critic专题

强化学习第十章:Actor-Critic 方法
强化学习第十章:Actor-Critic 方法 什么叫Actor-Critic最简单的AC,QAC(Q Actor-Critic)优势函数的AC,A2C(Advantage Actor-Critic)异策略AC,Off-Policy AC确定性策略梯度,DPG总结参考资料 什么叫Actor-Critic 一句话,策略由动作来执行,执行者叫Actor,评价执行好坏的叫Critic(

LLM agentic模式之reflection:SELF-REFINE、Reflexion、CRITIC
SELF-REFINE SELF-REFINE出自2023年3月的论文《Self-Refine: Iterative Refinement with Self-Feedback》,考虑到LLM第一次生成结果可能不是最好的输出,提出一种包括反馈(feedback)和改善(refinement)两个步骤的迭代方法来改进LLM的初始输出。 基本思路 对于输入,SELF-REFINE让LLM生成一个

【TensorFlow深度学习】实现Actor-Critic算法的关键步骤
实现Actor-Critic算法的关键步骤 实现Actor-Critic算法的关键步骤:强化学习中的双剑合璧Actor-Critic算法简介关键实现步骤代码示例(使用TensorFlow)结语 实现Actor-Critic算法的关键步骤:强化学习中的双剑合璧 在强化学习的广阔天地中,Actor-Critic算法以独特的双轨制胜场,融合了价值方法的稳健性和策略梯度方法的直接性

O2O:Offline–Online Actor–Critic
IEEE TAI 2024 paper 加权TD3_BC Method 离线阶段,算法基于TD3_BC,同时加上基于Q函数的权重函数,一定程度上避免了过估计 J o f f l i n e ( θ ) = E ( s , a ) ∼ B [ ζ Q ϕ ( s , π θ ( s ) ) ] − ∥ π θ ( s ) − a ∥ 2 \begin{aligned}J_{\mathrm{of

Actor-critic学习笔记-李宏毅
Policy Gradient review ∇ R ‾ θ = 1 N ∑ n = 1 N ∑ t = 1 T n ( ∑ t ′ = t T n γ t ′ − t r t ′ n − b ) ∇ log p θ ( a t n ∣ s t n ) \nabla \overline{R}_\theta = \frac{1}{N}\sum_{n = 1}^{N}\sum_{t = 1}^{
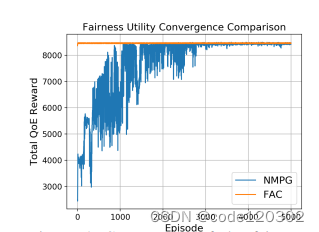
【强化学习】公平性Actor-Critic算法
Bringing Fairness to Actor-Critic Reinforcement Learning for Network Utility Optimization 阅读笔记 Problem FormulationLearning AlgorithmLearning with Multiplicative-Adjusted RewardsSolving Fairness Uti

强化学习原理python篇08——actor-critic
强化学习原理python篇08——actor-critic 前置知识TD ErrorREINFORCEQACAdvantage actor-critic (A2C) torch实现步骤第一步第二步第三步训练结果 Ref 本章全篇参考赵世钰老师的教材 Mathmatical-Foundation-of-Reinforcement-Learning Actor-Critic Metho

SAC(Soft Actor-Critic)理论与代码解释
标题 理论序言基础Q值与V值算法区别 SAC概念Q函数与V函数最大化熵强化学习(Maximum Entropy Reinforcement Learning, MERL)算法流程1个actor,4个Q Critic1个actor,2个V Critic,2个Q Critic 代码详解Actor网络理论中的训练策略 π( ϕ \phi ϕ) 时的损失函数:Q函数训练时的损失函数:温度系数的

