本文主要是介绍ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视听语音识别(Audio-visual speech recognition, AVSR)是指结合音频和视频信息对语音进行识别的技术。当前,语音识别(ASR)系统在准确性在某些场景下已经达到与人类相媲美的水平。然而在复杂声学环境或远场拾音场景,如多人会议中,ASR系统的性能可能会受到背景噪音、混响和多人说话的重叠的干扰而严重下降。基于视频的视觉语音识别(VSR)系统通常不会受到声学环境的干扰。因此,越来越多的研究人员开始关注将视觉信息引入ASR中。在视听语音识别模型中,如何高效地融合音视频信息长期以来都是提升性能的关键。目前主流的融合方法有两种,一是对原始音视频数据进行融合,二是对建模后的音视频特征进行融合。前者更注重音视频在数据层面的高效融合,强调不同模态信息的越早融合对最终AVSR系统性能越有利,我们通常称之为早融合 (early fusion);而后者则是对建模后的音视频特征,一般情况下是音/视频编码器的输出进行融合,我们通常称其晚融合 (late fusion)。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和理想汽车合作论文“MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition”被语音研究顶级会议ICASSP2024接收。该论文提出了一种基于多层交叉注意力机制的视听语音识别方案,通过在音频和视频编码器的不同层中植入交叉注意力模块,建模音视频信息的同时同步进行音视频模态融合,我们称其为中融合 (middle fusion)。实验结果表明,MLCA-AVSR方案在MISP2022-AVSR数据集上的效果超过了MISP2022挑战赛AVSR赛道的第一名。现对该论文进行简要的解读和分享。

论文题目:MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition
合作单位:理想汽车
作者列表:王贺、郭鹏程、周盼、谢磊
论文原文:https://arxiv.org/abs/2401.03424

论文截图
背景动机
