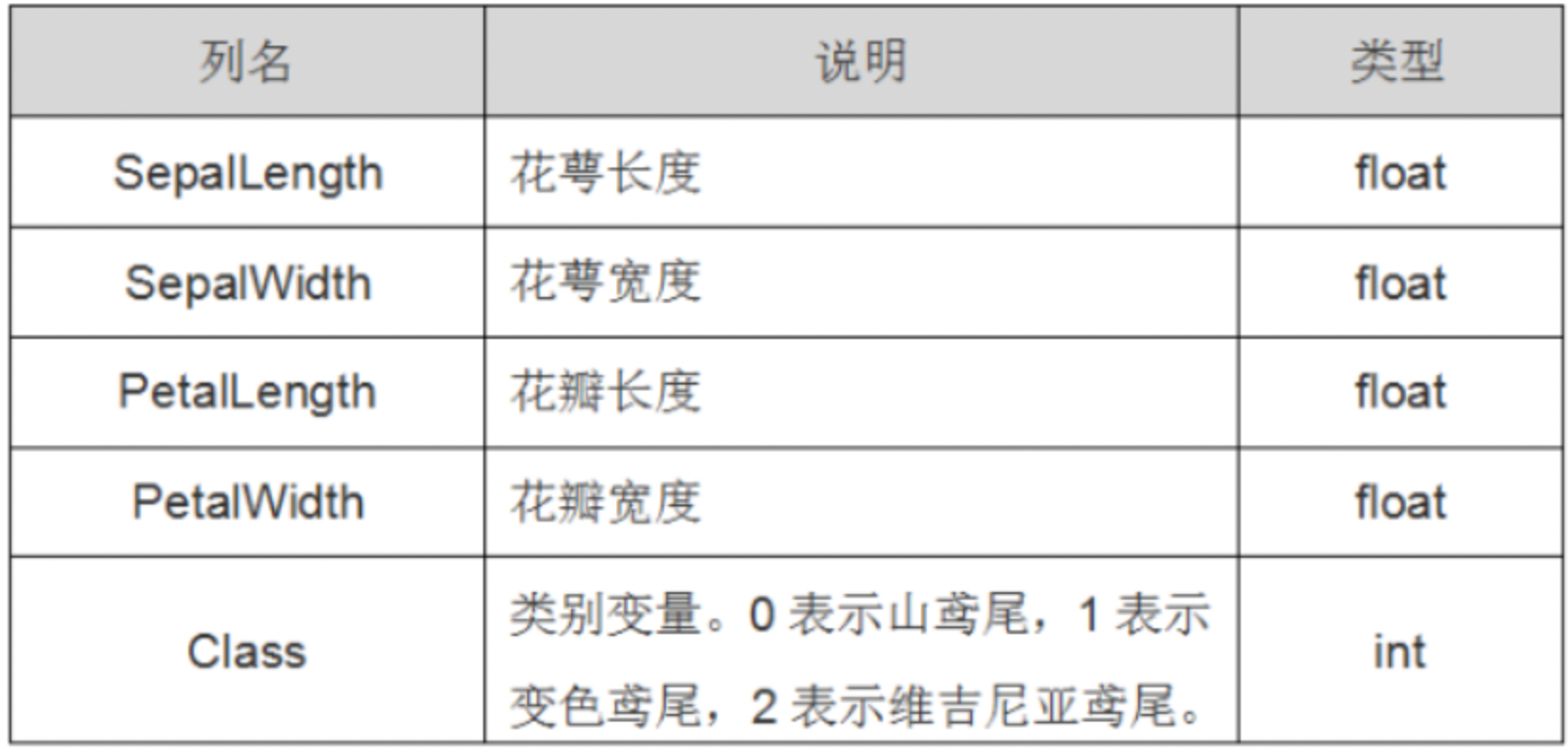

Bayes判别示例数据:鸢尾花数据集
使用Bayes判别的R语言实例通常涉及使用朴素贝叶斯分类器。朴素贝叶斯分类器是一种简单的概率分类器,基于贝叶斯定理和特征之间的独立性假设。在R中,我们可以使用`e1071`包中的`naiveBayes`函数来实现这一算法。下面,我将通过一个简单的示例展示如何在R中应用朴素贝叶斯方法来进行数据分类。 示例数据:鸢尾花数据集 这个例子使用的是鸢尾花数据集(Iris dataset),这是一个常用的

Fisher判别示例:鸢尾花(iris)数据(R)
先读取iris数据,再用程序包MASS(记得要在使用MASS前下载好该程序包)中的线性函数lda()作判别分析: data(iris) #读入数据iris #展示数据attach(iris) #用变量名绑定对应数据library(MASS) #加载MASS程序包ld=lda(Species~Sepal.Length+Sepal.Width+Petal.Len gth+Pe
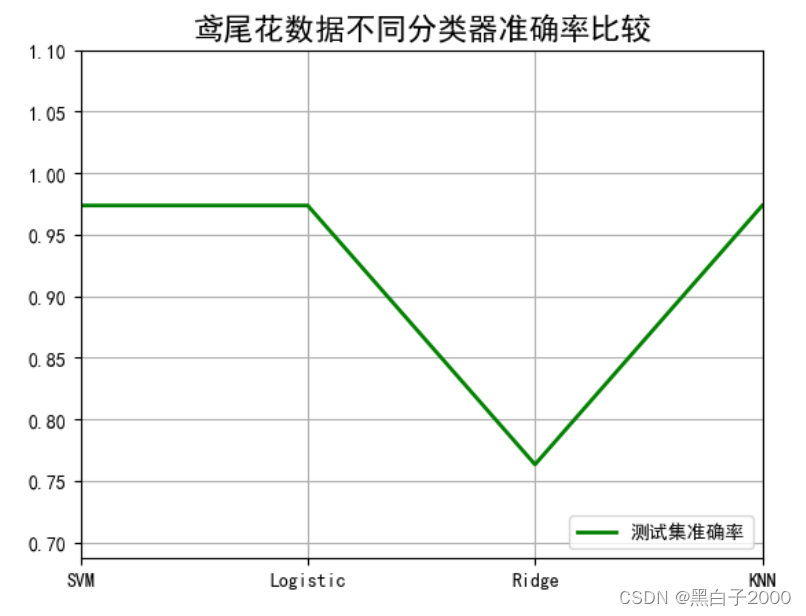
机器学习鸢尾花各种模型准确率对比
