本文主要是介绍Learning to play snake at 1 million FPS Playing snake with advantage actor-critic,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这篇博文中,我将引导您完成我最近的项目,该项目结合了我发现的两件令人着迷的东西 - 电脑游戏和机器学习。 很长一段时间以来,我一直想深入了解强化学习,我认为没有比做自己的项目更好的方法了。 为此,我在PyTorch中实现了经典的手机游戏“Snake”,并训练了强化学习算法来进行游戏。 这篇文章分为三个部分。
- Snake游戏的大规模并行矢量化实现
- Advantage Actor-Critic(A2C)的解释
- 结果:分析不同代理人的行为
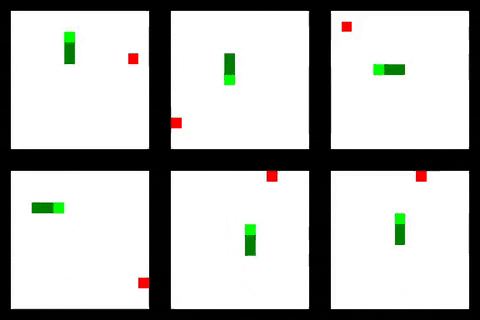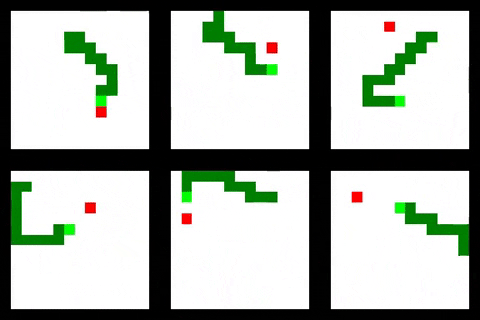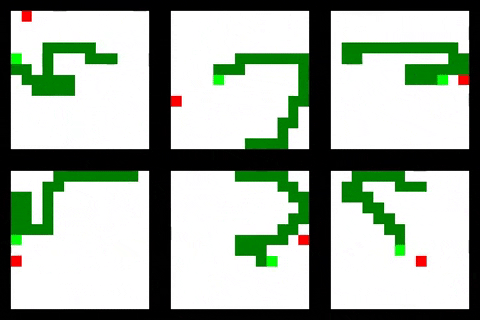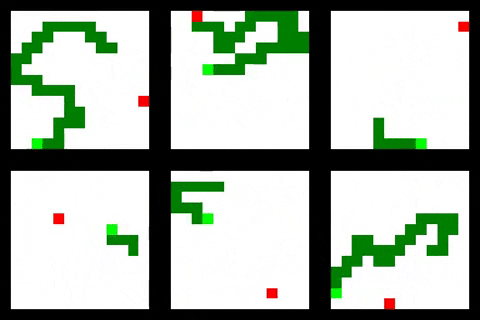
Code for this project is available at: https://github.com/oscarknagg/wurm/tree/medium-article-1
Snake — vectorized
尽管取得了令人印象深刻的成就,深度强化学习却非常缓慢。在像DotA 2和Starcraft这样的复杂游戏中已经取得了令人难以置信的成绩,但这些已经花费了数千年的游戏时间。事实上,即使是引发当前深度强化学习兴趣的工作,即学习玩Atari游戏,也需要数周的游戏玩法以及每场游戏的数百万帧。
从那时起,已经进行了大量研究,以加速深度强化学习,无论是通过并行化和改进实施的挂钟时间,还是在样本效率方面。许多最先进的强化学习算法同时在环境的多个副本中训练,通常每个CPU核心一个。这样可以大大提高线速度,从而可以通过更多CPU内核生成游戏体验。
因此,为了尝试深度强化学习,你最好拥有大量的计算资源。一个非常快/平行的环境或愿意等待很长时间。由于我无法访问大型集群并希望快速查看结果,因此我决定创建一个Snake的矢量化实现,它可以实现比CPU内核数量更高的并行化水平。
What is vectorization?
矢量化是单指令,多数据(SIMD)并行的一种形式。 对于那些Python程序员而言,这就是numpy操作通常比执行相同计算的显式for循环快几个数量级的原因。
本质上,矢量化是可能的,因为如果处理器可以在单个时钟周期中对256位数据执行操作,并且程序的实数是32位单精度数,那么您可以将这些数字中的8个打包成256位并执行8 每个时钟周期的操作。 因此,如果一个程序足够聪明,可以安排指令,使得在正确的时间总是有8个操作数,理论上它应该能够实现比一次对一个数据执行指令高8倍的速度。
Implementation: Representing the environment

