本文主要是介绍度量学习相关 - 简单记录(代码和阅读材料),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
20210312 -
0. 引言
(本人非专业人士,仅仅记录自己的简单理解,本人所引用代码或文章并未经过实际验证,仅仅参考其中主要思想,如有报错请自行解决)
度量学习会在神经网络的训练中,加入或者直接使用相似度作为目标。之前在上一门课程的时候,正好阅读过一篇与此相关的顶会文章,当时对其有了简单理解。简单说,就是讲相似度比较加入到神经网络的结构或者训练目标中。本篇文章用来记录一些相关的内容。
1. 孪生网络(对比损失contrastive loss)
1.1 直接代码
本部分参考文章[1]进行记录。
1.1.1 大致原理
在文章[1]中,通过非常简答的介绍,说明了孪生网络,下图来自文章[1],可见其中的大致原理。

从图上大致的原理来看,可以看到几个关键点:两个输入,一个输出(0/1),同时两个处理的模型权值共享。从这个角度来看(同时结合代码),那么孪生网络的作用就是,通过创造输入对,而两个输入对的输出是相似度大小,一般为0-1范围内。
1.1.2 关键代码
在文章[1]中列出了完整代码,代码并没有经过验证,但是列出几个关键点作为后续时候的时候需要思考的地方。
1)模型的构建过程
# network definition
base_network = create_base_net(input_shape)input_a = Input(shape=input_shape)
input_b = Input(shape=input_shape)
processed_a = base_network(input_a)
processed_b = base_network(input_b)
distance = Lambda(euclid_dis,output_shape=eucl_dist_output_shape)([processed_a, processed_b])
model = Model([input_a, input_b], distance)
这种编程方式是keras编程的一种方式,这种方式可能在不了解keras的情况下,有些疑惑。
所以这里在后续使用的时候要注意。
2)损失函数
def contrastive_loss(y_true, y_pred):margin = 1square_pred = K.square(y_pred)margin_square = K.square(K.maximum(margin - y_pred, 0))return K.mean(y_true * square_pred + (1 - y_true) * margin_square)
对于自定义损失函数,可以从官方提供的损失函数入手,同时考虑怎么贴合自己的需求公式。
1.1.3 训练可视化
在文章[2]中,其前面的核心代码与文章[1]一致,但是最后多了一个可视化的部分,可视化的代码也比较简单,就是下面这些。
embeddings = base_network.predict(x_train)from sklearn.manifold import TSNE
X_embedded = TSNE(n_components=2,random_state=10).fit_transform(embeddings)mnist_classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728','#9467bd', '#8c564b', '#e377c2', '#7f7f7f','#bcbd22', '#17becf']plt.figure(figsize=(10,10))
for i in range(10):inds = np.where(y_train==i)[0]plt.scatter(X_embedded[inds,0], X_embedded[inds,1], alpha=0.5, color=colors[i])
plt.legend(mnist_classes)

从这个图像上来看,各个类别的边界还是挺清晰的。
(20210407 添加)
在使用center loss进行查看中间层的可视化效果的时候,因为中间层并不是设置的论文中的2,而是一个大数,所以需要利用t-sne进行降维可视化,但是这种方式查看时,发现用不用center,区别不是很大,虽然用了center-loss有那么点效果,但不是非常明显,并不是跟论文中一样,那么紧凑。
结合之前学习了t-sne的原理,我觉得应该是这种可视化方法的问题;当然为了尽快查看效果,训练时间也比较短。
2. Center Loss
2.1 原理解释
中心损失是2016年发表的一篇文章,《A Discriminative Feature Learning Approach for Deep Face Recognition》,意思是说能够利用这种方法,得到比较好的区分度高的特征。文章[3]中用比较简单的说法提供了一种非常好的解释过程。虽然有些地方感觉深度不够,导致没理解,整体上还是能够理解的。
实际上,Center Loss我感觉应该不属于严格意义上的度量学习,虽然也带有那个味(个人愚见)。
但是这个损失函数的好处在于,能够将学习分类的过程和相似度度量的过程结合在一起,以往还有很多例如(初始的)三元损失那些,本质上都是为了提高相似度,但是没有在网络中加入这种因素,说白了,就是在训练过程中没有导入这种因素,让这个因素能够推动网络结构进行改变。当然,现在好像也有魔改的三元损失能够加入分类损失。
文章[4]中的解释更为学术化,而且解释了与一些其他的方法contrastive loss 和 triplets loss的对比。中心损失的大致公式如下:
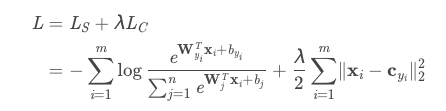
(偷懒直接复制图片过来)

不过,看了很多地方都反馈说Center Loss最后的分类效果并不好,但是我觉得,这种思路也是要尝试尝试才知道。
2.2 代码部分
在github上搜索相关代码能够搜索到很多,这里简单介绍几个。首先第一个[5]是我具体看了这部分代码,看完之后感觉对于损失函数的部分的代码非常精巧,直接列出来代码
if isCenterloss:lambda_c = 0.2input_target = Input(shape=(1,)) # single value ground truth labels as inputscenters = Embedding(10,2)(input_target)l2_loss = Lambda(lambda x: K.sum(K.square(x[0]-x[1][:,0]),1,keepdims=True), name='l2_loss')([ip1,centers])model_centerloss = Model(inputs=[inputs,input_target],outputs=[ip2,l2_loss]) model_centerloss.compile(optimizer=SGD(lr=0.05), loss=["categorical_crossentropy", lambda y_true,y_pred: y_pred],loss_weights=[1,lambda_c],metrics=['accuracy'])
还要在模型训练的时候,也需要注意。从代码上看,感觉代码的罗技非常简单,甚至损失函数都没有具体放置于一个函数里面,当然这也无所谓。重点在于作者在自己的网页上对这部分代码进行了解释[6]。具体可以按照作者的思路来理解。
2.2 不同的代码实现(20210407)
在前面2.2的内容中,提供了一种代码实现方式,利用keras的嵌入层来实现类别中心的存储;但是如果对照原始论文的话,就可以看到,这种方式没有体现出来类别中心更新的过程,也就是有一个alpha的参数来控制中心是如何更新的。如果使用嵌入层的话,那么就是利用这个网络自身的优化过程来进行优化。但是我仔细想了想,虽然能够明白他是用来存储这个中心矩阵,但是具体是怎么更新的,理解不了。既然这样的话,还是参考别的代码,因为要对这个中心点矩阵进行存储,那么就需要利用自定义层来实现中心的存储。
参考
[1]Training Siamese Network on MNIST dataset
[2]Keras siamese network on MNIST
[3]CenterLoss——实战&源码
[4]Center Loss
[5]shamangary/Keras-MNIST-center-loss-with-visualization
[6]Code explanation in center loss github
这篇关于度量学习相关 - 简单记录(代码和阅读材料)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








