本文主要是介绍【RLlib使用指南】Soft Actor Critic (SAC),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 概要
SAC 的框架与 DQN 相似。Rollout Workers 负责采样,Learner 负责训练参数,然后更新 Rollout Workers。

2 相关参数设置
DEFAULT_CONFIG = with_common_config({# === Model ===# 使用两个 Q-网络(而不是一个)进行动作价值估计。# Note: 每一个 Q-网络都有自己的 target 网络."twin_q": True,# 使用(例如 conv2D)状态预处理网络,然后将结果(特征)向量与 Q-网络输入的动作输入连接起来。"use_state_preprocessor": DEPRECATED_VALUE,# Q-网络的模型选项。这些设置将覆盖 MODEL_DEFAULTS。# `Q_model` dict 在设置 Q-网络时被视为顶级 `model` dict(如果 twin_q=True 则为 2)。# 这意味着,您可以针对不同的观察空间进行操作:# obs=Box(1D) -> Tuple(Box(1D) + Action) -> concat -> post_fcnet# obs=Box(3D) -> Tuple(Box(3D) + Action) -> vision-net -> concat w/ action# -> post_fcnet# obs=Tuple(Box(1D), Box(3D)) -> Tuple(Box(1D), Box(3D), Action)# -> vision-net -> concat w/ Box(1D) and action -> post_fcnet# 您还可以让 SAC 使用您的 custom_model 作为 Q-model,# 只需在下面的 dict 中指定 `custom_model` 子键(就像您在顶级 `model` dict 中所做的那样)。"Q_model": {"fcnet_hiddens": [256, 256],"fcnet_activation": "relu","post_fcnet_hiddens": [],"post_fcnet_activation": None,"custom_model": None, # Use this to define custom Q-model(s)."custom_model_config": {},},# 策略功能的模型选项(有关详细信息,请参阅上面的“Q_model”)。# 与上面的 `Q_model` 不同的是,在 post_fcnet 堆栈之前不执行任何操作连接。"policy_model": {"fcnet_hiddens": [256, 256],"fcnet_activation": "relu","post_fcnet_hiddens": [],"post_fcnet_activation": None,"custom_model": None, # Use this to define a custom policy model."custom_model_config": {},},# 动作已经标准化,无需进一步剪辑。"clip_actions": False,# === Learning ===# 更新 target: \tau * policy + (1-\tau) * target_policy."tau": 5e-3,# 用于熵权 alpha 的初始值。"initial_alpha": 1.0,# 目标熵下限。 If "auto", will be set to -|A| (e.g. -2.0 for# Discrete(2), -3.0 for Box(shape=(3,))).# This is the inverse of reward scale, and will be optimized automatically."target_entropy": "auto",# N-步 target 更新。 If >1, sars' tuples in trajectories will be# postprocessed to become sa[discounted sum of R][s t+n] tuples."n_step": 1,# 在单个“train()”调用中累积的最小 env 采样时间步长。 # 此值不影响学习,仅影响 `Trauber.train()` 调用 `Trainer.step_attempt()` 的次数。# If - after one `step_attempt()`, the env sampling# timestep count has not been reached, will perform n more `step_attempt()` calls# until the minimum timesteps have been executed. Set to 0 for no minimum timesteps."min_sample_timesteps_per_reporting": 100,# === Replay buffer ==="replay_buffer_config": {# 启用新的 ReplayBuffer API"_enable_replay_buffer_api": True,"type": "MultiAgentPrioritizedReplayBuffer","capacity": int(1e6),# 在学习开始之前要对模型采样多少步"learning_starts": 1500,# 一次重放的连续环境步骤数。 这可以设置为大于 1 以支持循环模型"replay_sequence_length": 1,# 如果 True,优先重放缓冲区将被使用。"prioritized_replay": False,"prioritized_replay_alpha": 0.6,# 用于从优先重放缓冲区中采样的 Beta 参数"prioritized_replay_beta": 0.4,# 更新优先级时添加到 TD 错误的 Epsilon"prioritized_replay_eps": 1e-6,},# 将此设置为 True,如果您希望缓冲区的内容也存储在任何已保存的检查点中。# Warnings will be created if:# - This is True AND restoring from a checkpoint that contains no buffer# data.