本文主要是介绍为机器学习模型选择正确的度量评估(第一部分),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
前戏作者:Alvira Swalin
编译:ronghuaiyang
对不同的应用场景,需要不同的模型,对于不同的模型,需要不同的度量评估方式。
本系列的第一部分主要关注回归的度量

在后现代主义的世界里,相对主义的各种形式一直是最受欢迎和最受唾弃的哲学理论之一。根据相对主义,不存在普遍客观的真理,相反,每个观点都有自己的道理。你一定想知道我为什么要讨论它,以及它是如何与数据科学相关的。
在这篇文章中,我将讨论每个误差度量的有用性,这取决于目标和我们试图解决的问题。当有人告诉你“美国是最好的国家”时,你应该问的第一个问题是这个说法是基于什么。我们是否根据每个国家的经济状况或卫生设施等来评价它们?类似地,每个机器学习模型都试图使用不同的数据集来解决具有不同目标的问题,因此,在选择度量标准之前了解上下文非常重要。
最有用的度量
在第一个博客中,我们将只讨论回归中的度量指标。
回归的度量
大多数博客关注的是分类指标,如精确度、召回率、AUC等。作为一个改变,我想探索所有类型的指标,包括那些在回归中使用的。MAE和RMSE是连续变量最常用的两个度量标准。让我们从更流行的开始。
RMSE (均方根误差)
它表示预测值与观测值之差的样本标准差(称为残差)。数学上,它是用这个公式计算的:
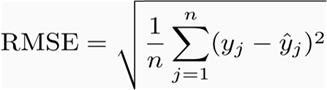
MAE
MAE是预测值与观测值之间的绝对差的平均值。MAE是一个线性的分数,这意味着所有的个体差异在平均值中被平均加权。例如,10和0之间的差是5和0之间差的两倍。然而,RMSE的情况并非如此,我们将进一步详细讨论。数学上,它是用这个公式计算的:
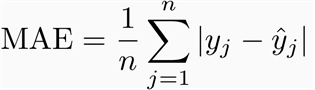
你应用哪个呢,为什么?
很容易理解和解释MAE,因为它直接取偏移量的平均值,而RMSE比MAE更能惩罚高的差值。
让我们通过两个例子来理解上面的陈述:
案例1:实际值=[2,4,6,8],预测值= [4,6,8,10]
案例2:实际值=[2,4,6,8],预测值= [4,6,8,12]
MAE for case 1 = 2.0, RMSE for case 1 = 2.0MAE for case 2 = 2.5, RMSE for case 2 = 2.65
从上面的例子中,我们可以看到RMSE比MAE更严重地惩罚了最后一个值预测。一般来说,RMSE将高于或等于MAE。它等于MAE的唯一情况是,所有的差异都相同或为零(对于第一个情况,实际和预测之间的差异是2,对于所有的观测值)。
然而,即使是更加复杂和偏向于更高的偏差,RMSE仍然是许多模型的默认度量,因为根据RMSE定义的损失函数是平滑可微的,并且使其更容易执行数学操作。
虽然这听起来不是很令人愉快,但这是一个非常重要的原因,并使它非常受欢迎。我将试着用数学的方法来解释上面的逻辑。
我们取一个简单的线性模型,其中一个变量是y = mx+b
在这里,我们试图找到“m”和“b”,我们得到了(x,y)的数据。
如果我们用RMSE定义损失函数(J),那么我们可以很容易地微分J wrt。到m和b,得到更新后的m和b(这就是梯度下降的原理,我不会在这里解释)
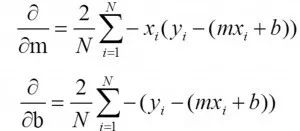
上面的方程解起来更简单,同样的方法不适用于MAE。
然而,如果你只想从解释的角度比较两个模型之间的度量,那么我认为MAE是一个更好的选择。重要的是要注意RMSE和MAE的单位都与y值相同,但对于R平方不成立。RMSE和MAE的范围是从0到无穷。
我之前忘记提到的MAE和RMSE之间的一个重要区别是,最小化一组数字的平方误差会得到平均值,最小化绝对误差会得到中值。这就是为什么MAE对于异常值是健壮的,而RMSE不是。这个答案详细解释了这个概念。
R Squared (R²) and Adjusted R Squared
R Squared和Adjusted R Squared通常用于解释目的,解释你选择的自变量如何很好地解释你的因变量的可变性。这两个指标都被误解了,因此在讨论它们的优缺点之前,我想先澄清它们。
数学上,R_Squared由下面的式子给出:
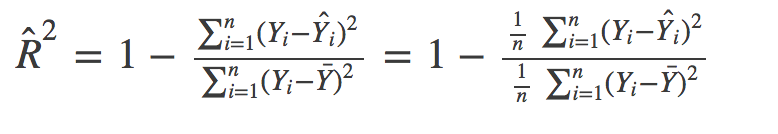
分子是MSE(残差平方和的平均值)分母是Y值的方差。MSE越高,R_squared越小,模型越差。
Adjusted R²
就像R²,Adjusted R²也显示了特征项是如何拟合模型的,模型是如何通过特征项的数量进行调整的。由下式给出:
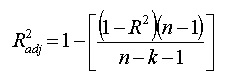
其中n为观测总数,k为特征项的数量。Adjusted R²总是小于或等于R²
为什么你选择Adjusted R²而不是R²?普通R²存在一些问题,需要由Adjusted R²解决。Adjusted R²会考虑由模型中的一个额外的项所带来的基于margin的提升。所以如果你增加有用的项它会增加如果你增加没用的预测项它会减少。然而,项增加了,R²就会增加,即使模型实际上并没有改善。通过一个示例更容易理解这一点。