流程 获取数据集导入需要的包读取数据划分训练集和测试集调用各种模型比较准确率 获取数据集 链接:https://pan.baidu.com/s/1RzZyXsaiJB3e611itF466Q?pwd=j484 提取码:j484 --来自百度网盘超级会员V1的分享 导入需要的包 import pandas as pdimport numpy as npimport matplotl
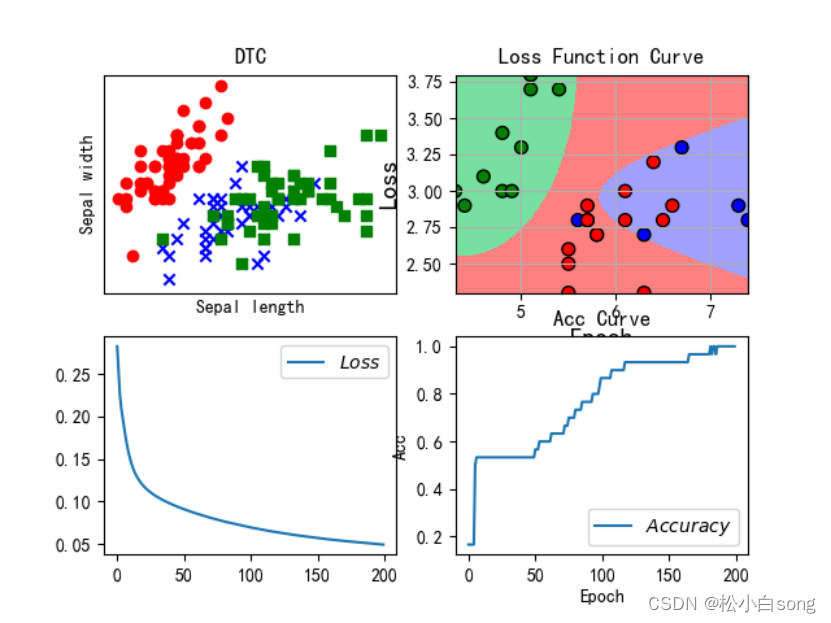
鸢尾花数据集分类(决策树,朴素贝叶斯,人工神经网络)
目录 一、决策树 二、朴素贝叶斯 三、人工神经网络 四、利用三种方法进行鸢尾花数据集分类 一、决策树 决策树是一种常用的机器学习算法,用于分类和回归任务。它是一种树形结构,其中每个内部节点表示一个特征或属性,每个分支代表这个特征的一个可能的取值,而每个叶子节点代表一个类别标签或者是一个数值。 决策树的构建过程通常包括以下几个步骤: 特征选择:根据某种准则选择最优的特征,使得

计算方法实验5:对鸢尾花数据集进行主成分分析(PCA)并可视化
任务 iris数据集包含150条数据,从iris.txt读取,每条数据有4个属性值和一个标签(标签取值为0,1,2)。要求对这150个4维数据进行PCA,可视化展示这些数据在前两个主方向上的分布,其中不同标签的数据需用不同的颜色或形状加以区分。 算法 m个n维数据向量去中心化后(各向量的每个维度减去这个维度在所有向量上均值),按列排列构成矩阵 X n × m \mathbf{X}_{n\ti

