本文主要是介绍35_pytorch 过拟合解决办法 (Early Stop, Dropout),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于"深度学习过拟合解决方案":
https://blog.csdn.net/tototuzuoquan/article/details/113802684?spm=1001.2014.3001.5501
对于深度学习网络的过拟合,一般的解决方案有:
Early stop
在模型训练过程中,提前终止。这里可以根据具体指标设置early stop的条件,比如可以是loss的大小,或者acc/f1等值的epoch之间的大小对比。
More data
更多的数据集。增加样本也是一种解决方案,根据不同场景和数据不同的数据增强方法。
正则化
常用的有L1,L2正则化
Droup Out
以一定的概率使某些神经元停止工作
BatchNorm
对神经元作归一化
1.32.Early Stop, Dropout
1.32.1.Early Stopping
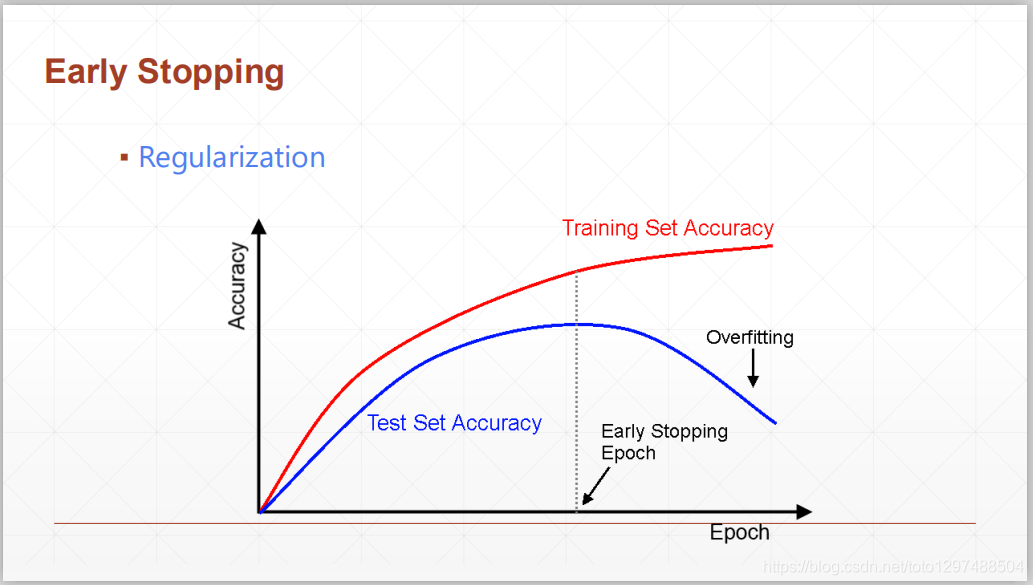
Early Stop的概念非常简单,在我们一般训练中,经常由于过拟合导致在训练集上的效果好,而在测试集上的效果非常差。因此我们可以让训练提前停止,在测试集上达到最好的效果时候就停止训练,而不是等到在训练集上饱和再停止,这个操作叫做Early Stop
随着横坐标epoch的进行,train部分的accuracy持续上升,train部分的accuracy增加到临时点后会开始发生over fitting现象,我们一般使用Validation来对临界点进行检测。在取到最大值时便停止调test,将此时取得的参数保存用来做最终的模型参数。
可注意到train若不停止会进行无限长的时间,Early stop的引入会提前终止训练,即在test accuracy上升到临界值不发生改变后,就停止训练。
由此我们总结Early stop有以下特点:
1.通过Validation set来选择合适的参数
2.通过Validation来进行检测模型优化表现
3.在最高的Val performance(表现时)停止优化
Early Stop的过程

