本文主要是介绍助力智能化农田作物除草,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在我们前面的系列博文中,关于田间作物场景下的作物、杂草检测已经有过相关的开发实践了,结合智能化的设备可以实现只能除草等操作,玉米作物场景下的杂草检测我们则少有涉及,这里本文的主要目的就是想要基于YOLOv7系列的模型来开发构建玉米田间作物场景下的玉米苗和杂草检测识别系统。
春节前后我们已经基于YOLO系列最新的YOLOv8模型开发构建了相应的项目,感兴趣可以自行移步阅读:
《助力智能化农田作物除草,基于轻量级YOLOv8n开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
《助力智能化农田作物除草,基于YOLOv8全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
随后我们基于首个端到端的目标检测模型DETR开发构建了相应的检测模型,如下:
《助力智能化农田作物除草,基于DETR(DEtection TRansformer)模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
完成上述开发之后,我们想尝试基于早期开山的YOLOv3模型来开发构建对应的检测模型,如下所示:
《助力智能化农田作物除草,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
之后我们基于同样的数据使用最为经典的YOLOv5系列的模型来开发构建对应的检测模型,如下:
《助力智能化农田作物除草,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
YOLOv5全系列的模型表现亮眼,激发了我们更进一步的想法,这里我们随后就基于美团视觉团队发布的最新YOLOv6分支模型同样的数据场景开发构建了对应的检测模型,如下:
《助力智能化农田作物除草,基于YOLOv6全系列【n/s/m/l】参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统》
至此,整个YOLO家族只剩下YOLOv7尚未使用,所以本文的主要目的就是想要填补这一空挡,来开发对应的检测模型。
首先看下实例效果:
YOLOv7是 YOLO 系列最新推出的YOLO 结构,在 5 帧/秒到 160 帧/秒范围内,其速度和精度都超过了大部分已知的目标检测器,在 GPU V100 已知的 30 帧/秒以上的实时目标检测器中,YOLOv7 的准确率最高。根据代码运行环境的不同(边缘 GPU、普通 GPU 和云 GPU),YOLOv7 设置了三种基本模型,分别称为 YOLOv7-tiny、YOLOv7和 YOLOv7-W6。