关键思想是将环境的完整状态表示为单个张量。 事实上,多个环境被表示为单个4d张量,其方式与表示一批图像的方式相同。 在Snake的情况下,每个图像/环境有三个通道:一个用于食物颗粒,一个用于蛇头,一个用于蛇体,如上所示。 这样做可以让我们利用PyTorch已经拥有的许多功能和优化来操作这种数据。

Implementation: Moving the snake
所以现在我们有了一种表示游戏环境的方法,我们需要使用矢量化张量操作来实现游戏玩法。 第一个技巧是我们可以在每个环境中移动所有蛇头的位置,方法是将带有手工过滤器的2D卷积应用到环境张量的头部通道。

但是,PyTorch只允许我们对整个批处理使用相同的卷积过滤器,但我们需要能够在每个环境中采取不同的操作。 因此,我应用第二个技巧来解决这个限制。 首先对每个环境应用一个带有4个输出通道(每个运动方向1个)的卷积,然后使用非常有用的torch.einsum使用一个热门的动作向量“选择”正确的动作。 我强烈建议阅读this文章,以便对爱因斯坦求和及其在NumPy / PyTorch / Tensorflow中的使用进行非常好的介绍。
现在我们移动了头部,我们需要移动身体。 首先,我们通过从所有身体位置减去1然后应用ReLu函数将其他元素保持在0以上来向前移动尾部(即身体上的1个位置)。然后我们制作头部通道的副本,将其乘以最大值 身体值加1.我们然后将此副本添加到头部通道,为主体创建一个新的前部位置(图中的位置8)。

需要更多的逻辑,例如检查碰撞和食物收集,死后重置环境以及检查蛇是不是要向后移动 - 考虑如何以跨多个环境进行矢量化的方式实现所有这些,这非常有趣。 所有这些优化的最终结果如下图所示。 使用单个1080Ti和大小为9的环境,我可以使用随机代理每秒运行最多超过一百万步,并且在使用A2C训练卷积代理时使用超过70,000步/秒(使用与后面相同的超参数)结果)。

Advantage actor-critic (A2C)
在本节中,我假设您熟悉强化学习的基本术语,例如 价值功能,政策,奖励,回报等…
演员评论算法背后的想法很简单。 您训练一个演员网络,从观察到的状态映射到动作即策略的概率分布。 该网络的目的是学习在特定州采取的最佳行动。
同时,你还训练一个批评网络,从国家映射到他们的预期价值,即在这种状态后预期的未来奖励的总和。 该网络的目的是了解处于特定状态的可取之处。 该网络还通过为州提供基准值来稳定政策网络的学习,我们稍后会看到。

Value function learning
值函数的丢失是特定状态的预测值与从该状态生成的实际返回之间的平方差。 因此,价值函数学习是一个回归问题。
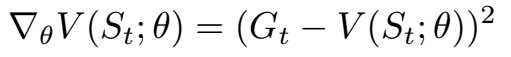
在实践中,计算特定状态的真实回报需要使轨迹从该状态开始直到时间结束,或者至少直到代理人死亡。 由于有限的计算资源,我们计算从固定有限长度T的轨迹返回,并使用自举来估计最终轨迹状态之后的远距离返回。 Bootstrapping意味着我们用轨迹中最终状态的预测值替换总和的最后部分 - 模型的预测用作其目标。
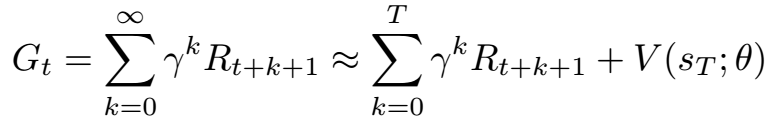
Policy learning
在强化学习领域有一个重要的结果,称为政策梯度定理。 这表明对于参数化策略(例如,从状态到动作的神经网络映射),它们在参数上存在梯度,平均导致策略性能的提高。 该政策的执行情况定义为各州对该政策所访问国家分布的预期价值,如下所示。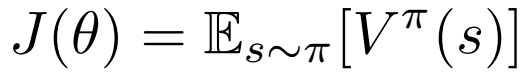
这实际上是一个比它最初看起来更令人惊讶的结果。 给定特定状态,计算改变策略参数对动作的影响并因此计算奖励是相对简单的。 但是,我们感兴趣的是对政策所访问的国家分布的奖励期望,这也将随政策参数而变化。 改变政策对国家分配的影响通常是未知的。 因此,当性能取决于策略变化对状态分布的未知影响时,我们可以计算与策略参数相关的性能梯度,这是非常值得注意的。
下面显示的是策略梯度算法的一般形式。 对这个定理的证明和完整的讨论超出了范围,但如果你有兴趣深入挖掘,我会推荐Sutton和Barto的“强化学习:介绍”第13章。
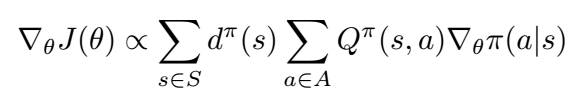
通过一些数学运算,我们可以将其作为对我们的政策所访问的州和行动的期望。

