度量专题

量化交易面试:什么是连贯风险度量?
连贯风险度量(Coherent Risk Measures)是金融风险管理中的一个重要概念,旨在提供一种合理且一致的方式来评估和量化风险。连贯风险度量的提出是为了克服传统风险度量方法(如VaR,风险价值)的一些局限性。以下是对连贯风险度量的详细解释: 基本概念: 连贯风险度量是指满足特定公理的风险度量方法,这些公理确保了风险评估的一致性和合理性。 这些公理包括:非负性、次可加性、同质性和单调

PowerBI DAX中计算列和度量值之间有什么优缺点?
在Power BI中,度量值(Measures)和新建列(Calculated Columns)都是使用DAX(数据分析表达式)来创建的,它们都可以用来进行数据计算和分析。但是,它们在使用场景、性能和交互性方面有所不同。 以下是度量值和新建列的优缺点: 度量值(Measures) 优点: 性能优化:度量值在内存中进行计算,通常比基于行的计算(如新建列)更快。参与视觉对象

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法

度量学习(Distance Metric Learning)介绍
原文:度量学习(Distance Metric Learning)介绍 http://blog.csdn.net/lzt1983/article/details/7884553 一直以来都想写一篇metric learning(DML)的综述文章,对DML的意义、方法论和经典论文做一个介绍,同时对我的研究经历和思考做一个总结。可惜一直没有把握自己能够写好,因此拖到现在。

【Python机器学习】NLP分词——利用分词器构建词汇表(三)——度量词袋之间的重合度
如果能够度量两个向量词袋之间的重合度,就可以很好地估计他们所用词的相似程度,而这也是它们语义上重合度的一个很好的估计。因此,下面用点积来估计一些新句子和原始的Jefferson句子之间的词袋向量重合度: import pandas as pdsentence="""Thomas Jefferson Began buliding Monticelli as the age of 26.\n""
深度学习实用方法 - 性能度量篇
序言 在深度学习的广阔领域里,性能度量是连接理论与实践的桥梁,它不仅是评估模型效果的关键指标,也是指导模型优化与改进的重要依据。随着大数据时代的到来和计算能力的提升,深度学习模型在图像识别、自然语言处理、推荐系统等多个领域取得了突破性进展。然而,如何准确、全面地评估这些复杂模型的性能,成为了研究者们面临的重要挑战。性能度量不仅关乎模型预测的准确性,还涉及到稳定性、泛化能力、计算效率等多个维度,为

图像检索中相似度度量公式:各种距离
基于内容的图像检索(Content-Based Image Retrieval)是指通过对图像视觉特征和上下文联系的分析,提取出图像的内容特征作为图像索引来得到所需的图像。 相似度度量方法 在基于内容的图像检索中需要通过计算查询和候选图像之间在视觉特征上的相似度匹配。因此需要定义一个合适的视觉特征相似度度量方法对图像检索的效果无疑是一个很大的影响。提取的视觉特征大都可以表示成向量的形式,
Word中度量单位的设定
1. 一般文章的段前后距离是以“磅”为单位,首行缩进是以“字符”为单位,但word中显示的单位往往并非如此。 首先考虑到word同一时间只能有一种单位(同时以磅和字符宽度为单位时以字符宽度为准),所以单纯设置任何一个单位都达不到要求。又结合单位的设置方法(见附录),我们可以先设置单位为“字符宽度”,设定首行缩进为两个字符,再将“以字符宽度为单位”的勾去掉,以磅为单位,此时因为旧的单

为机器学习模型选择正确的度量评估(第二部分)
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Alvira Swalin 编译:ronghuaiyang 前戏 今天是第二部分,分类的度量。 本系列的第二部分将重点讨论分类指标 在第一部分中,我们讨论了回归中使用的一些重要指标、它们的优缺点和用例。这一部分将着重于分类中常用的度量标准,为什么我们应该在上下文中选择其中的一些。 定义 在讨论每种方法的优缺点之前,让我们
为机器学习模型选择正确的度量评估(第一部分)
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Alvira Swalin 编译:ronghuaiyang 前戏 对不同的应用场景,需要不同的模型,对于不同的模型,需要不同的度量评估方式。 本系列的第一部分主要关注回归的度量 在后现代主义的世界里,相对主义的各种形式一直是最受欢迎和最受唾弃的哲学理论之一。根据相对主义,不存在普遍客观的真理,相反,每个观点都有自己的道理。
MRR vs MAP vs NDCG:具有排序意义的度量指标的可视化解释及使用场景分析
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Moussa Taifi, Ph.D 编译:ronghuaiyang 导读 3种指标,各有优缺点,各有适用场景,分析给你看。 机器学习度量之旅 在不适当的度量指标上报告小的改进是一个众所周知的机器学习陷阱。理解机器学习(ML)指标的优缺点有助于为ML从业者建立个人信誉。这样做是为了避免过早宣布胜利的陷阱。理解用于机器学习(