鸢尾花和月亮数据集,运用线性LDA、k-means和SVM算法进行二分类可视化分析
文章目录 一、线性LDA1.鸢尾花LDA2.月亮集LDA 二、K-means1.鸢尾花k-means2.月亮集k-means 三、SVM1.鸢尾花svm2.月亮集svm 四、SVM的优缺点优点缺点 五、参考文章 一、线性LDA 1.鸢尾花LDA import numpy as npimport matplotlib.pyplot as pltfrom sklearn imp
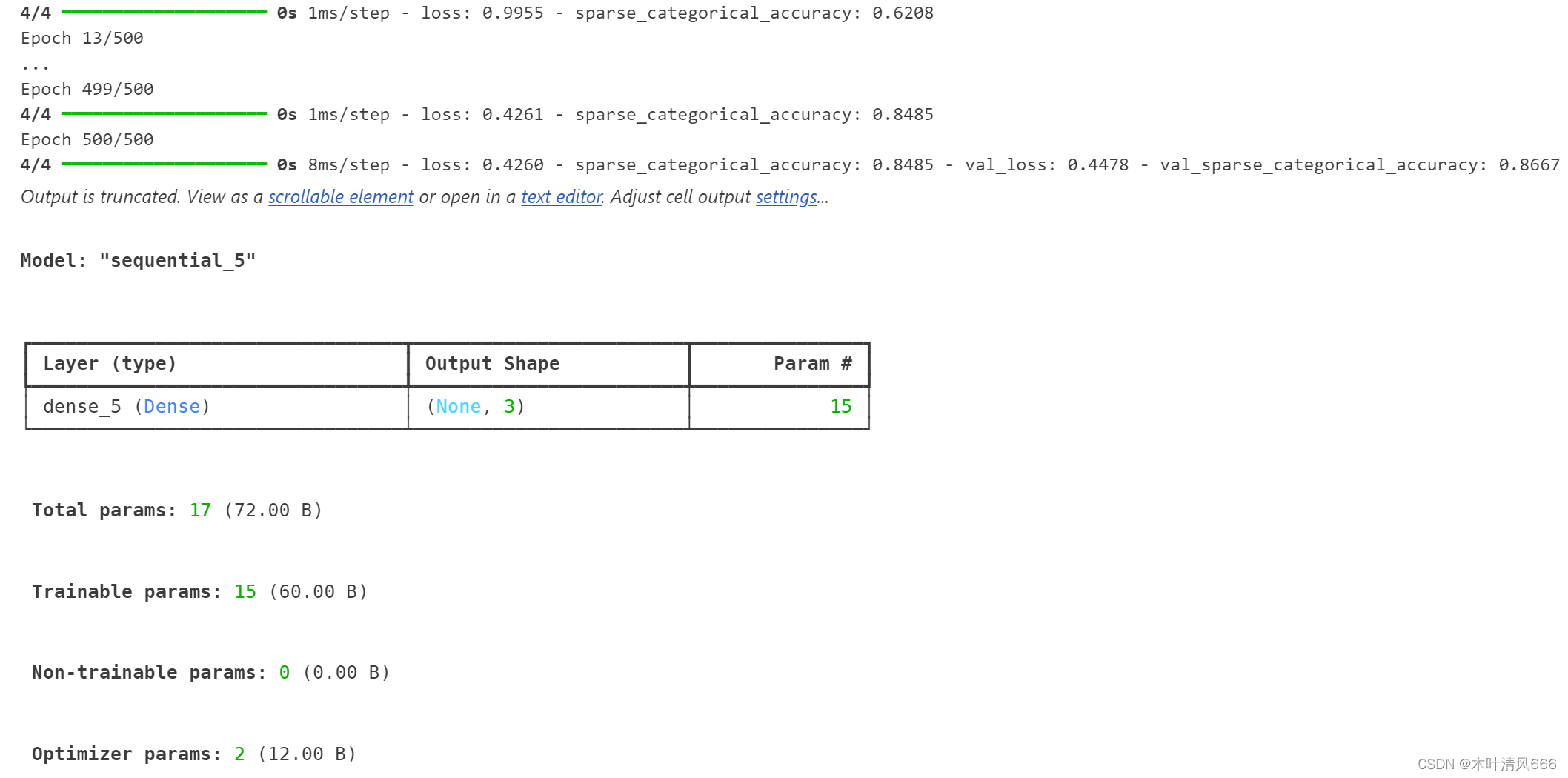
【tensorflow框架神经网络实现鸢尾花分类_Keras】
文章目录 1、前言2、鸢尾花分类3、结果打印 1、前言 【tensorflow框架神经网络实现鸢尾花分类】一文中使用自定义的方式,实现了鸢尾花数据集的分类工作。在这里使用tensorflow中的keras模块快速、极简实现鸢尾花分类任务。 2、鸢尾花分类 import tensorflow as tffrom sklearn import datasetsimport n
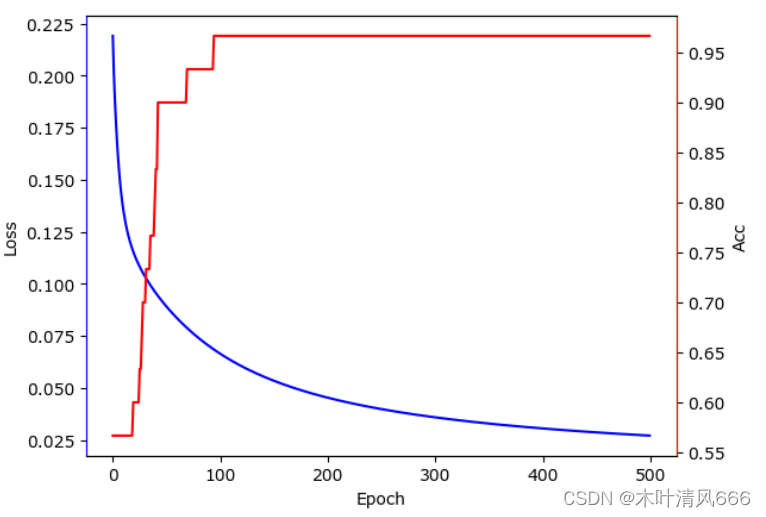
【tensorflow框架神经网络实现鸢尾花分类】
