dropout专题

深度学习100问49:基于Dropout的方法有哪些
嘿,朋友!来看看这些超酷的基于 Dropout 的方法吧。 一、标准 Dropout——让神经元“玩捉迷藏” 想象一下,神经网络就像一个热闹的游乐场,里面有很多好玩的游乐设施(神经元)。标准 Dropout 呢,就像是一个调皮的小精灵,它会时不时地蒙上一些游乐设施的眼睛,让它们暂时不能工作。这样其他游乐设施就得更努力地玩,不能只靠那几个被蒙住眼睛的。这样整个游乐场(神经网络)就会变得更有趣

人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】
人工智能:模型复杂度、模型误差、欠拟合、过拟合/泛化能力、过拟合的检测、过拟合解决方案【更多训练数据、Regularization/正则、Shallow、Dropout、Early Stopping】 一、模型误差与模型复杂度的关系1、梯度下降法2、泛化误差2.1 方差2.2 偏差2.3 噪声2.4 泛化误差的拆分 3、偏差-方差窘境(bias-variance dilemma)4、Bias

Pytorch实现多层LSTM模型,并增加emdedding、Dropout、权重共享等优化
简述 本文是 Pytorch封装简单RNN模型,进行中文训练及文本预测 一文的延申,主要做以下改动: 1.将nn.RNN替换为nn.LSTM,并设置多层LSTM: 既然使用pytorch了,自然不需要手动实现多层,注意nn.RNN和nn.LSTM 在实例化时均有参数num_layers来指定层数,本文设置num_layers=2; 2.新增emdedding层,替换掉原来的nn.funct

DL基础补全计划(四)---对抗过拟合:权重衰减、Dropout
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 Windows 10VSCodePython 3.8.10Pytorch 1.8.1Cuda 10.2 前言 在《DL基础补全计划(三)—模型选择、欠拟合、过拟合》( https://blog.csdn.net/u011728480/article/d

Caffe Prototxt 特征层系列:Dropout Layer
Dropout Layer作用是随机让网络的某些节点不工作(输出置零),也不更新权重;是防止模型过拟合的一种有效方法 首先我们先看一下 DropoutParameter message DropoutParameter {optional float dropout_ratio = 1 [default = 0.5]; // dropout ratio } InnerProduct l

从零实现ChatGPT:第二章备使用注意力Dropout减少过拟合
准备深入学习transformer,并参考一些资料和论文实现一个大语言模型,顺便做一个教程,今天是第二部分。 本系列禁止转载,主要是为了有不同见解的同学可以方便联系我,我的邮箱 fanzexuan135@163.com 使用注意力Dropout减少过拟合 在上一节中,我们通过在注意力权重矩阵中应用因果注意力掩码,实现了因果注意力机制。除了因果注意力掩码之外,我们还可以添加一个Dropout掩码

【深度学习笔记3.2 正则化】Dropout
关于dropout的理解与总结: dropout是什么?参考文献[1]dropout会让train变差,让test变好。一般的如果在train-set上表现好,在test-set上表现差,用dropout才有效果。使用dropout是为了避免过拟合。(来自网友)下图来自文献[3] 上图中的思想就是说:Dropout是一种正则化技术,是防止过拟合最有效的方法,然而在以下几种情况下使用drop
【深度学习】之 卷积(Convolution2D)、最大池化(Max Pooling)和 Dropout 的NumPy实现
1. 2D 卷积操作 import numpy as npdef conv2d(image, kernel, stride=1, padding=0):"""应用2D卷积操作到输入图像上。参数:- image: 输入图像,2D数组。- kernel: 卷积核,2D数组。- stride: 卷积步幅。- padding: 图像周围的零填充数量。返回值:- output: 卷积操作的结果。"""#

正则化和dropout
1. 过拟合 先来说说什么是过拟合,在Andrew Ng的ML课程中有这么一段描述。 使用一次曲线拟合房价,发现效果并不好,出现欠拟合,是high bias,训练数据不够充分。使用二次曲线拟合房价,刚好合适。使用高阶曲线拟合,每个点都很完美,这时过拟合出现了,产生了high variance,过度训练数据,使得泛化性能很差。用Bengio在Deep Learning中的这个图来阐述什么是过拟合

如何在MXNet中使用channel Dropout (Dropout2d)
在很多实际使用场景下,特别是语义分割等输出像素级预测结果的全卷积神经网络中,经常会使用到随机drop特征图维度的操作。在Pytorch中,可以直接使用torch.nn.Dropout2d实现相应功能。然而在MXNet中可能略显麻烦。 查阅MXNet文档并不能直接找到所需的信息,因为Dropout模块被定义为了最基础版本的、随机drop数组中任意元素的功能。唯一可能与需求相关的参数’axes’,其

理解dropout(转)
原文链接:https://blog.csdn.net/stdcoutzyx/article/details/49022443 理解dropout 注意:图片都在github上放着,如果刷不开的话,可以考虑翻墙。转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/49022443 开篇明义,dropout是指在深度学习网络的训练过程中