这个表达式更容易获得直觉。 期望的第一部分是政策所见的国家 - 行动对的Q值,即绩效指标。 第二部分是渐变,它增加了特定动作的对数概率。 直观地,总体政策梯度是个体梯度的期望,其增加了高回报行动的可能性。 相反,如果Q(s,a)为负(即不良行为),则各个梯度必须降低这些动作的概率。
如前所述,对政策梯度定理的一个重要见解是,如果将任意独立于行动的基线b(s)添加到Q函数中,它就不会改变。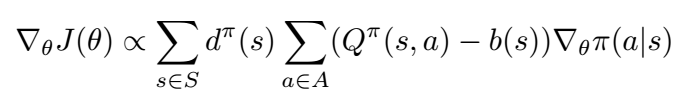
添加此基线函数会为策略渐变引入一个新术语,该术语与动作无关,始终等于0。

虽然添加基线不会影响政策梯度的预期,但确实会影响其方差,因此选择良好的基线可以加快学习良好政策的速度。
在A2C中选择的基线是优势函数(因此有利于演员 - 评论家)。 这可以量化特定状态 - 动作对与该状态的平均动作相比有多好。
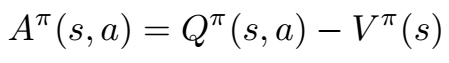
基于这个表达式,我们看起来需要学习另一个网络来近似Q(s,a)。 但是我们可以用更简单的方式重写它。

我们可以这样做,因为特定政策的Q函数的定义是来自状态s中的动作a的奖励加上来自该剧集的其余部分的该策略的预期回报。 因此,演员 - 评论家梯度的最终优势如下。
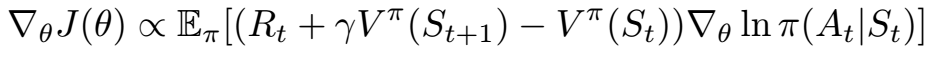
Overall algorithm
现在我已经勾勒出A2C的理论基础,是时候看完整个算法了。 我们需要获得政策的逐步改进是获得样本的一种方式,使得这些样本的梯度的期望与上述表达式成比例。 这可以通过记录我们的政策产生的经验轨迹来非常简单地实现。 为了加速这一点,我们可以在同一环境中并行运行多个策略副本,以更快地生成体验。

这是着名的异步优势actor-critic算法(A3C)的同步版本。 不同之处在于,在A3C中,参数更新分别在许多工作线程中计算,并用于更新其他线程周期性同步的主网络。 在批量处理的A2C中,定期组合所有工作人员的经验以更新主网络。
A3C异步的原因是不同线程中环境速度的差异不会相互减慢。 然而,在我的蛇环境中,环境速度总是完全相同,因此算法的同步版本更有意义。
Results
现在我已经描述了实施和理论,它是学习玩蛇的时候了! 在我的实验中,我比较了三种不同架构的性能,如下图所示。

第一个代理(左)是来自Deepmind的较小版本的代理 “Deep reinforcement learning with relational inductive biases”纸。 该代理包含一个“关系模块”,它基本上是应用于2D图像的Transformer模型中的自我关注机制。 在此之后,我们在值和策略输出之前应用通道方式最大池和单个完全连接的层。 为了比较,我还实现了一个卷积代理(中间),除了用更多的卷积层替换关系模块之外,它是相同的。
作为一个黑马竞争对手,我介绍了一个更简单,纯粹的前馈代理(右),它只作为输入蛇头部周围的局部区域,使环境部分可观察。 输入观察被展平并通过两个前馈层。 价值和政策输出是最终激活的线性预测,就像其他两个代理一样。
在规模9的环境中,所有3个代理人都被训练了5次,达到5000万步。 具有1个标准偏差的训练曲线如下所示。

值得注意的是,仅具有部分环境可观察性的前馈代理执行得非常好,实现了所有代理的最高平均大小。 它也学得最快,可能是由于拥有最小的观察空间。 正如您从下面的GIF中所看到的,它已经学会了通过环绕环境来避免仅仅具有有限可见性的缺点,以便所有它最终进入视野。 这使它能够找到分散在环境中的奖励,但不如卷积和关系代理那样有效。