文章目录 1、数据获取2、数据集构建3、模型的训练验证可视化训练过程 1、数据获取 从sklearn中获取鸢尾花数据,并合并处理 from sklearn.datasets import load_irisimport pandas as pdx_data = load_iris().datay_data = load_iris().targetx_data = pd.Da

简洁明了的tensorflow2.0教程——实现鸢尾花分类
通过本文你可以学会神经网络最基本的用法,可以对tensorflow用法有初步的了解,实现神经网络入门,适用于有着在机器学习/或者深度学习有着理论基础,拥有一定python编程基础但是对神经网络实践缺少经验的coder,通过阅读并且自己完成本篇博客中的代码小白也能学会如何利用神经网络来实现简单的分类任务。这一讲源码在我的github,地址:https://github.com/JohnLeek/Te
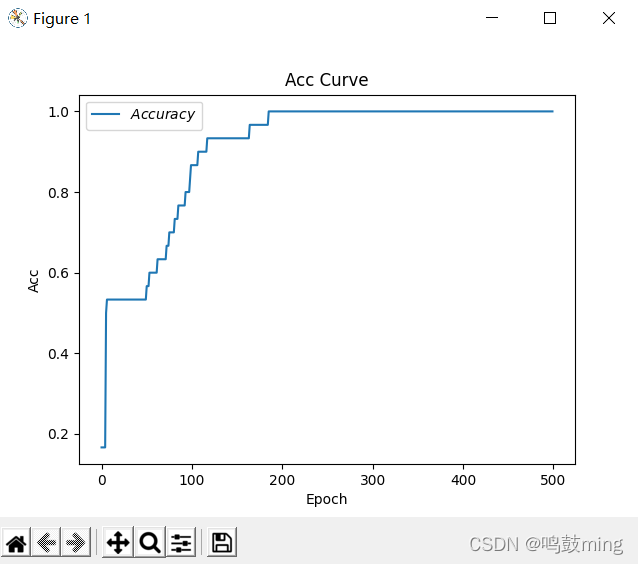
02-TensorFlow 神经网络实现鸢尾花分类
1.数据集介绍 共有数据150组,每组包括花萼长、花萼宽、花瓣长、花瓣宽4个输入特征。同时给出了,这一组特征对应的鸢尾花类别。