JoyRL Actor-Critic算法
策略梯度算法的缺点 这里策略梯度算法特指蒙特卡洛策略梯度算法,即 REINFORCE 算法。 相比于 DQN 之类的基于价值的算法,策略梯度算法有以下优点。 适配连续动作空间。在将策略函数设计的时候我们已经展开过,这里不再赘述。适配随机策略。由于策略梯度算法是基于策略函数的,因此可以适配随机策略,而基于价值的算法则需要一个确定的策略。此外其计算出来的策略梯度是无偏的,而基于价值的算法则是有偏的
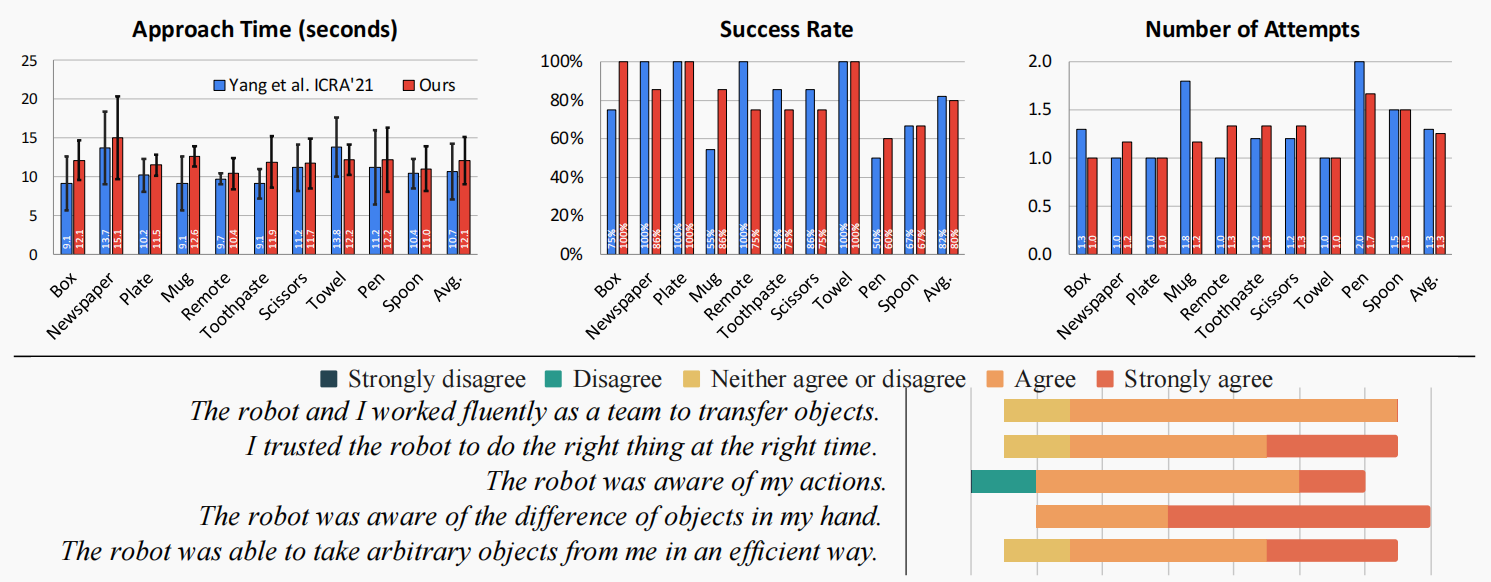
论文笔记(四十)Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds
Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds 文章概括摘要1. 介绍2. 相关工作3. 学习 6D 抓握政策3.1 背景3.2 从点云抓取 6D 策略3.3 联合运动和抓握规划器的演示3.4 行为克隆和 DAGGER3.5 目标--辅助 DDPG3.6 对未知物体进行微调的后视目标 4. 实验4.1
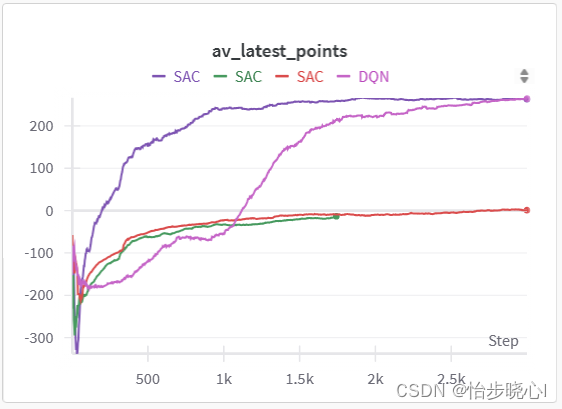
14、强化学习Soft Actor-Critic算法:推导、理解与实战
基于LunarLander登陆器的Soft Actor-Critic强化学习(含PYTHON工程) Soft Actor-Critic算法是截至目前的T0级别的算法了,当前正在学习,在此记录一下下。 其他算法: 07、基于LunarLander登陆器的DQN强化学习案例(含PYTHON工程) 08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程) 09、基于Luna
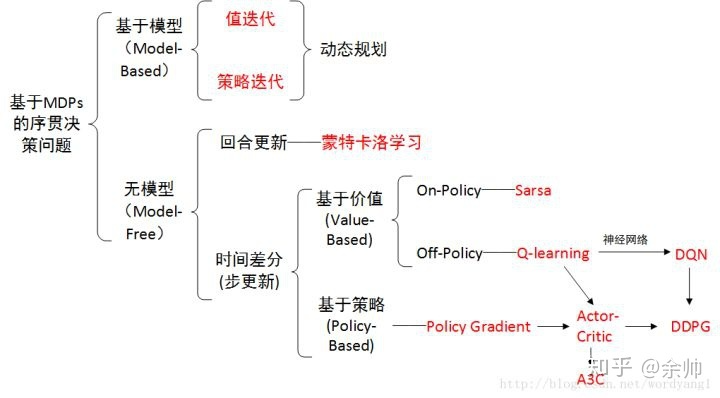
强化学习的数学原理学习笔记 - Actor-Critic
文章目录 概览:RL方法分类Actor-CriticBasic actor-critic / QAC🟦A2C (Advantage actor-critic)Off-policy AC🟡重要性采样(Importance Sampling)Off-policy PGOff-policy AC 🟦DPG (Deterministic AC) 本系列文章介绍强化学习基础知识与