目前大量关于视听语音识别 (AVSR) 的研究表明,将视觉信息整合到语音识别 (ASR) 模型中可以显著增强识别系统在复杂声学环境中的鲁棒性。Ma等人[1]提出了一种端到端的双编码器混合CTC/Attention AVSR方案,其中包括基于ResNet的视觉编码器、基于Conformer的音频编码器和一个多层感知模块 (MLP) 来融合不同的模态特征。与MLP的融合策略相比,Sterpu等人[2]首次引入了基于注意力的融合机制,并发现学习不同模态特征之间的对齐信息是提高性能的关键。随后,一些研究[3, 4]采用了交叉注意力模块来捕捉建模后的音视频特征之间的对齐和互补信息。此外,利用来自音频和视觉编码器不同层特征可以提升AVSR系统的性能也得到了许多研究的证实[5, 6]。
近期,基于多模信息的语音处理(MISP)挑战系列[7, 8],旨在探索远场多麦克风信号处理任务(如关键词检测和语音识别)中如何合理使用音视频双模信息,如图1所示。在MISP2022挑战赛的音视频语音分离和识别 (AVDR) 赛道中,参赛者们使用多通道音频数据和唇读视频数据来构建在家庭电视场景中的鲁棒远场语音识别系统。在比赛期间,我们提出了一种基于单层交叉注意力融合的AVSR系统 (SLCA-AVSR) [9],并取得了第二名的优异成绩。该系统使用交叉注意力模块来组合不同模态的特征。然而,这种方法是基于建模后的音视频特征进行模态融合,没有考虑在特征建模期间的上下文信息。尽管Li等人[10]探讨了多层级模态特征的融合,但基于连接的融合方法未能有效捕捉模态间的对齐信息。

图1 MISP竞赛的录制场景[7,8]
在本文中,我们提出了一种基于多层交叉注意力融合的视听语音识别(MLCA-AVSR)方案。具体而言,我们基于先前的SLCA融合模块,将其集成到音/视频编码器的不同中间层。通过在编码器不同层进行音视频特征融合,实现了从粗粒度建模特征到细粒度特征,一个模态从另一模态中学习建模时的上下文信息并对自身进行补充。此外,我们还采用了Inter-CTC损失[11]来引导每个交叉注意力模块的学习过程。据我们所知,这是第一次将交叉注意力模块集成到模态编码器的中间层,并在表示学习过程中同时进行模态融合的尝试。MISP2022-AVSR挑战数据集[7]上的实验结果表明,MLCA-AVSR方案超越了MISP2022挑战赛AVDR赛道的第一名,在此数据集上取得了新的最好结果。
MLCA-AVSR方案
交叉注意力

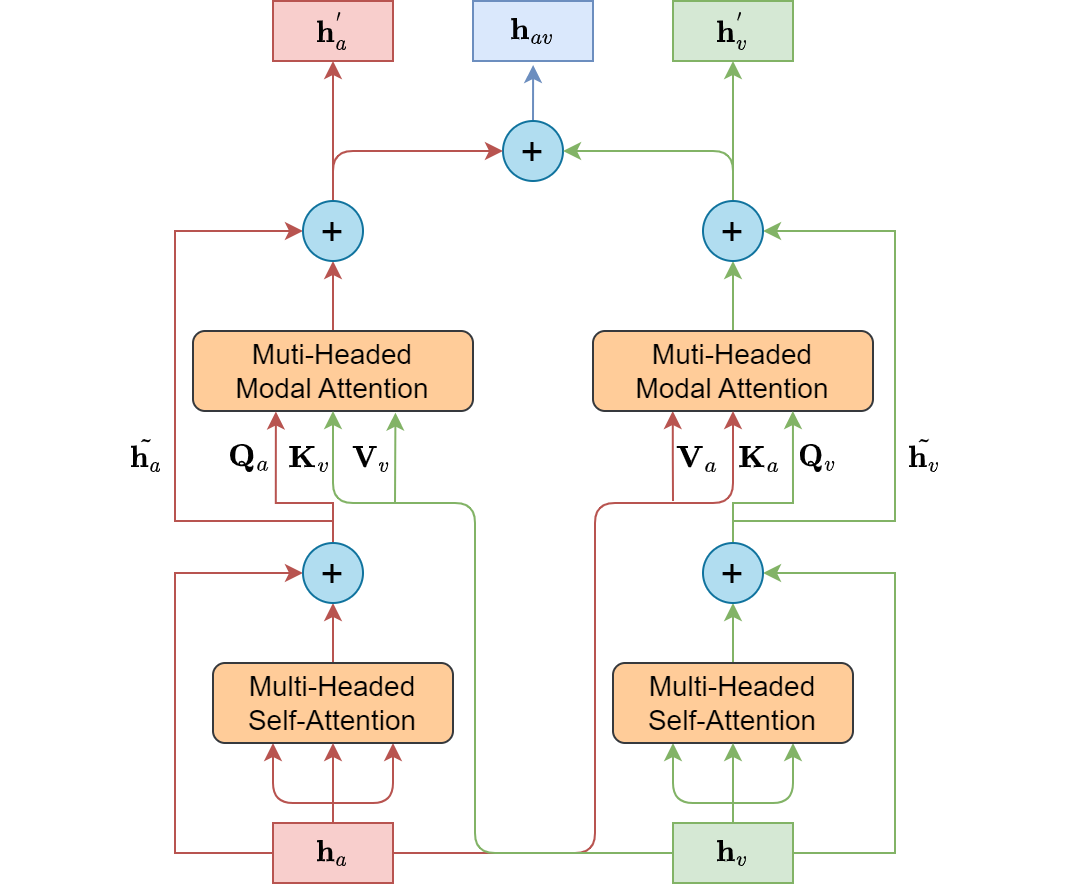
图2 交叉注意力模块示意图
多层交叉注意力融合