相比于 YOLO 系列其他网络 模 型 ,YOLOv7 的 检 测 思 路 与YOLOv4、YOLOv5相似,YOLOv7 网络主要包含了 Input(输入)、Backbone(骨干网络)、Neck(颈部)、Head(头部)这四个部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过 Neck 模块特征融合处理得到大、中、小三种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
YOLOv7 网络模型的主干网部分主要由卷积、E-ELAN 模块、MPConv 模块以及SPPCSPC 模块构建而成 。在 Neck 模块,YOLOv7 与 YOLOv5 网络相同,也采用了传统的 PAFPN 结构。FPN是YoloV7的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV7里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。Head检测头部分,YOLOv7 选用了表示大、中、小三种目标尺寸的 IDetect 检测头,RepConv模块在训练和推理时结构具有一定的区别。
简单看下实例数据情况:


训练数据配置文件如下所示:
# txt path
train: ./dataset/images/train
val: ./dataset/images/test
test: ./dataset/images/test# number of classes
nc: 3# class names
names: ['maize', 'weedhe', 'weedkuo']这里主要是选择了yolov7-tiny、yolov7和yolov7x这三款不同参数量级的模型来进行开发训练,最终线上选取的是yolov7系列的模型作为推理模型,这里给出来yolov7的模型文件:
# parameters
nc: 3 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2 [-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, Conv, [64, 1, 1]],[-2, 1, Conv, [64, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 11[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8 [-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 24[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]], # 29-P4/16 