本文主要是介绍YOLOv9改进|增加SPD-Conv无卷积步长或池化:用于低分辨率图像和小物体的新 CNN 模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!!
一、文章摘要
卷积神经网络(CNNs)在计算即使觉任务中如图像分类和目标检测等取得了显著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会灾难性下降。这是由于现有CNN常见的设计体系结构中有缺陷,即使用卷积步长和/或池化层,这导致了细粒度信息的丢失和较低效的特征表示的学习。为此,我们提出了一个名为SPD-Conv的新的CNN构建块来代替每个卷积步长和每个池化层(因此完全消除了它们)。SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,可以应用于大多数CNN体系结构。我们从两个最具代表性的计算即使觉任务:目标检测和图像分类来解释这个新设计。然后,我们将SPD-Conv应用于YOLOv5和ResNet,创建了新的CNN架构,并通过经验证明,我们的方法明显优于最先进的深度学习模型,特别是在处理低分辨率图像和小物体等更困难的任务时。
适用检测目标: 通用下采样模块
二、SPD-Conv模块详解
论文地址: https://arxiv.org/pdf/2208.03641v1.pdf
2.1 模块简介
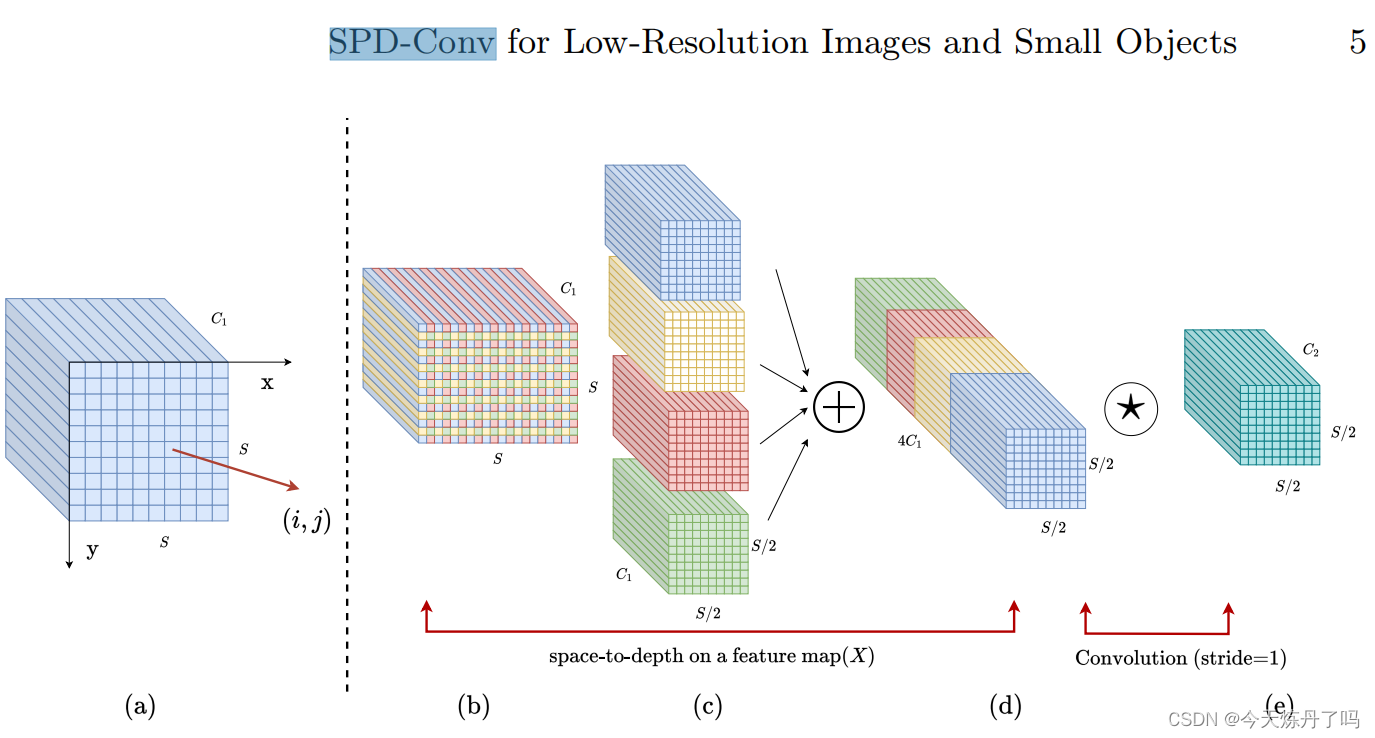
SPD-Conv的主要思想: SPD- conv由一个空间到深度(SPD)层和一个非跨步卷积层组成。SPD组件推广了一种(原始)图像转换技术来对CNN内部和整个CNN的特征映射进行下采样。