在这里,情况1是一个简单的例子我们有5个(x,y)的观测值。在case 2中,我们还有一个变量,它是变量1的2倍(与var1完全相关),在case 3中,我们对var2进行了轻微的扰动,使得它不再与var1完全相关。
因此,如果我们对每种情况都使用简单的普通最小二乘(OLS)模型,那么从逻辑上讲,我们并没有就情况1向情况2和情况3提供任何额外的或有用的信息。所以我们的度量值不应该对这些模型有所改善。然而,对于R²并不是这样,对于模型2和3,R²的值更大。但是你用adjusted R²来处理这个问题,实际上对于这两种情况2 & 3,R²的值都变小了。我们给这些变量(x,y)一些数字,看看在Python中得到的结果。
注:预测值对于模型1和模型2都是一样的,因此R_squared也是一样的,因为它只依赖于预测值和实际值。

从上面的表中,我们可以看到,尽管我们没有添加任何额外信息,R²仍然在增加,而adjusted R²显示了正确的趋势(对模型2更多数量的变量进行了惩罚)。
比较Adjusted R²和RMSE 前面的例子,我们将看到,RMSE相同情况1和情况2类似于R²。在比较预测值和实际值的情况下,Adjusted R²比RMSE做的要好。此外,RMSE的绝对值实际上并不能说明一个模型有多糟糕。它只能用于比较两个模型而Adjusted R²比较容易衡量一个模型的好坏。例如,如果一个模型Adjusted R²等于0.05那绝对是很惨的。
然而,如果你只关心预测的准确性,那么RMSE是最好的。它计算简单,易于微分,并且作为大多数模型的默认度量。
常见的误解:我经常在网上看到,R²的范围在0和1之间,不是这样的。R²的最大值是1,但最小可以负无穷。考虑这样一种情况:即使y_actual是正数,模型仍然预测所有观察值为绝对值很大的负值。在这种情况下,R²将小于0。这种情况极不可能发生,但这种可能性仍然存在。
红利!
如果你对NLP感兴趣的话,这里有一个有趣的衡量标准值得你去了解。我最近在Andrew Ng Deep Learning course上了解到它,觉得它值得分享。
计算BLEU得分的步骤:
将句子转换成单字、二字、三字和四字
计算大小为1到4的n-grams的精度
取所有这些精度值的加权平均值的指数
将其与简洁性惩罚项相乘(稍后解释)
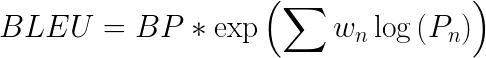
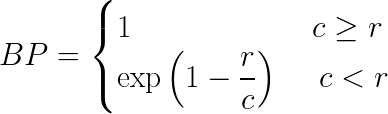
其中BP为简洁性惩罚,r & c为参考字数和候选字数,w -权值,P -精度值。
例子:
参考:The cat is sitting on the mat
机器翻译1:On the mat is a cat
机器翻译2:There is cat sitting cat
让我们将以上两个译本与BLEU评分进行比较。
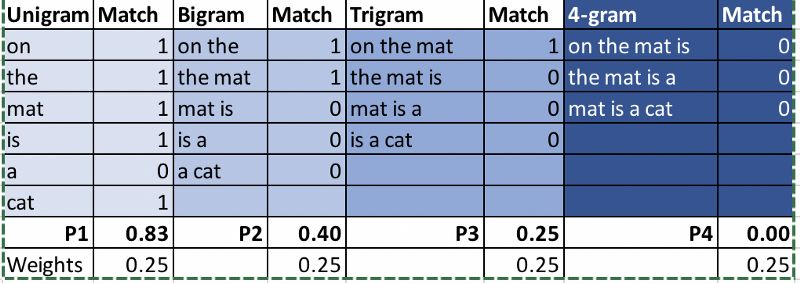
让我们将以上两个译本与BLEU评分进行比较。
这里使用的是nltk.translate.bleu_score 包。
最终结果:BLEU (MT1) = 0.454,BLEU (MT2) = 0.59
为什么我们要增加简洁惩罚?简洁惩罚项惩罚比参考译文短的翻译。例如,如果上面提到的引用的候选词是“the cat”,那么它对于unigram和bigram就有很高的精度,因为这两个单词在引用中以相同的顺序出现。然而,长度太短,并不能真正反映参考的意义。
有了这种简洁性惩罚,高分候选翻译必须在长度、相同的单词和单词顺序方面匹配引用。
 — END—
— END— 英文原文:https://medium.com/usf-msds/choosing-the-right-metric-for-machine-learning-models-part-1-a99d7d7414e4

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于为机器学习模型选择正确的度量评估(第一部分)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