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 37[-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]], # 42-P5/32 [-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 50]# yolov7 head
head:[[-1, 1, SPPCSPC, [512]], # 51[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, Conv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, Conv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[75, 1, RepConv, [256, 3, 1]],[88, 1, RepConv, [512, 3, 1]],[101, 1, RepConv, [1024, 3, 1]],[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
在实验阶段保持完全相同的参数设置,等待全部训练完成之后来从多个指标的维度来进行综合的对比分析。
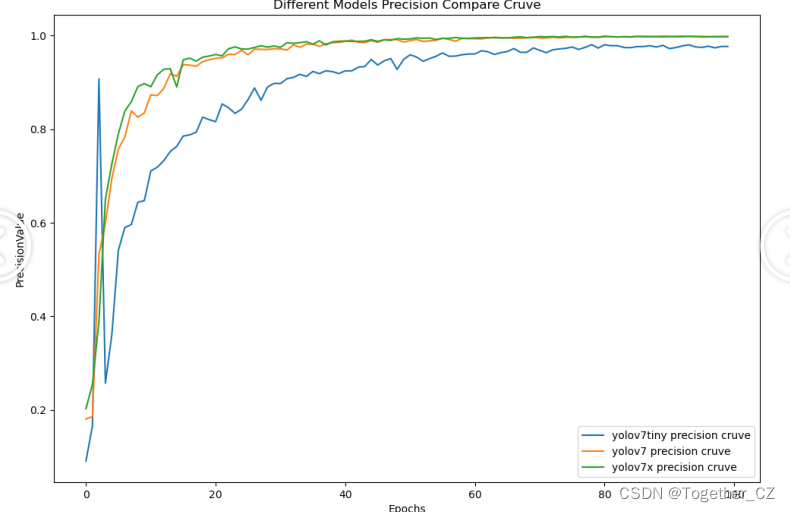
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率曲线。
根据精确率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察精确率曲线,我们可以根据需求确定最佳的阈值,以平衡精确率和召回率。较高的精确率意味着较少的误报,而较高的召回率则表示较少的漏报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
精确率曲线通常与召回率曲线(Recall Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。
召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
绘制召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的召回率和对应的精确率。
将每个阈值下的召回率和精确率绘制在同一个图表上,形成召回率曲线。
根据召回率曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
通过观察召回率曲线,我们可以根据需求确定最佳的阈值,以平衡召回率和精确率。较高的召回率表示较少的漏报,而较高的精确率意味着较少的误报。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