类别包括Setosa Iris(狗尾草鸢尾),Versicolour Iris(杂色鸢尾),Virginica Iris(弗吉尼亚鸢尾)三类,分别用数字0,1,2表示。 2.准备数据 1.数据集读入 这个数据集可以通过代码直接从网上导入 from sklearn

使用BP神经网络对鸢尾花数据集分类
最近认识的一位大佬搭建的人工智能学习网站,内容通俗易懂,风趣幽默,感兴趣的可以去看看:床长人工智能教程 废话不多说,请看正文! 使用BP神经网络对鸢尾花数据集分类 from sklearn.datasets import load_irisfrom pandas import DataFrameimport pandas as pdx_data = load_iris(

【机器学习】P24 随机森林算法(1) 实现 “鸢尾花” 预测
随机森林算法 Random Forest Algorithm 随机森林算法随机森林算法实现分类鸢尾花 随机森林算法 随机森林(Random Forest)算法 是一种 集成学习(Ensemble Learning)方法,它由多个决策树组成,是一种分类、回归和特征选择的机器学习算法。 在随机森林中,每个决策树都是独立地训练的,每棵树的建立都是基于随机选取的 特征子集 和随机选取的
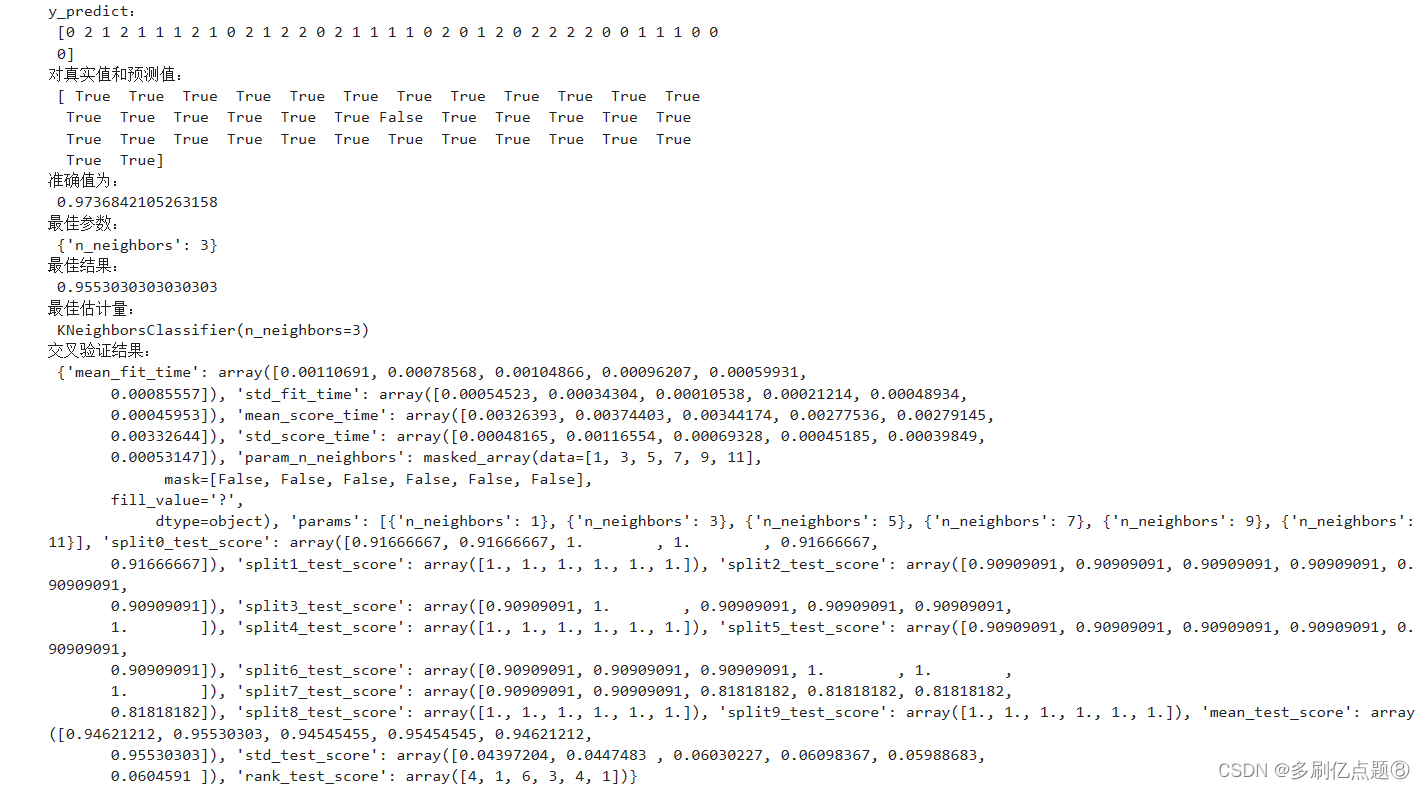
KNN算法对鸢尾花进行分类:添加网格搜索和交叉验证