其他代理人或多或少地直接向奖励移动,但也倾向于犯一些愚蠢的错误,这反映在与前馈代理相比较高的边缘碰撞率。 值得注意的是,对于这项任务,关系代理的表现并不比卷积代理更好。 我假设蛇环境太简单了,因为并入关系模块的归纳偏差是有用的。 Deepmind对关系代理进行基准测试的任务涉及为多个盒子收集多个密钥以收集最终的大奖励 - 比蛇复杂得多!
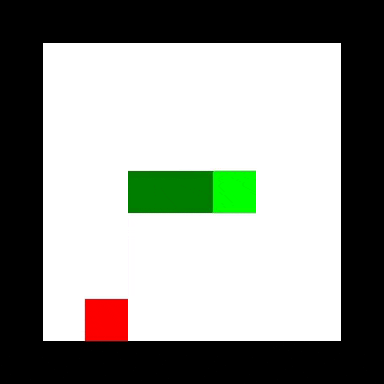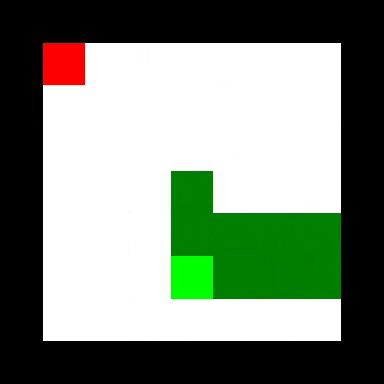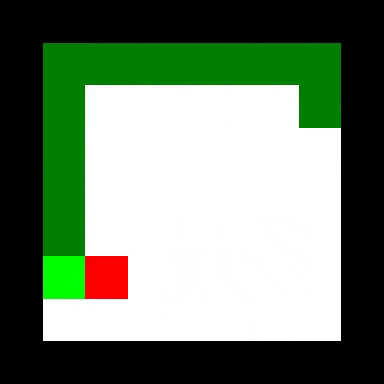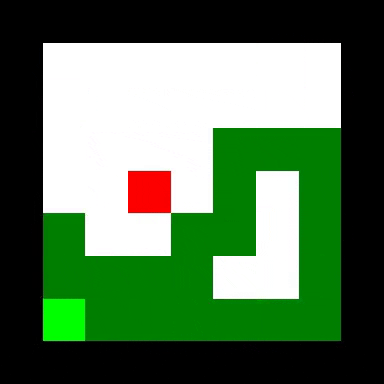
Bonus: transferring to a larger environment
- 显示在大型环境中从头开始学习与从较小环境中学习的比较
- 显示不同代理的转移均值和方差,突出显示非常高的方差,即在某些情况下完全失败
作为奖金实验,我决定看看如果我将代理从小尺寸9环境转移到更大尺寸的15环境会发生什么。 我评估了在较大环境中100万步的每种类型代理的5个实例的性能,没有进一步的培训。
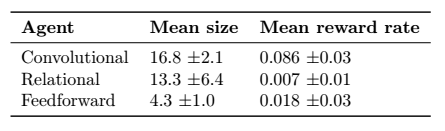
此表在代理类型之间甚至在特定培训运行中的传输性能方面存在巨大差异。 卷积代理概括得很好,实现了大的平均规模和高回报率。 实际上,卷积代理比在较大环境中从头开始训练的相同代理执行得更好。 我相信这是因为在较大的环境中奖励较为稀疏,因此在较大的环境中学习速度会显着放缓。
可以观察到一些相当聪明的行为。 在较大的蛇尺寸下,卷积剂有时会被视为在等待其尾部移开时执行“盘绕”操作。

有限能见度代理继续围绕环境边缘盘旋的相同策略。 这可以很好地执行,直到食物颗粒在代理人无法观察到的环境中心产生,并且从此时代理人不再收集奖励。 这与上表中的大尺寸和小奖励率一致。

至少可以说,关系代理的性能不稳定。 在某些运行中它会表现得相当好,而在其他运行中它几乎会立即死亡或陷入循环。

在这个项目中,我亲眼目睹了深层强化学习的缓慢,并提出了一种整洁的,如果有蛮力的方式绕过它。 通过观察非常相似的环境之间的失败转移,我也经历了深RL的脆弱性质。
在未来的工作中,我想实施更多的网格世界游戏,以便研究游戏之间的转移学习。 或许我会实现一个多代理蛇环境来回答OpenAI的问题 “Slitherin’” request for research.
Code for this project is available at: https://github.com/oscarknagg/wurm/tree/medium-article-1
这篇关于Learning to play snake at 1 million FPS Playing snake with advantage actor-critic的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