深度学习基础:循环神经网络中的Dropout
深度学习基础:循环神经网络中的Dropout 在深度学习中,过拟合是一个常见的问题,特别是在循环神经网络(RNN)等复杂模型中。为了应对过拟合问题,研究者们提出了许多方法,其中一种被广泛应用的方法是Dropout。本文将介绍Dropout的概念、原理以及在循环神经网络中的应用,并用Python实现一个示例来演示Dropout的效果。 1. 概述 Dropout是一种用于深度学习模型的正则化技

Dropout Feature Ranking for Deep Learning Models
摘要 深度神经网络( deep neural networks,DNNs )在多个领域取得了最新的研究成果。不幸的是,DNNs因其不可解释性而臭名昭著,从而限制了其在生物和医疗保健等假说驱动领域的适用性。此外,在资源受限的环境下,设计依赖更少信息特征的测试是至关重要的,这将在合理的预算范围内实现高精度的性能。我们旨在通过提出一种新的面向深度学习的通用特征排序方法来弥合这一差距。我们展示了我们的简
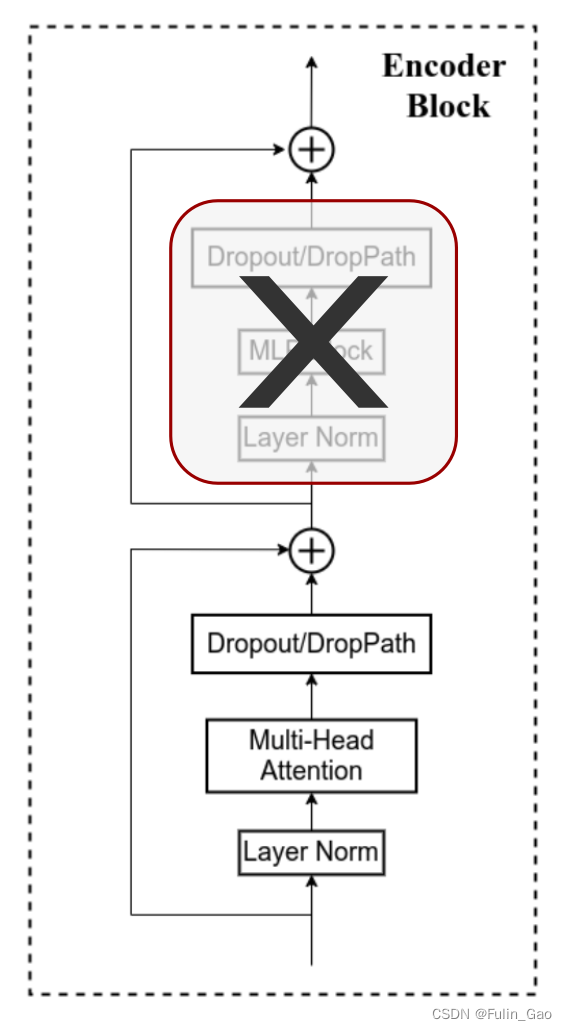
【深度学习】Dropout、DropPath
一、Dropout 1. 概念 Dropout 在训练阶段会让当前层每个神经元以drop_prob( 0 ≤ drop_prob ≤ 1 0\leq\text{drop\_prob}\leq1 0≤drop_prob≤1)的概率失活并停止工作,效果如下图。 在测试阶段不会进行Dropout。由于不同批次、不同样本的神经元失活情况不同,测试时枚举所有情况进行推理是不现实的,所以原文使

35_pytorch 过拟合解决办法 (Early Stop, Dropout)
关于"深度学习过拟合解决方案": https://blog.csdn.net/tototuzuoquan/article/details/113802684?spm=1001.2014.3001.5501 对于深度学习网络的过拟合,一般的解决方案有: Early stop 在模型训练过程中,提前终止。这里可以根据具体指标设置early stop的条件,比如可以是loss的大小,或者acc/f1

一篇文章详解深度学习正则化方法(L1、L2、Dropout正则化相关概念、定义、数学公式、Python代码实现)
目录 一、什么是正则化? 二、正则化的作用? 三、常见的正则化方法 四、详解L1正则化 五、详解L2正则化 六、详解Dropout方法 总结: 博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦
2024-04-09 问AI: 在深度学习中,dropout层是什么?
文心一言 在深度学习中,Dropout层是一种正则化技术,用于防止神经网络过拟合。它通过在训练过程中随机地将一部分神经元的输出设置为0,来减少神经元之间的复杂共适应性,使得模型更加健壮,提高泛化能力。 具体来说,Dropout层在训练过程中会以一定的概率(通常设置为0.5)将神经元的输出置为0。这意味着在前向传播时,每次迭代都会有一部分神经元不参与计算,从而减少了神经元之间的依赖关系。而在测试