# - This is False AND restoring from a checkpoint that does contain# buffer data."store_buffer_in_checkpoints": False,# Whether to LZ4 compress observations"compress_observations": False,# The intensity with which to update the model (vs collecting samples from# the env). If None, uses the "natural" value of:# `train_batch_size` / (`rollout_fragment_length` x `num_workers` x# `num_envs_per_worker`).# If provided, will make sure that the ratio between ts inserted into and# sampled from the buffer matches the given value.# Example:# training_intensity=1000.0# train_batch_size=250 rollout_fragment_length=1# num_workers=1 (or 0) num_envs_per_worker=1# -> natural value = 250 / 1 = 250.0# -> will make sure that replay+train op will be executed 4x as# often as rollout+insert op (4 * 250 = 1000).# See: rllib/agents/dqn/dqn.py::calculate_rr_weights for further details."training_intensity": None,# === Optimization ==="optimization": {"actor_learning_rate": 3e-4,"critic_learning_rate": 3e-4,"entropy_learning_rate": 3e-4,},# 如果不是 None,则在优化期间以该值剪辑渐变"grad_clip": None,# Update the replay buffer with this many samples at once. Note that this# setting applies per-worker if num_workers > 1."rollout_fragment_length": 1,# 从重播缓冲区中采样以进行训练的批量采样的大小"train_batch_size": 256,# 每 `target_network_update_freq` 步骤更新目标网络"target_network_update_freq": 0,# === Parallelism ===# Whether to use a GPU for local optimization."num_gpus": 0,# Number of workers for collecting samples with. This only makes sense# to increase if your environment is particularly slow to sample, or if# you"re using the Async or Ape-X optimizers."num_workers": 0,# Whether to allocate GPUs for workers (if > 0)."num_gpus_per_worker": 0,# Whether to allocate CPUs for workers (if > 0)."num_cpus_per_worker": 1,# Whether to compute priorities on workers."worker_side_prioritization": False,# Prevent reporting frequency from going lower than this time span."min_time_s_per_reporting": 1,# Whether the loss should be calculated deterministically (w/o the# stochastic action sampling step). True only useful for cont. actions and# for debugging!"_deterministic_loss": False,# Use a Beta-distribution instead of a SquashedGaussian for bounded,# continuous action spaces (not recommended, for debugging only)."_use_beta_distribution": False,# Deprecated.# The following values have moved because of the new ReplayBuffer API."prioritized_replay": DEPRECATED_VALUE,"prioritized_replay_alpha": DEPRECATED_VALUE,"prioritized_replay_beta": DEPRECATED_VALUE,"prioritized_replay_eps": DEPRECATED_VALUE,"learning_starts": DEPRECATED_VALUE,"buffer_size": DEPRECATED_VALUE,"replay_batch_size": DEPRECATED_VALUE,"replay_sequence_length": DEPRECATED_VALUE,
})
3 简单案例
from ray import tune
tune.run(“SAC”, config={"env": "CartPole-v0", "train_batch_size": 4000}
)
随后出现训练中的状态情况:
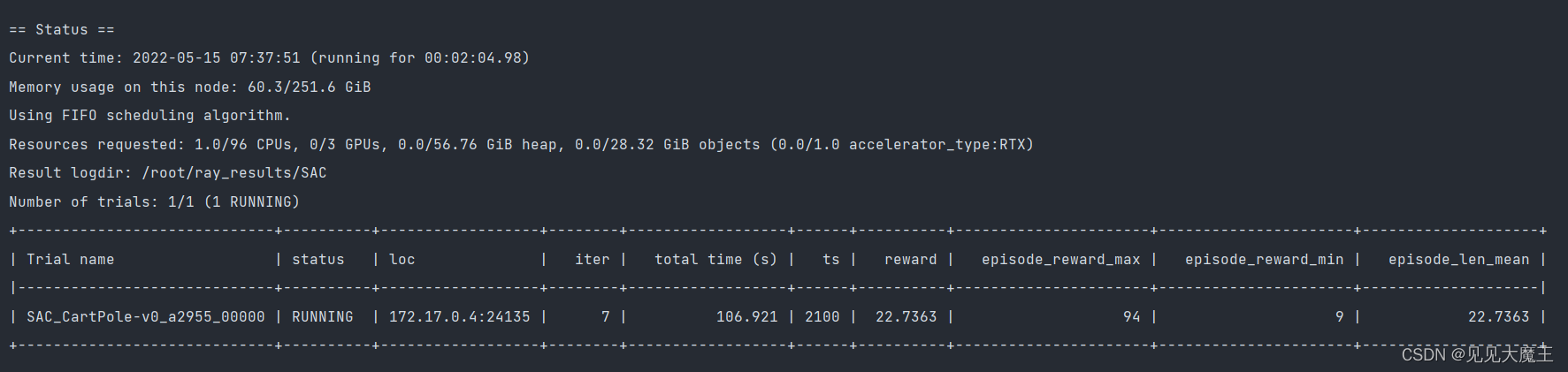
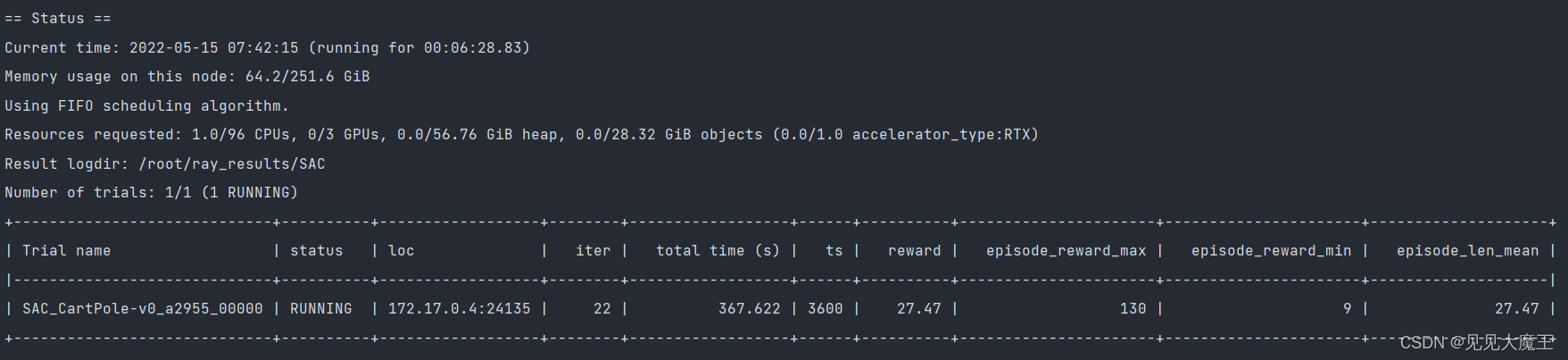
可以看到训练了一段时间后,reward 的最大值和平均值都有所增加:
这篇关于【RLlib使用指南】Soft Actor Critic (SAC)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






