本文主要是介绍鲸鱼算法优化LSTM超参数-神经元个数-dropout-batch_size,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、摘要
本文主要讲解:使用鲸鱼算法优化LSTM超参数-神经元个数-dropout-batch_size
主要思路:
- 鲸鱼算法 Parameters : 迭代次数、鲸鱼的维度、鲸鱼的数量, 参数的上限,参数的下限
- LSTM Parameters 神经网络第一层神经元个数、神经网络第二层神经元个数、dropout比率、batch_size
- 开始搜索:初始化所鲸鱼的位置、迭代寻优、返回超出搜索空间边界的搜索代理、计算每个搜索代理的目标函数、更新 Alpha, Beta, and Delta
- 训练模型,使用鲸鱼算法找到的最好的全局最优参数
- plt.show()
2、数据介绍
zgpa_train.csv
DIANCHI.csv
需要数据的话去我其他文章的评论区
可接受定制
3、相关技术
WOA算法设计的既精妙又富有特色,它源于对自然界中座头鲸群体狩猎行为的模拟, 通过鲸鱼群体搜索、包围、追捕和攻击猎物等过程实现优时化搜索的目的。在原始的WOA中,提供了包围猎物,螺旋气泡、寻找猎物的数学模型。

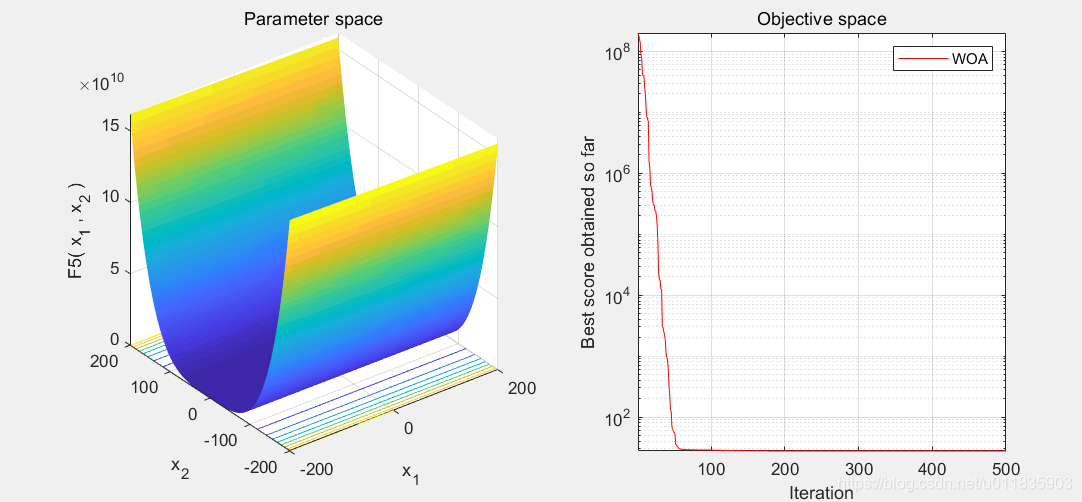
PS:如陷入局部最优建议修改参数的上下限或者修改鲸鱼寻优的速度
4、完整代码和步骤
代码输出如下:
此程序运行代码版本为:
tensorflow==2.5.0
numpy==1.19.5
keras==2.6.0
matplotlib==3.5.2
主运行程序入口
import math
import osimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from tensorflow.python.keras.callbacks import EarlyStopping
from tensorflow.python.keras.layers import Dense, Dropout, LSTM
from tensorflow.python.keras.layers.core import Activation
from tensorflow.python.keras.models import Sequentialos.chdir(r'D:\项目\PSO-LSTM\具体需求')
'''
灰狼算法优化LSTM
'''
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号def creat_dataset(dataset, look_back):dataX, dataY = [], []for i in range(len(dataset) - look_back - 1):a = dataset[i: (i + look_back)]dataX.append(a)dataY.append(dataset[i + look_back])return np.array(dataX), np.array(dataY)dataframe = pd.read_csv('zgpa_train.csv', header=0, parse_dates=[0], index_col=0, usecols=[0, 5], squeeze=True)
dataset = dataframe.values
data = pd.read_csv('DIANCHI.csv', header=0)
z = data['fazhi']scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
look_back = 10
trainX, trainY = creat_dataset(train, look_back)
testX, testY = creat_dataset(test, look_back)def build_model(neurons1, neurons2, dropout):X_train, y_train = trainX, trainYX_test, y_test = testX, testYmodel = Sequential()model.add(LSTM(units=neurons1, return_sequences=True, input_shape=(10, 1)))model.add(LSTM(units=neurons2, return_sequences=True))model.add(LSTM(111, return_sequences=False))model.add(Dropout(dropout))model.add(Dense(55))model.add(Dense(units=1))model.add(Activation('relu'))model.compile(loss='mean_squared_error', optimizer='Adam')return model, X_train, y_train, X_test, y_testdef training(X):neurons1 = int(X[0])neurons2 = int(X[1])dropout = round(X[2], 6)batch_size = int(X[3])print([neurons1,neurons2,dropout,batch_size])model, X_train, y_train, X_test, y_test = build_model(neurons1, neurons2, dropout)model.fit(X_train,y_train,batch_size=batch_size,epochs=10,validation_split=0.1,verbose=0,callbacks=[EarlyStopping(monitor='val_loss', patience=22, restore_best_weights=True)])pred = model.predict(X_test)temp_mse = mean_squared_error(y_test, pred)print(temp_mse)return temp_mseclass woa():# 初始化def __init__(self, LB, UB, dim=4, b=1, whale_num=20, max_iter=500):self.LB = LBself.UB = UBself.dim = dimself.whale_num = whale_numself.max_iter = max_iterself.b = b# Initialize the locations of whaleself.X = np.random.uniform(0, 1, (whale_num, dim)) * (UB - LB) + LBself.gBest_score = np.infself.gBest_curve = np.zeros(max_iter)self.gBest_X = np.zeros(dim)# 适应度函数 max_depth,min_samples_split,min_samples_leaf,max_leaf_nodesdef fitFunc(self, para):# 建立模型mse = training(para)return mse# 优化模块def opt(self):t = 0while t < self.max_iter:print('At iteration: ' + str(t))for i in range(self.whale_num):# 防止X溢出self.X[i, :] = np.clip(self.X[i, :], self.LB, self.UB) # Check boundriesfitness = self.fitFunc(self.X[i, :])# Update the gBest_score and gBest_Xif fitness <= self.gBest_score:self.gBest_score = fitnessself.gBest_X = self.X[i, :].copy()print('self.gBest_score: ', self.gBest_score)print('self.gBest_X: ', self.gBest_X)a = 2 * (self.max_iter - t) / self.max_iter# Update the location of whalesfor i in range(self.whale_num):p = np.random.uniform()R1 = np.random.uniform()R2 = np.random.uniform()A = 2 * a * R1 - aC = 2 * R2l = 2 * np.random.uniform() - 1# 如果随机值大于0.5 就按以下算法更新Xif p >= 0.5:D = abs(self.gBest_X - self.X[i, :])self.X[i, :] = D * np.exp(self.b * l) * np.cos(2 * np.pi * l) + self.gBest_Xelse:# 如果随机值小于0.5 就按以下算法更新Xif abs(A) < 1:D = abs(C * self.gBest_X - self.X[i, :])self.X[i, :] = self.gBest_X - A * Delse:rand_index = np.random.randint(low=0, high=self.whale_num)X_rand = self.X[rand_index, :]D = abs(C * X_rand - self.X[i, :])self.X[i, :] = X_rand - A * Dself.gBest_curve[t] = self.gBest_scoret += 1return self.gBest_curve, self.gBest_Xif __name__ == '__main__':'''神经网络第一层神经元个数神经网络第二层神经元个数dropout比率batch_size'''# ===========主程序================Max_iter = 3 # 迭代次数dim = 4 # 鲸鱼的维度SearchAgents_no = 2 # 寻值的鲸鱼的数量# 参数的上限UB = np.array([20, 100, 0.01, 36])# 参数的下限LB = np.array([5, 20, 0.00001, 5])# best_params is [2.e+02 3.e+02 1.e-03 1.e+00]fitnessCurve, para = woa(LB, UB, dim=dim, whale_num=SearchAgents_no, max_iter=Max_iter).opt()print('best_params is ', para)# 训练模型 使用PSO找到的最好的神经元个数neurons1 = int(para[0])neurons2 = int(para[1])dropout = para[2]batch_size = int(para[3])model, X_train, y_train, X_test, y_test = build_model(neurons1, neurons2, dropout)history = model.fit(X_train, y_train, epochs=100, batch_size=batch_size, validation_split=0.2, verbose=1,callbacks=[EarlyStopping(monitor='val_loss', patience=29, restore_best_weights=True)])trainPredict = model.predict(trainX)testPredict = model.predict(testX)trainPredict = scaler.inverse_transform(trainPredict)trainY = scaler.inverse_transform(trainY)testPredict = scaler.inverse_transform(testPredict)testY = scaler.inverse_transform(testY)trainScore = math.sqrt(mean_squared_error(trainY, trainPredict[:, 0]))# print('Train Score %.2f RMSE' %(trainScore))testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))# print('Test Score %.2f RMSE' %(trainScore))trainPredictPlot = np.empty_like(dataset)trainPredictPlot[:] = np.nantrainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))trainPredictPlot[look_back: len(trainPredict) + look_back, :] = trainPredicttestPredictPlot = np.empty_like(dataset)testPredictPlot[:] = np.nantestPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))testPredictPlot[len(trainPredict) + (look_back * 2) + 1: len(dataset) - 1, :] = testPredictplt.plot(history.history['loss'])plt.title('model loss')plt.ylabel('loss')plt.xlabel('epoch')plt.show()fig2 = plt.figure(figsize=(20, 15))plt.rcParams['font.family'] = ['STFangsong']ax = plt.subplot(222)plt.plot(scaler.inverse_transform(dataset), 'b-', label='实验数据')plt.plot(trainPredictPlot, 'r', label='训练数据')plt.plot(testPredictPlot, 'g', label='预测数据')plt.plot(z, 'k-', label='寿命阀值RUL')plt.ylabel('capacity', fontsize=20)plt.xlabel('cycle', fontsize=20)plt.legend()name = 'neurons1_' + str(neurons1) + 'neurons2_' + str(neurons2) + '_dropout' + str(dropout) + '_batch_size' + str(batch_size)plt.savefig('D:\项目\PSO-LSTM\具体需求\photo\\' + name + '.png')plt.show()这篇关于鲸鱼算法优化LSTM超参数-神经元个数-dropout-batch_size的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