6.4 Dropout正则化
1、Dropout Dropout是一种正则化技术,通过防止特征的协同适应,可用于减少神经网络中的过拟合。 Dropout的效果非常好,实现简单且不会降低网络速度,被广泛使用。 特征的协同适应指的是在训练模型时,共同训练的神经元为了相互弥补错误,而相互关联的现象,在神经网络中这种现象会变得尤其复杂。 协同适应会转而导致模型的过度拟合,因为协同适应的现象并不会泛化未曾见过的数据。 Drop
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! Dropout和批归一化是深度学习领域中常用的正则化技术,旨在提高模型的泛化能力和防止过拟合。 Dropout是由Hinton等人在2012年提出的一种正则化技术。它通过在训练过程中随机地将一部分神经元的输出
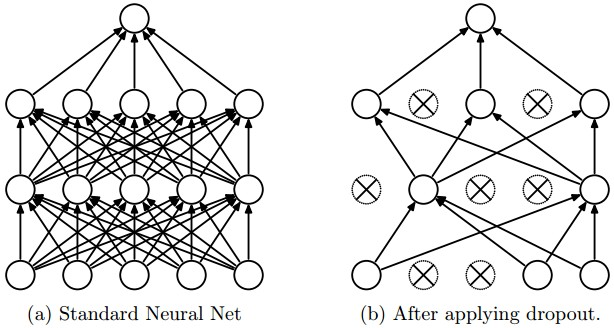
李理:卷积神经网络之Dropout
本系列文章面向深度学习研发者,希望通过Image Caption Generation,一个有意思的具体任务,深入浅出地介绍深度学习的知识。本系列文章涉及到很多深度学习流行的模型,如CNN,RNN/LSTM,Attention等。本文为第11篇。 作者:李理 目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。 相
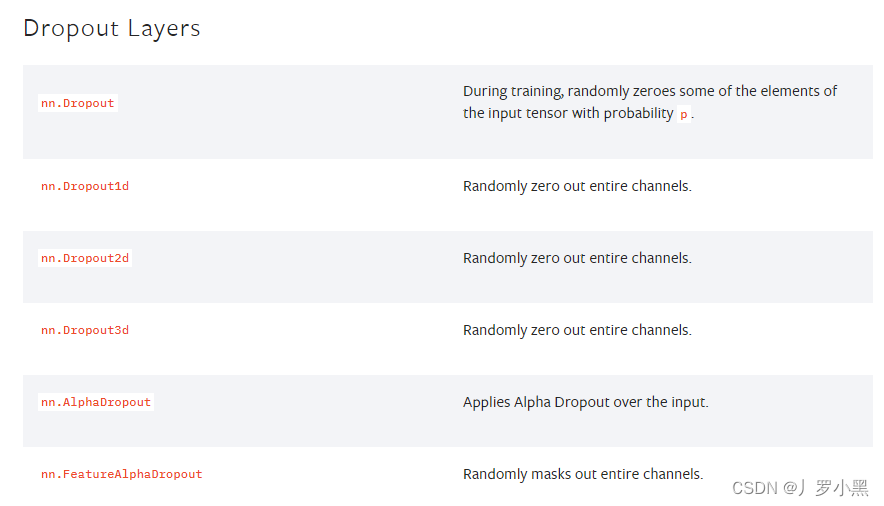
Pytorch学习 day08(最大池化层、非线性激活层、正则化层、循环层、Transformer层、线性层、Dropout层)
最大池化层 最大池化,也叫上采样,是池化核在输入图像上不断移动,并取对应区域中的最大值,目的是:在保留输入特征的同时,减小输入数据量,加快训练。参数设置如下: kernel_size:池化核的高宽(整数或元组),整数时表示高宽都为该整数,元组时表示分别在水平和垂直方向上的长度。stride:池化核每次移动的步长(整数或元组),整数时表示在水平和垂直方向上使用相同的步长。元组时分别表示在水平和垂直
鲸鱼算法优化LSTM超参数-神经元个数-dropout-batch_size
1、摘要 本文主要讲解:使用鲸鱼算法优化LSTM超参数-神经元个数-dropout-batch_size 主要思路: 鲸鱼算法 Parameters : 迭代次数、鲸鱼的维度、鲸鱼的数量, 参数的上限,参数的下限LSTM Parameters 神经网络第一层神经元个数、神经网络第二层神经元个数、dropout比率、batch_size开始搜索:初始化所鲸鱼的位置、迭代寻优、返回超出搜索空间边界

data augmentation and dropout
在深度学习方法中,更多的训练数据,意味着可以用更深的网络,训练出更好的模型。 方法: (1)将原始图片旋转一个小角度 (2)添加随机噪声 (3)一些有弹性的畸变(elastic distortions) (4)截取(crop)原始图片的一部分。 Dropout则是通过修改神经网络本身来实现的,它是在训练网络时用的一种技巧(trike)。它的流程如下 假设我们要训练上图这个网络,在

《Single-step Adversarial training with Dropout Scheduling》 论文笔记
Abstract 在对抗训练中,mini-batches 通过对抗样本进行数据增强,然后在进行训练。通常使用快速、简单的方法来生成对抗样本,目的是减少计算复杂度。然而使用单步对抗训练方法训练的模型的鲁棒性是伪性的。 本文的工作中,作者表明了使用单步对抗训练方法训练的模型会逐渐学习避免单步对抗的产生,这是因为模型在初始训练阶段的过拟合。为了减小这种现象,作者提出了一个带有dropout sched