优化——添加网格搜索和交叉验证 from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsCl

机器学习--KNN算法应用,iris鸢尾花数据集的分类
数据集介绍 Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过 花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类. 用KNN分类Iris数据集 from sklearn.datasets import loa

【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载
【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~ 💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
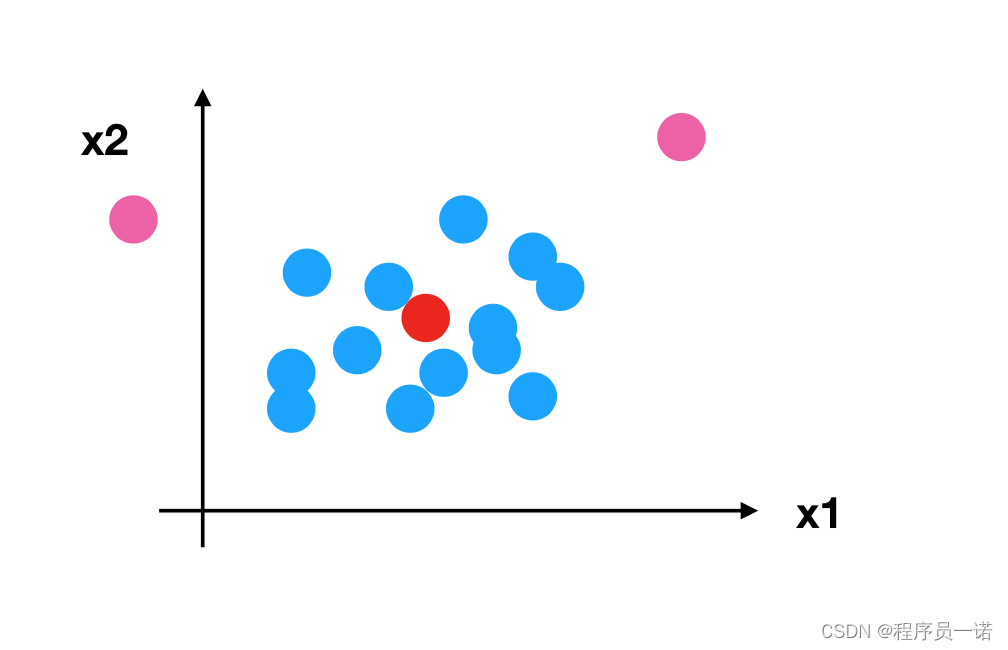
【机器学习算法】KNN鸢尾花种类预测案例和特征预处理。全md文档笔记(已分享,附代码)
本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回