An Actor–Critic based controller for glucose regulation in type 1 diabetes
a b s t r a c t \qquad 控制器基于Actor-Critic(AC)算法,受强化学习和最优控制理论(optimal control theory)的启发。控制器的主要特性是: 同时调整 胰岛素基础率 the insulin basal rate 和 大剂量 the bolus dose;根据临床规程进行初始化;real-time personalization。 \

【深度强化学习】策略梯度方法:REINFORCE、Actor-Critic
参考 Reinforcement Learning, Second Edition An Introduction By Richard S. Sutton and Andrew G. Barto 非策略梯度方法的问题 之前的算法,无论是 MC,TD,SARSA,Q-learning, 还是 DQN、Double DQN、Dueling DQN,有至少两个问题: 都是处理离散状态、

Actor-Critic 跑 CartPole-v1
gym-0.26.1 CartPole-v1 Actor-Critic 这里采用 时序差分残差 ψ t = r t + γ V π θ ( s t + 1 ) − V π θ ( s t ) \psi_t = r_t + \gamma V_{\pi _ \theta} (s_{t+1}) - V_{\pi _ \theta}({s_t}) ψt=rt+γVπθ(st+1)−Vπθ
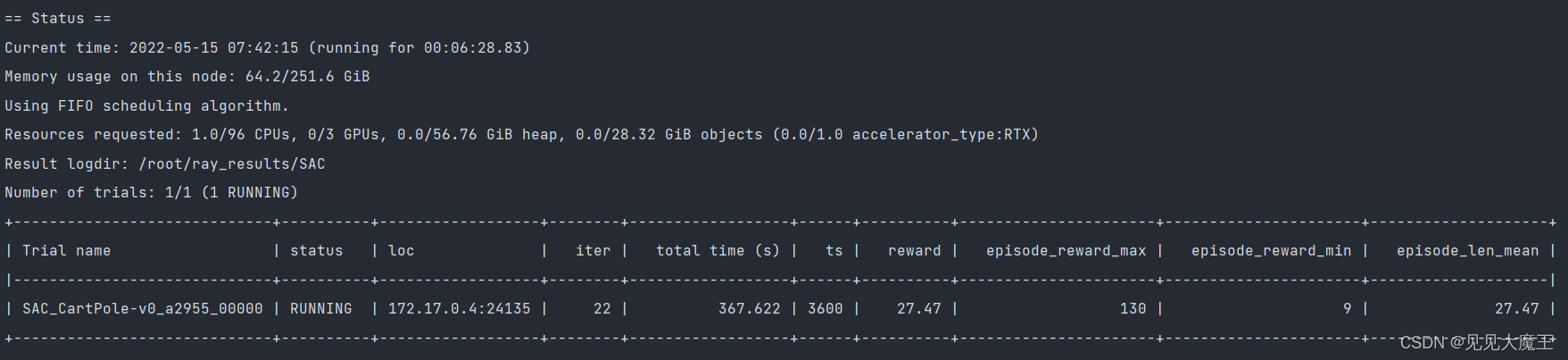
【RLlib使用指南】Soft Actor Critic (SAC)
1 概要 SAC 的框架与 DQN 相似。Rollout Workers 负责采样,Learner 负责训练参数,然后更新 Rollout Workers。 2 相关参数设置 DEFAULT_CONFIG = with_common_config({# === Model ===# 使用两个 Q-网络(而不是一个)进行动作价值估计。# Note: 每一个 Q-网络都有自己的 target