召回率曲线通常与精确率曲线(Precision Curve)一起使用,以提供更全面的分类器性能分析,并帮助评估和比较不同模型的性能

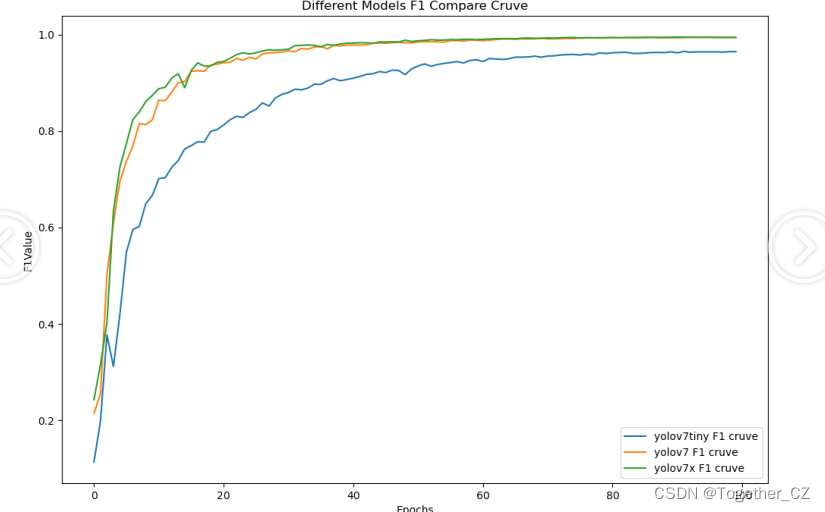
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。
F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
绘制F1值曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率、召回率和F1分数。
将每个阈值下的精确率、召回率和F1分数绘制在同一个图表上,形成F1值曲线。
根据F1值曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
F1值曲线通常与接收者操作特征曲线(ROC曲线)一起使用,以帮助评估和比较不同模型的性能。它们提供了更全面的分类器性能分析,可以根据具体应用场景来选择合适的模型和阈值设置。
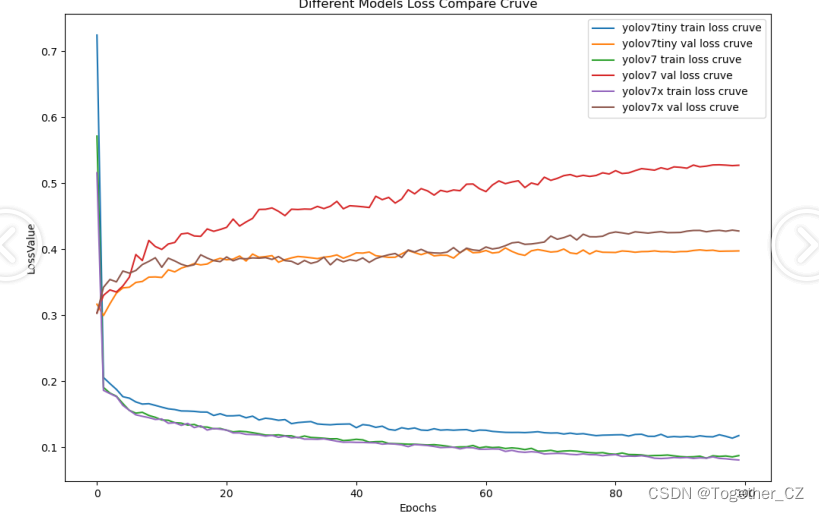
【loss曲线】
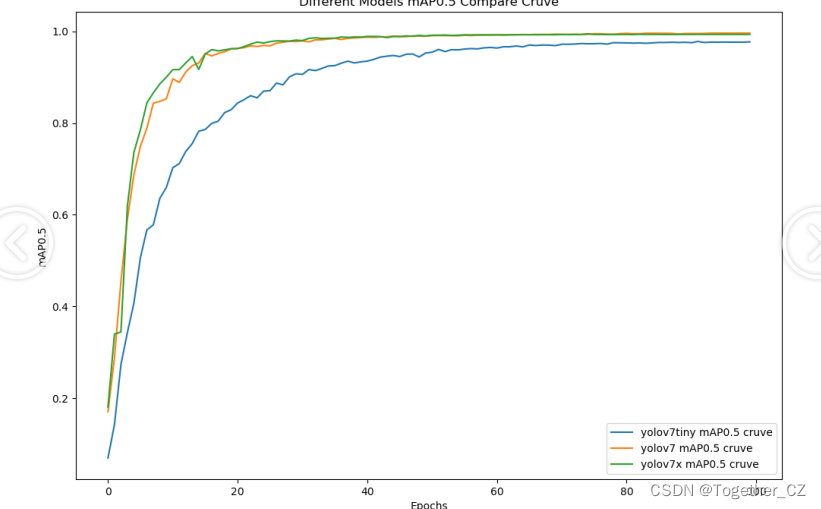
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
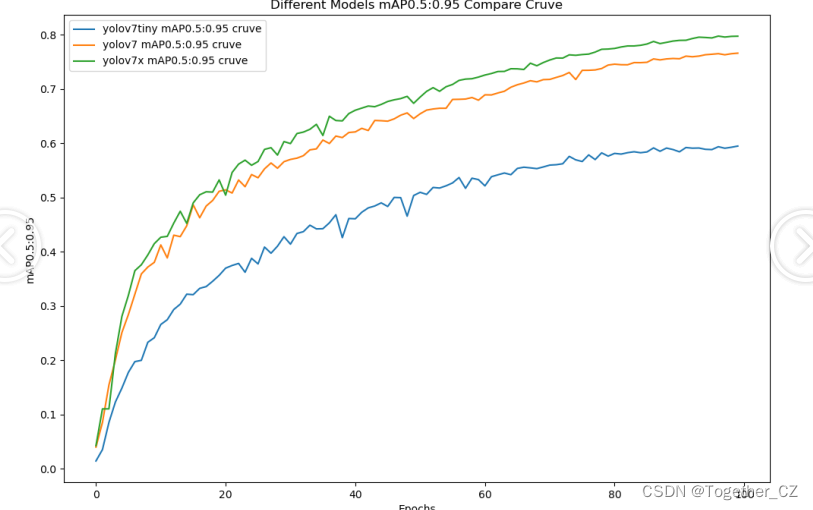
从整体实验对比结果来看:tiny系列模型的效果最次,被l和x系列的模型拉开了明显的差距,l和x系列的模型则达到了几近相同的水准,考虑到计算量的问题,这里最终选择使用yolov7来作为最终模型。
接下来我们详细看下yolov7模型的结果详情。
【Batch实例】


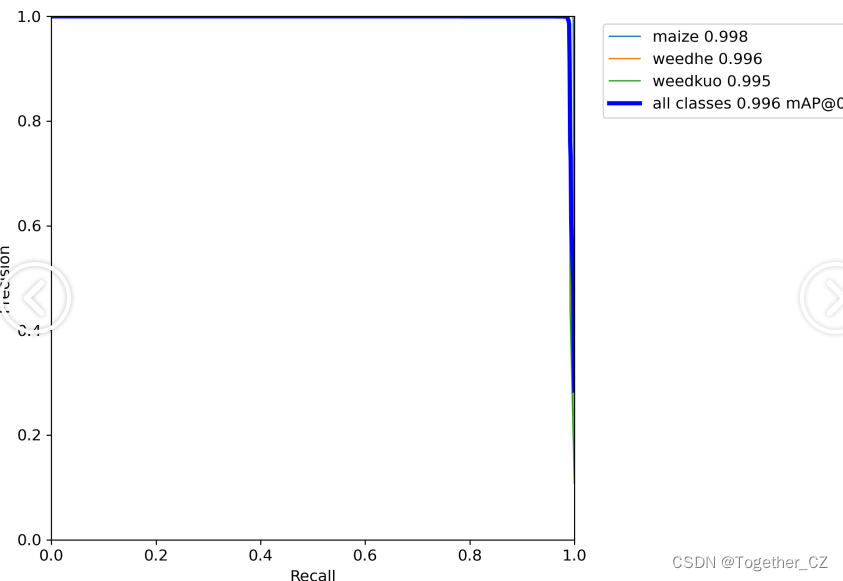
【PR曲线】
【训练可视化】

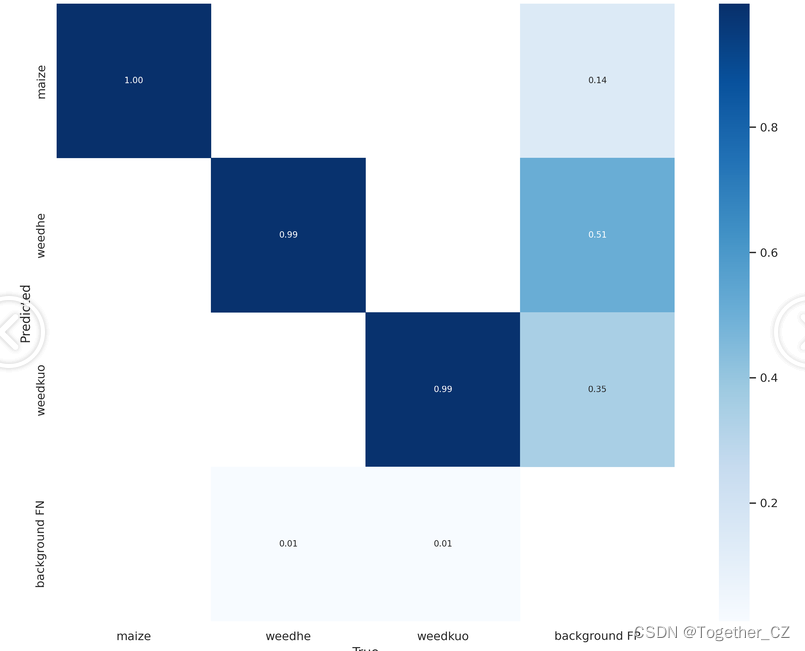
【混淆矩阵】
【离线推理实例】
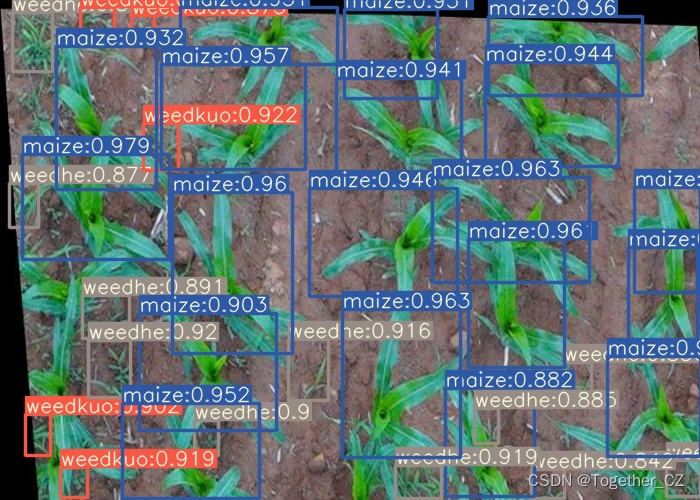
感兴趣的话都可以自行动手尝试下!
如果自己不具备开发训练的资源条件或者是没有时间自己去训练的话这里我提供出来对应的训练结果可供自行按需索取。
单个模型的训练结果默认YOLOv7-tiny
全系列三个模型的训练结果总集
这篇关于助力智能化农田作物除草,基于YOLOv7【tiny/l/x】不同系列参数模型开发构建农田作物场景下玉米苗、杂草检测识别分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





