本文主要是介绍李理:卷积神经网络之Dropout,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本系列文章面向深度学习研发者,希望通过Image Caption Generation,一个有意思的具体任务,深入浅出地介绍深度学习的知识。本系列文章涉及到很多深度学习流行的模型,如CNN,RNN/LSTM,Attention等。本文为第11篇。
作者:李理
目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。相关文章:
李理:从Image Caption Generation理解深度学习(part I)
李理:从Image Caption Generation理解深度学习(part II)
李理:从Image Caption Generation理解深度学习(part III)
李理:自动梯度求解 反向传播算法的另外一种视角
李理:自动梯度求解——cs231n的notes
李理:自动梯度求解——使用自动求导实现多层神经网络
李理:详解卷积神经网络
李理:Theano tutorial和卷积神经网络的Theano实现 Part1
李理:Theano tutorial和卷积神经网络的Theano实现 Part2
李理:卷积神经网络之Batch Normalization的原理及实现
上文介绍了Batch Normalization技术。Batch Normalization是加速训练收敛速度的非常简单但又好用的一种实用技术,下面我们介绍可以提高模型的泛化能力的DropOut技术。
4. Dropout
4.1 Dropout简介
dropout是一种防止模型过拟合的技术,这项技术也很简单,但是很实用。它的基本思想是在训练的时候随机的dropout(丢弃)一些神经元的激活,这样可以让模型更鲁棒,因为它不会太依赖某些局部的特征(因为局部特征有可能被丢弃)。
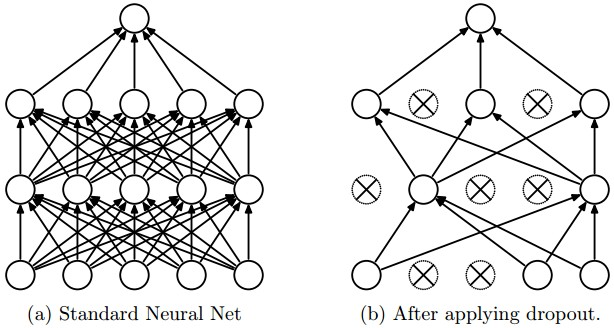
上图a是标准的一个全连接的神经网络,b是对a应用了dropout的结果,它会以一定的概率(dropout probability)随机的丢弃掉一些神经元。
4.2 Dropout的实现
实现Dropout最直观的思路就是按照dropout的定义来计算,比如上面的3层(2个隐藏层)的全连接网络,我们可以这样实现:
""" 最原始的dropout实现,不推荐使用 """p = 0.5 # 保留一个神经元的概率,这个值越大,丢弃的概率就越小。def train_step(X): H1 = np.maximum(0, np.dot(W1, X) + b1)U1 = np.random.rand(*H1.shape) < p # first dropout maskH1 *= U1 # drop!H2 = np.maximum(0, np.dot(W2, H1) + b2)U2 = np.random.rand(*H2.shape) < p # second dropout maskH2 *= U2 # drop!out = np.dot(W3, H2) + b3# 反向梯度计算,代码从略def predict(X):H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activationsH2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activationsout = np.dot(W3, H2) + b3我们看函数 train_step,正常计算第一层的激活H1之后,我们随机的生成dropout mask数组U1。它生成一个0-1之间均匀分布的随机数组,然后把小于p的变成1,大于p的变成0。极端的情况,p = 0,则所有数都不小于p,因此U1全是0;p=1,所有数都小于1,因此U1全是1。因此越大,U1中1越多,也就keep的越多,反之则dropout的越多。
然后我们用U1乘以H1,这样U1中等于0的神经元的激活就是0,其余的仍然是H1。
第二层也是一样的道理。
predict函数我们需要注意一下。因为我们训练的时候
这篇关于李理:卷积神经网络之Dropout的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