图3展示了MLCA-AVSR视听语音识别系统的结构,其包括四个主要组成部分,分别是音频和视觉前端、音频和视觉编码器、融合模块和解码器。我们采用了2层卷积下采样网络作为音频前端,ResNet3D网络作为视频前端,最近提出的E-Branchformer [12]作为音频和视觉编码器。同时,在音频和视觉编码器内引入了两个交叉注意力模块。这样一来,通过有效地利用编码器中不同层级的音视频特征,实现更好的多模态融合。

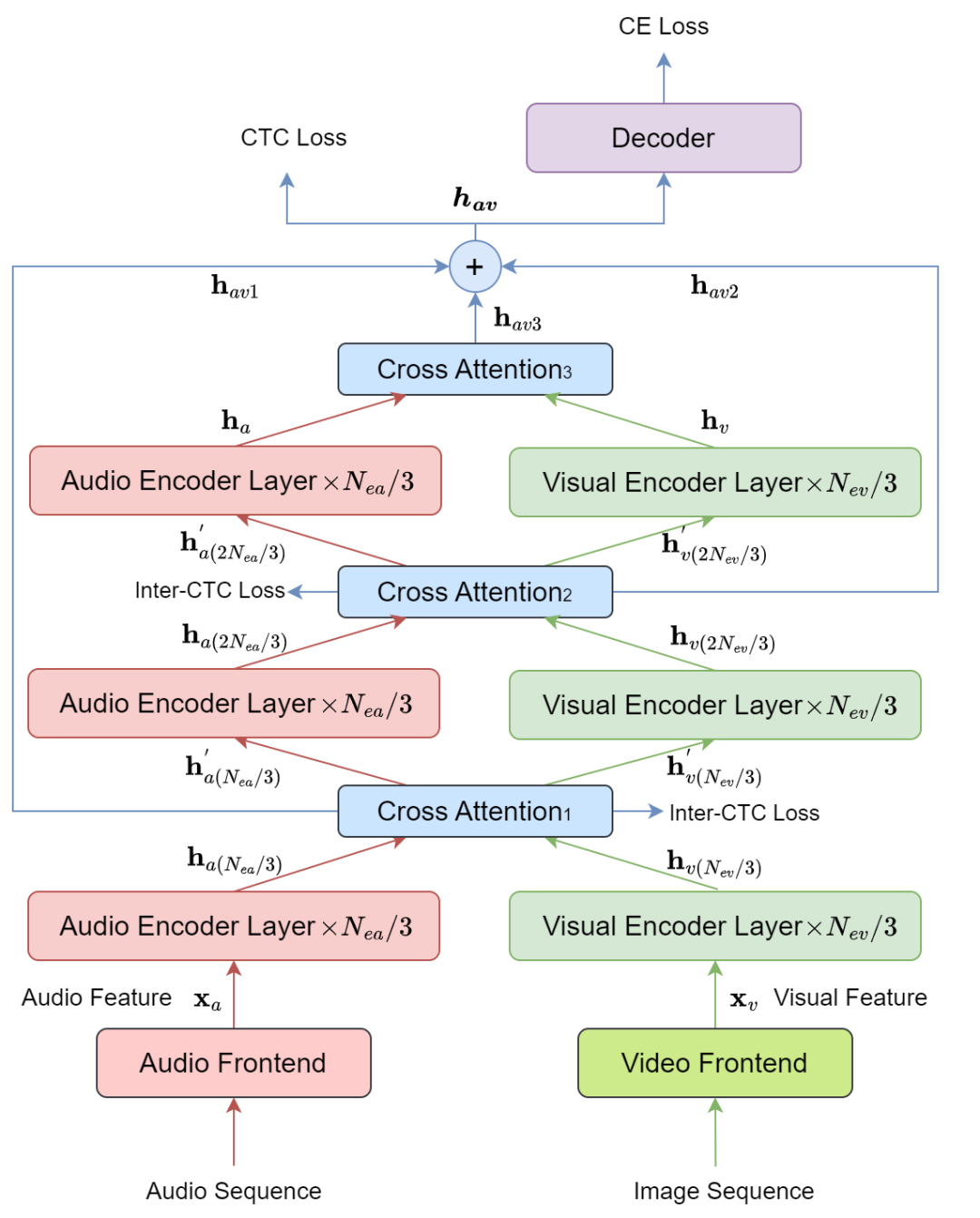
图3 MLCA-AVSR系统结构示意图
实验
数据处理
数据集 所有的模型训练和测试实验均在大规模的中文对话音视频语料库MISP2022-AVSR[7]上进行。该数据集由34个装有电视的家庭房间中的远/中/近麦克风和远/中摄像机收集而成,包含141小时的音视频数据。经由说话人日志时间戳切分后,训练、验证,测试集分别包含106.09小时、3.09小时和3.13小时的对话音视频数据。
音频处理 首先使用WPE和GSS算法对中远数据进行预处理,以有效提取每个说话者增强后的干净信号。随后,使用增强后的数据与原始的近场数据相结合,并进行0.9、1.0和1.1的速度扰动。为了模拟真实的声学环境,我们使用MUSAN [13]语料库和开源的pyroomacoustics工具包生成真实的背景噪声和房间脉冲响应(RIRs)。经过上述处理后,最终用于训练的音频数据总量约1300小时,包括预处理增强和模拟的数据。
视频处理 对于视频数据,我们裁剪与说话人嘴唇对应的区域(ROIs),并修改将其尺寸到112 112。在训练过程中,采用随机旋转、水平翻转和颜色抖动等策略来动态增强视频数据。
说话人日志 为了和MISP2022挑战赛参赛方案对比,我们使用了与参赛时一样的说话人日志 (SD)模型[14]来切分验证集 ( )和测试集 ( ),切分后的数据集分别表示为 和 。
实验设置
所有系统,包括 ASR、VSR 和 AVSR,均使用ESPnet工具包进行构建。对于音频ASR模型,我们使用了一个包含 24 层的 E-Branchformer 作为编码器,每层有 256 维、4 个注意力头和 1024 维的前馈内部线性投影。此外,解码器包含 6 个 Transformer 层,每层有 4 个注意力头和 2048 维的前馈。编码器和解码器的dropout都设置为 0.2。