RIP路由附加度量值(华为)
#交换设备 RIP路由附加度量值 RIP(Routing Information Protocol)路由协议中的附加度量值是指在RIP路由原来度量值的基础上所增加的额外度量值,通常以跳数来表示。这个附加度量值可以是正值,也可以是负值,用于影响路由选择的过程。在某些场景下,网络管理员可能希望通过手动增加或减少特定路由的度量值来控制或优化路由路径。 在华为路由器中,附加度量值的配置可以通过以下两

【数据挖掘】机器学习中相似性度量方法-余弦相似度
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。 “相似性度量(similarity measurement)”系列文章:、 【数据挖掘】机器学习中

度量学习相关 - 简单记录(代码和阅读材料)
20210312 - 0. 引言 (本人非专业人士,仅仅记录自己的简单理解,本人所引用代码或文章并未经过实际验证,仅仅参考其中主要思想,如有报错请自行解决) 度量学习会在神经网络的训练中,加入或者直接使用相似度作为目标。之前在上一门课程的时候,正好阅读过一篇与此相关的顶会文章,当时对其有了简单理解。简单说,就是讲相似度比较加入到神经网络的结构或者训练目标中。本篇文章用来记录一些相关的内容。
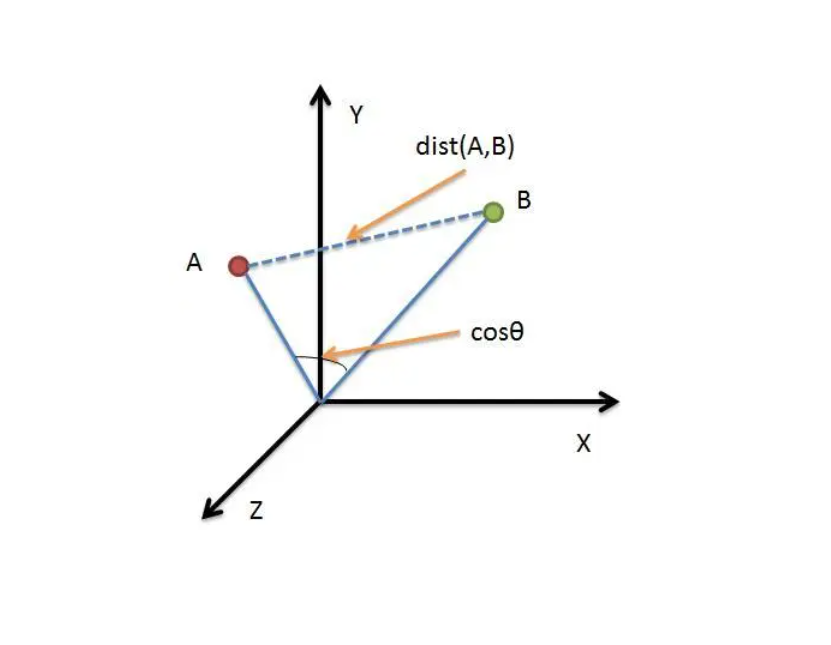
【数据挖掘】机器学习中相似性度量方法-欧式距离
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。 最近在做实际项目时,遇到需要计算两个向量的相似性,即需要计算不同数据样本之间的相似度。计算样本之间
【机器学习300问】114、什么是度量学习?三元组损失又是什么?
这些天都在加强自己的CV基本功,之前做过的人脸识别项目里有很多思考,在学习了这些基础知识后,我再次回顾了之前的人脸识别项目。我发现,很多之前困惑不解的问题现在都有了清晰的答案。 一、什么是度量学习? 度量学习也称为距离度量学习或相似度学习。目标是学习有效的距离或相似度度量,使同类样本之间的距离小、不同类样本之间的距离大,以提高分类或聚类准确性。常见方法有对比学习