1.32.2.Dropout
Dropout是用来防止Overfitting十分有效的手段,其思路构建假设为:
1.不全部学习参数,只学习有效的参数
2.每层链接都有一定的概率”丢失”
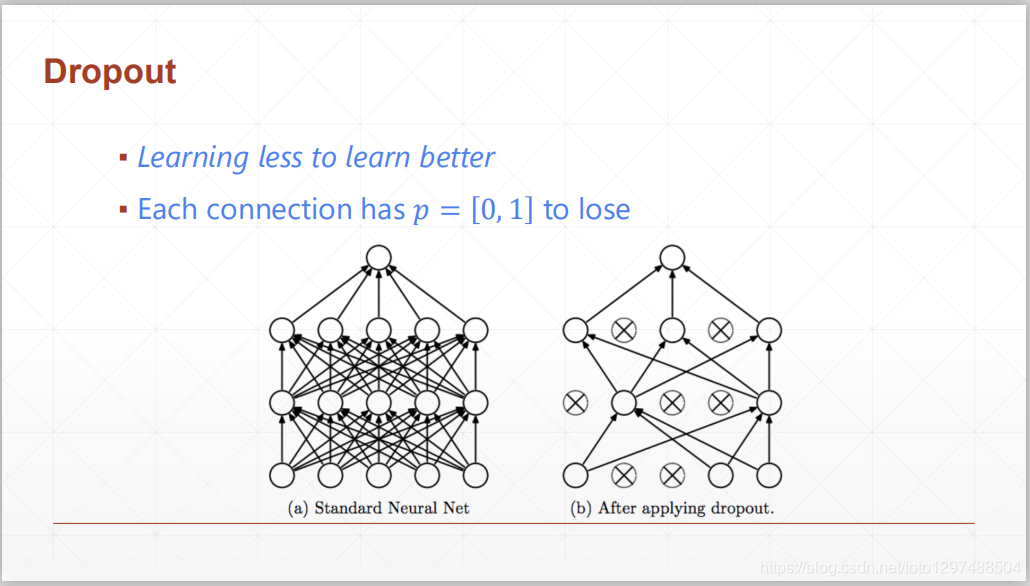
通过”丢失”链接后,有效的减少运算量,使优化更为平滑
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
在2012年,Alex、Hinton在其论文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止过拟合。并且,这篇论文提到的AlexNet网络模型引爆了神经网络应用热潮,并赢得了2012年图像识别大赛冠军,使得CNN成为图像分类上的核心算法模型。
随后,又有一些关于Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
从上面的论文中,我们能感受到Dropout在深度学习中的重要性。那么,到底什么是Dropout呢?
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特殊检测器(隐层节点)间的相互作用,检测器相互作用的是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的**值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如上图所示。
# -*- coding: UTF-8 -*-import torchnet_dropped = torch.nn.Sequential(torch.nn.Linear(784, 200),torch.nn.Dropout(0.5), # drop 50% of the neurontorch.nn.ReLU(),torch.nn.Linear(200, 200),torch.nn.Dropout(0.5), # drop 50% of the neurontorch.nn.ReLU(),torch.nn.Linear(200, 10),
)
pytorch与tensorflow中Dropout函数的区别
torch.nn.Dropout(p=dropout_prob)tf.nn.dropout(keep_prob)
值得注意的是pytorch中传入的参数丢弃权重参数的概率:
而在tensorflow中传入的参数是保持权重参数的概率,两者的关系是相加为1.
Behavior between train and test
for epoch in range(epochs):# trainnet_dropped.train()for batch_idx, (data, target) in enumerate(train_loader):...net_dropped.eval()test_loss = 0correct = 0for data, target in test_loader:...
model.train() :启用 BatchNormalization 和 Dropout
model.eval(): 不启用BatchNormalization和Dropout
在训练集中我们在训练模型的过程中需要引入Dropout让模型具备更加强大的泛化能力。而在测试集中,则不需要在测试的时候也进行Dropout。否则会降低模型的表现能力。所以需要添加语句net_dropout.eval(),表示切换到不启用Dropout模式,再利用测试集测试模型性能。
1.32.3.SGD随机梯度下降
(1)SGD与确定性模型和随机模型的区别
Stochastic Gradient Descent

不同于一般的随机,SGD中的随机其实是符合一定函数分布,如正态分布这种,这种随机也不同于一般的Deterministic Model(确定性模型),确定性模型相当于一个f(x),有什么样的输入就会有相应的输出。
(2)SGD和经典梯度下降算法区别


为了解决经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据。当M很大的时候,就需要耗费巨大的计算资源和计算时间这个弊端,因此引入了SGD(随机梯度下降算法)
随机梯度下降法用单个训练数据即可对模型参数进行一次更新,大大加快了训练速度。
为了降低随机梯度的方差,从而使得迭代算法更加稳定,也为了充分利用高度优化的矩阵运算操作,在实际操作中,我们会同时处理若干训练数据,也就是指定的一个Batchsize,这种SGD叫做BGD。
这篇关于35_pytorch 过拟合解决办法 (Early Stop, Dropout)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