总结: 一种通过卷积与线性变化实现的新下采样模块。
SPD- conv模块的原理图
三、SPD-Conv模块使用教程
3.1 SPD-Conv模块的代码
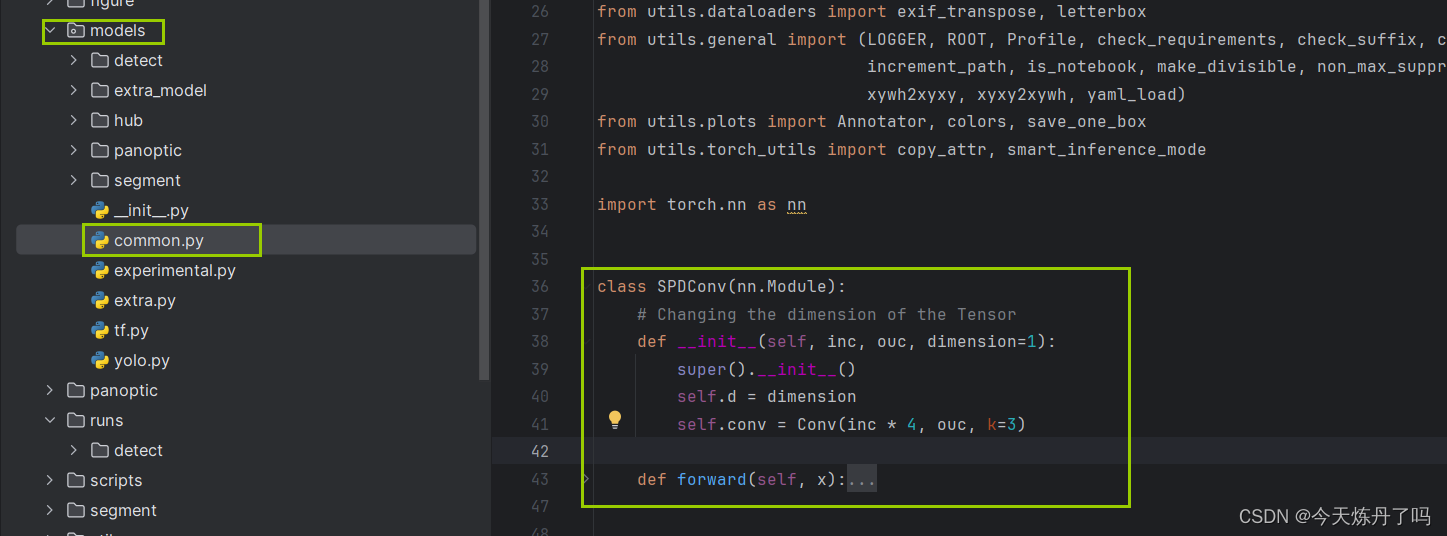
class SPDConv(nn.Module):# Changing the dimension of the Tensordef __init__(self, inc, ouc, dimension=1):super().__init__()self.d = dimensionself.conv = Conv(inc * 4, ouc, k=3)def forward(self, x):x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)x = self.conv(x)return x3.2 在YOlO v9中的添加教程
阅读YOLOv9添加模块教程或使用下文操作
1. 将YOLOv9工程中models下common.py文件中增加模块的代码。
2. 将YOLOv9工程中models下yolo.py文件中的第718行(可能因版本变化而变化)增加以下代码。
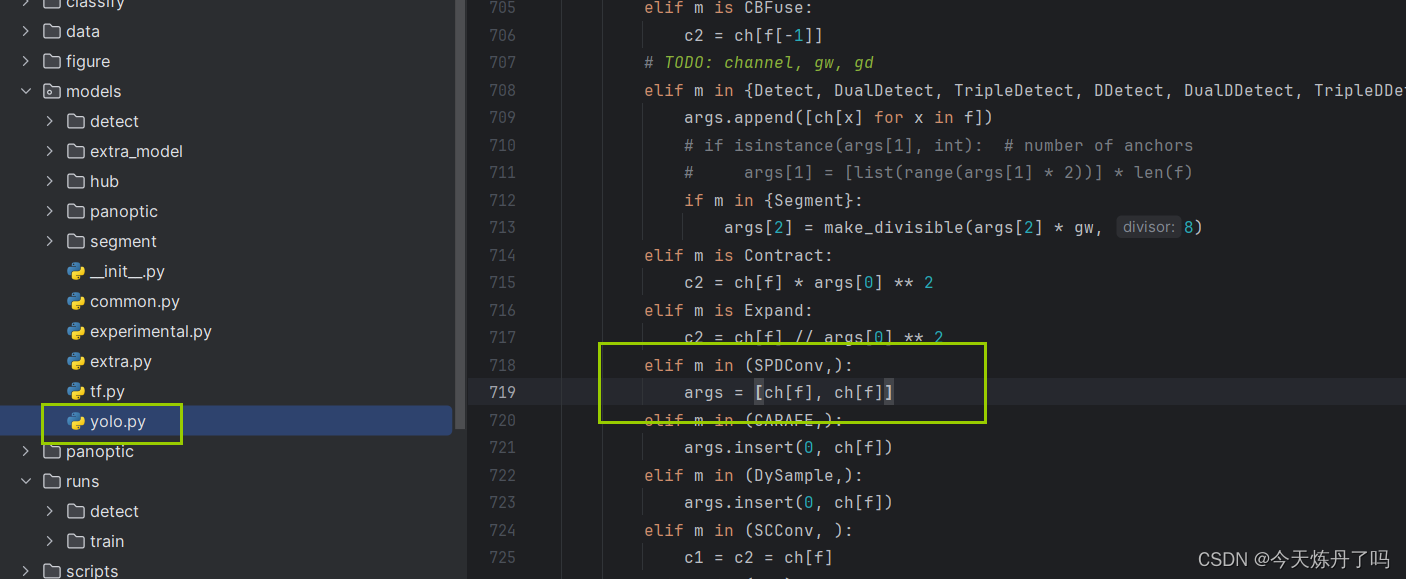
elif m in (SPDConv,):args = [ch[f], ch[f]]3.3 运行配置文件
# YOLOv9
# Powered bu https://blog.csdn.net/StopAndGoyyy# parameters
nc: 80 # number of classes
#depth_multiple: 0.33 # model depth multiple