论文速读:《AN ACTOR-CRITIC ALGORITHM FOR SEQUENCE PREDICTION》
摘要 我们提出了一种训练神经网络的方法,使用强化学习(RL)中的演员评论方法生成序列。当前的对数似然训练方法受到训练和测试模式之间差异的限制,因为模型必须以先前的猜测而不是地面真实标记为基础生成标记。我们通过引入一个经过训练来评估输出令牌价值的评论家网络来解决这个问题,给定了演员网络的策略。这导致训练过程更接近测试阶段,并允许我们直接优化任务特定分数,例如BLEU。 至关重要的是,由于我们在监督

【强化学习】13 —— Actor-Critic 算法
文章目录 REINFORCE 存在的问题Actor-CriticA2C: Advantageous Actor-Critic代码实践结果 参考 REINFORCE 存在的问题 基于片段式数据的任务 通常情况下,任务需要有终止状态,REINFORCE才能直接计算累计折扣奖励 低数据利用效率 实际中,REINFORCE需要大量的训练数据 高训练方差(最重要的缺陷) 从单个或多个片段中
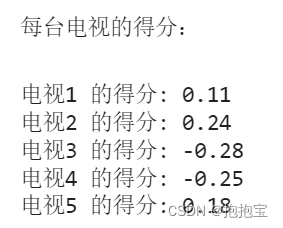
评价模型:CRITIC客观赋权法
目录 1.算法原理介绍2.算法步骤2.1 数据标准化2.2 计算信息承载量2.3 计算权重和得分 3.案例分析 1.算法原理介绍 CRITIC方法是一种客观权重赋权法,其基本思路是确定指标的客观权数以两个基本概念为基础。一是对比强度,它表示同一指标各个评价方案取值差距的大小,以标准差的形式来表现。二是评价指标之间的冲突性,指标之间的冲突性是以指标之间的相关性为基础,如两

Learning to play snake at 1 million FPS Playing snake with advantage actor-critic
在这篇博文中,我将引导您完成我最近的项目,该项目结合了我发现的两件令人着迷的东西 - 电脑游戏和机器学习。 很长一段时间以来,我一直想深入了解强化学习,我认为没有比做自己的项目更好的方法了。 为此,我在PyTorch中实现了经典的手机游戏“Snake”,并训练了强化学习算法来进行游戏。 这篇文章分为三个部分。 Snake游戏的大规模并行矢量化实现Advantage Actor-Critic(A2
Learning to play snake at 1 million FPS Playing snake with advantage actor-critic
在这篇博文中,我将引导您完成我最近的项目,该项目结合了我发现的两件令人着迷的东西 - 电脑游戏和机器学习。 很长一段时间以来,我一直想深入了解强化学习,我认为没有比做自己的项目更好的方法了。 为此,我在PyTorch中实现了经典的手机游戏“Snake”,并训练了强化学习算法来进行游戏。 这篇文章分为三个部分。 Snake游戏的大规模并行矢量化实现Advantage Actor-Critic(A2