机器学习--从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全不代表你将来的面试中会遇到此类问题,只是因为我的简历上写了句:熟悉常见的聚类 & 分类算法而已),而我向来恨对一个东西只知其皮毛而不得深入,故写一个有关数据挖掘十大算法的系列文章以作为自己备试之用,甚至以备将来常常回顾思考。行文杂乱,但侥幸若能对读者起到一
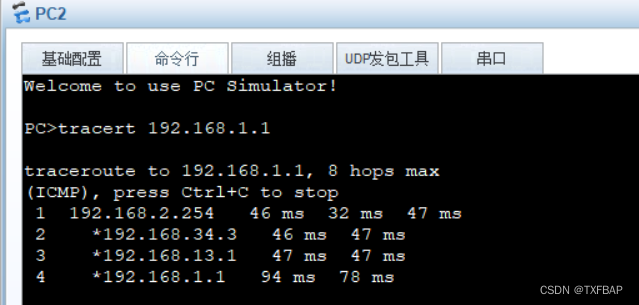
eNSP学习——配置RIP路由附加度量值
目录 主要命令 原理概述 实验目的 实验内容 实验拓扑 实验编址 实验步骤 1、基本配置 2、搭建RIP网络 3、配置RIP Metricin 4、配置RIP Metricout 需要eNSP各种配置命令的点击链接自取:华为eNSP各种设备配置命令大全PDF版_ensp配置命令大全资源-CSDN文库 主要命令 //查看RIP数据库[R1]display rip 1

手写kNN算法的实现-用余弦相似度来度量距离
设a为预测点,b为其中一个样本点,在向量空间里,它们的形成的夹角为θ,那么θ越小(cosθ的值越接近1),就说明a点越接近b点。所以我们可以通过考察余弦相似度来预测a点的类型。 from collections import Counterimport numpy as npclass MyKnn:def __init__(self,neighbors):self.k = neighb
spring-boot自定义度量信息
1、spring-boot-starter-actuator 2、@Autowired private CounterService counterService; @RequestMapping("/random.do") public String test(){ counterService.increment("display.random.count"); r
spring-boot-发布自定义度量信息
1、 CounterService(inc,dec,reset)与GaugeService(submit更新) @RestControllerpublic class AppleCtrl {@Autowiredprivate CounterService counterService;@Autowiredprivate GaugeService gaugeService;@RequestMap
数据结构-算法效率的度量-时间复杂度和空间复杂度
度量算法的效率:时间复杂度、空间复杂度。 时间复杂度,一般情况,算法中基本操作重复执行的次数是问题规模n的一个函数f(n),算法的时间度量记做T(n)=O(f(n)),他表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称做算法的渐近时间复杂度,简称时间复杂度。 插入一个概念:语句的頻度指的是该语句重复执行是次数。 我们在计算时间复杂度的时候, 先要找出算法的基本操作,

邀请函:11月1日远程研讨会,主题:《度量、建立缺陷管理模型以及敏捷在项目中的运用》
邀请函:11月1日9:00-11:00,网络远程交流会,主题: 《度量、建立缺陷管理模型以及敏捷在项目中的运用》 主讲:Edmond Sung. 参加方式:发送邮件至claire@processis.org索要报名表(人数限制为12人以内),联系电话:18921395967

Deming管理系列(2)——如何开发度量能力
问题: 一个公司为了做好软件开发,产品,服务或者销售也许有很多的度量(例如:进度,工作量,缺陷)。然而,许多度量对于提高产品质量,生产率或客户满意度并不充分和有帮助。那么,如何制定度量和分析的目标以便它们和已识别的信息需求和业务目标相一致呢? 我们举两个戴明关于操作定义的理论中的例子来揭示上面问题的答案。 例1想象我们处在一个大型研讨会议上,这儿有个问题:“这个房间里有多少人?”
20140517,香港专家2014免费远程培训——基于度量的战略方针
预览: 战略方针管理 (SPD)方法是用作记录和加强战略目标,以及洞察未来,使战略变成现实的方法。这个 方法是基于日本1950年代末Yogi Akao教授提出的一种概念推广。“每个人在他的工作领域内都是专家”, 日本的全面质量管理的方法就是用这种收集思维能力的方法使所有员工在他们工作领域内做的最好。这是 战略方针管理的基本原则。 合适的参与者: 中层经理,项目经理,过程改进小组