对于基于视频的 VSR 模型,视觉前端是一个包含 5 层的 ResNet3D 模块,通道数为 32、64、64、128、256,核大小为 3,视觉编码器是一个包含 9 层的 E-Branchformer,其他与 ASR 系统相同。为了验证 E-Branchformer 编码器的优越性能,我们还训练了与 E-Branchformer 相似模型大小的 Conformer 和 Branchformer ASR 和 VSR 模型。对于音频-视觉语音识别模型,交叉注意力模块使用了 4 个注意力头,每个头有 256 个注意力维度。在训练开始时,音频和视觉编码器分别使用预训练好的 ASR 和 VSR 模型进行初始化。
实验结果及分析
单模态 ASR 和 VSR 模型
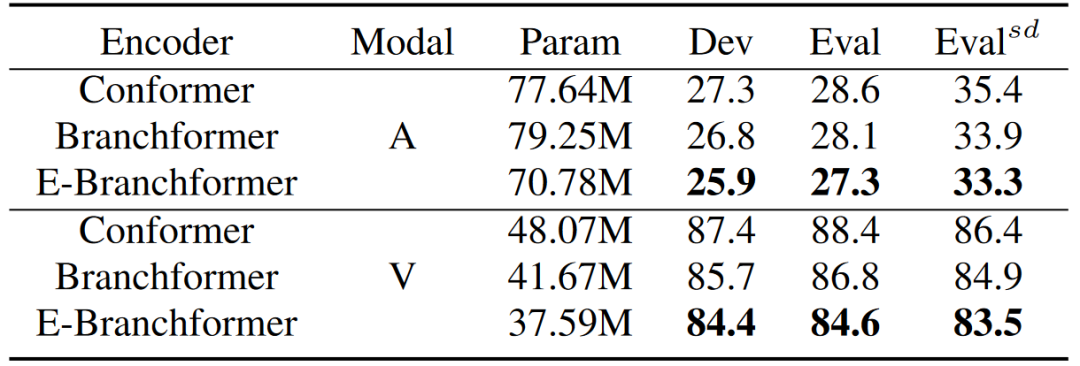
如表1所示,我们对Conformer、Branchformer和E-Branchformer编码器在ASR和VSR模型中进行性能比较。对于Conformer和Branchformer编码器,我们通过增加编码器层数或特征维度来扩展ASR和VSR系统的模型大小,确保比较的公平性。在MISP2022-AVSR数据集上的结果表明,E-Branchformer编码器在性能上优于Conformer和Branchformer编码器。具体而言,与Branchformer模型相比,E-Branchformer ASR和VSR模型在Eval集的CER上分别实现了0.8%和2.2%的相对下降,与Conformer模型相比,分别实现了1.3%和3.8%的相对下降。
表1 不同编码器的ASR、VSR模型在Dev和Eval集上的CER(%)结果以及在 集上的cpCER(%)结果
与常见模态融合方法对比
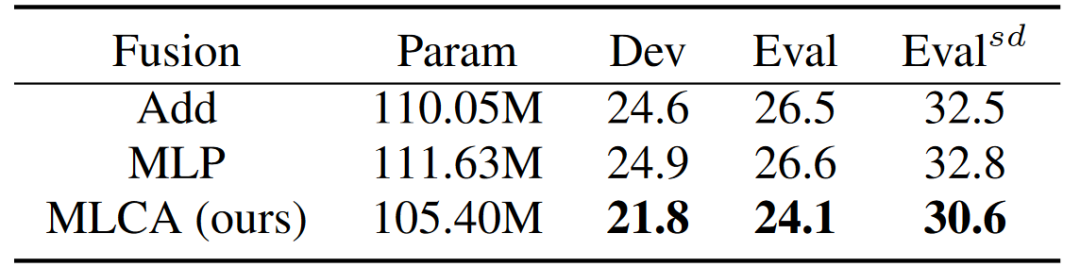
为了更好地展示多层交叉注意力融合方法的优势,我们实现了两种常见的融合方法进行比较:(1)简单地将音频和视觉编码器的输出相加以及(2)在沿特征维度连接输出后通过MLP进行融合。MLP模块包括两层线性投影,分别为2048维和256维。为了公平比较,在Add和MLP融合实验中,我们将音频和视觉编码器的E-Branchformer编码器层数分别从24增加到27和从9增加到12。表2呈现了利用不同融合策略的音视频语音识别系统的实验结果。显然,我们提出的多层交叉注意力(MLCA)融合方法优于Add和MLP,分别在Eval集上实现了高达2.4%和2.5%的相对CER改善。