depth_multiple: 1 # model depth multiple
#width_multiple: 0.25 # layer channel multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# avg-conv down[-1, 1, SPDConv, []], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# avg-conv down fuse[-1, 1, ADown, [256]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# avg-conv down fuse[-1, 1, ADown, [512]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# avg-conv down fuse[-1, 1, ADown, [512]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37# detection head# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
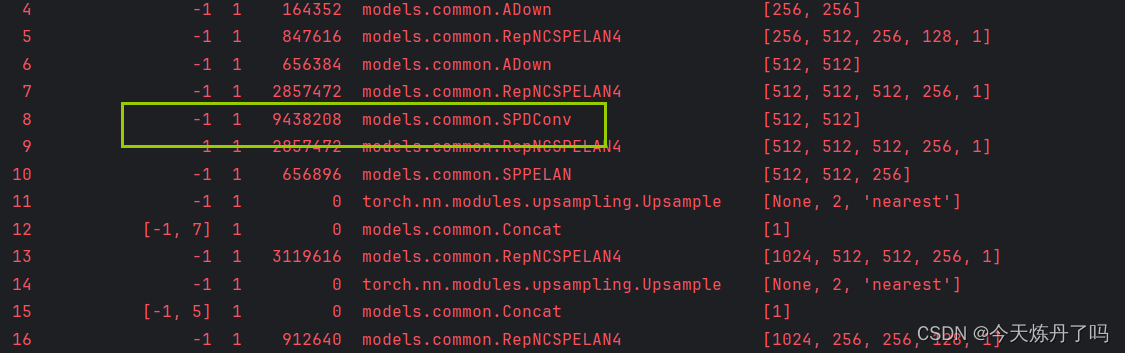
3.4 训练过程
欢迎关注!
这篇关于YOLOv9改进|增加SPD-Conv无卷积步长或池化:用于低分辨率图像和小物体的新 CNN 模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





