本文主要是介绍C++11 数据结构0 什么是 “数据结构“?数据,数据对象,数据元素,数据项 概念。算法的基本概念 和 算法的度量,大O表示法,空间换时间的代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 数据:
数据:
- 是能输入计算机且能被计算机处理的各种符号的集合。
- 数值型的数据:整数和实数。
- 非数值型的数据:文字、图像、图形、声音等。
数据对象:
性质相同的 "数据元素" 的集合
例如一个 int arr[10], Teacher tea[3];
数据元素:
tea[0],tea[1],arr[2],这些都是
数据项:
数据元素中的每一项。
数据结构就是研究 数据元素之间关系的,注意这门课研究的位置和方向。
算法的概念:
特定问题的求解步骤的描述。
算法复杂度:大O法表示
用空间来换取时间的一个例子:
//有一个数组,统计这个数组中的数组都是由1-999 组成的,统计这个数组中那个 数字出现的最多,并打印出现的次数
#include <iostream>
using namespace std;void search(int *array, int len) {int sp[1000] = { 0 }; //都清空成0int i = 0; int max = 0;for (i = 0; i < len;++i) {//遍历数组。将数组的值做为sp数组的下标,每出现一次,则+1int index = array[i] - 1;sp[index] ++;//也就是说,如果碰到array[100] = 11,则将sp[10]的值++,}//找出出现最多的次数,赋值给maxfor (i = 0; i < 1000;++i) {if (max<sp[i]) {max = sp[i];}}//找到了出现最多的次数,还要根据这个次数找到array的值。这里要好好的理解一下for (i = 0; i < 1000;++i) {if (max == sp[i]) {cout << "出现最多的是" << i+1 <<" 出现的次数是 :" << max << endl;}}
}int main()
{std::cout << "Hello World!\n";//有一个数组,统计这个数组中的数组都是由1-999 组成的,统计这个数组中那个 数字出现的最多,并打印出现的次数int array[] = { 178,2,33,4,5,6,4,3,2,1,23,6,6,6,3,45,46,45,6,6,6,6,6,6,6,6,999 };cout << "sizeof(array)" << sizeof(array)<< endl;cout << "sizeof(*array)" << sizeof(*array) << endl;cout << "*array = " << *array << endl;search(array,sizeof(array)/sizeof(*array));
}数据结构:
数据结构就是研究 数据元素之间关系的,注意这门课研究的位置和方向。
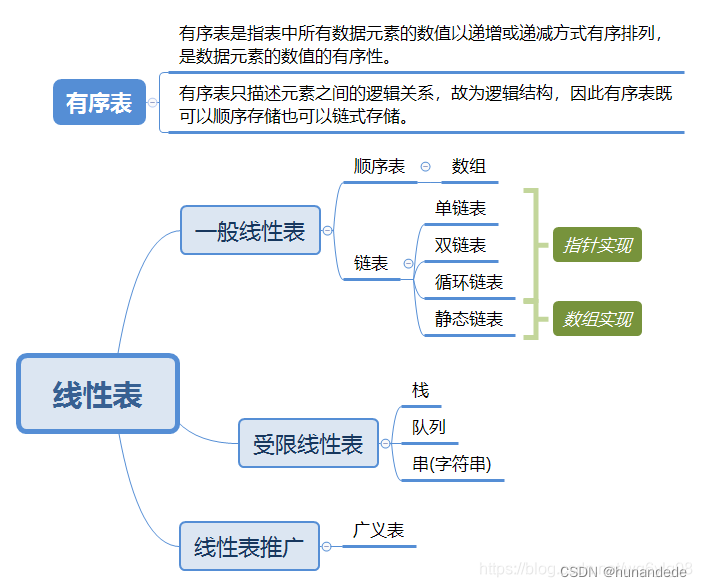
那么具体要学些啥呢?
1.一般线性表的顺序实现,实际上就是数组
2.一般线性表的链式存储 --单链表
3.一般线性表的链式存储 --双链表
4.一般线性表的链式存储 --循环链表
5.栈的顺序存储
6.栈的链式存储
7.队列的顺序存储
8.队列的链式存储
9.然后再研究树。树的知识点是以学好前面的知识为基础的,因此要先学好前面的线性表 相关的。然后再学习树
这篇关于C++11 数据结构0 什么是 “数据结构“?数据,数据对象,数据元素,数据项 概念。算法的基本概念 和 算法的度量,大O表示法,空间换时间的代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