表2 采用不同融合方法的视听语音识别系统效果
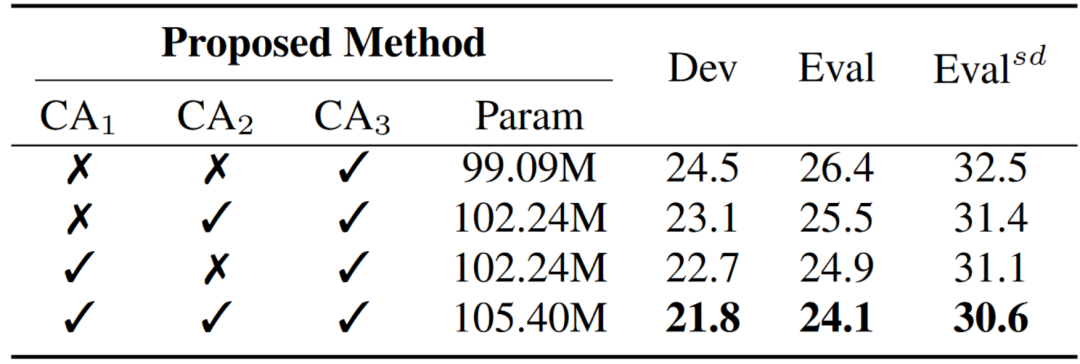
消融实验

表3 针对MLCA-AVSR中的3个交叉注意力模块的消融实验结果
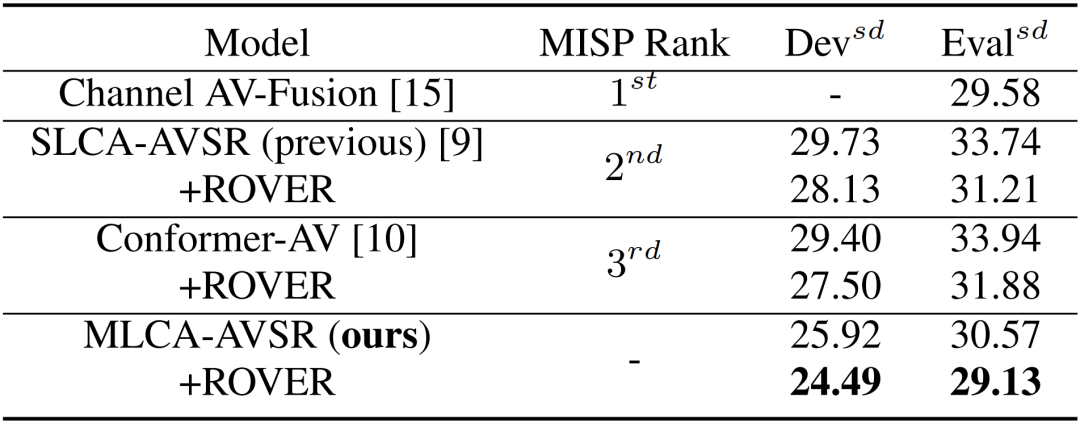
与MISP2022挑战赛Top3系统对比

表4 针对MLCA-AVSR与MISP2022挑战赛AVSR赛道Top3系统对比结果
参考文献
[1] Pingchuan Ma, Stavros Petridis, and Maja Pantic, “End-to-end audio-visual speech recognition with conformers,” in Proc. ICASSP. IEEE, 2021, pp. 7613–7617.
[2] George Sterpu, Christian Saam, and Naomi Harte, “Attentionbased audio-visual fusion for robust automatic speech recognition,” in Proc. MI. ACM, 2018, pp. 111–115.
[3] Yifei Wu, Chenda Li, Song Yang, Zhongqin Wu, and Yanmin Qian, “Audio-visual multi-Talker speech recognition in a cocktail party,” in Proc. Interspeech. ISCA, 2021, pp. 3021–3025.
[4] Ao Zhang, He Wang, Pengcheng Guo, Yihui Fu, Lei Xie, Yingying Gao, Shilei Zhang, and Junlan Feng, “VE-KWS: Visual modality enhanced end-to-end keyword spotting,” in Proc. ICASSP. IEEE, 2023, pp. 1–5.
[5] Ming Cheng, Haoxu Wang, Yechen Wang, and Ming Li, “The DKU audio-visual wake word spotting system for the 2021 MISP challenge,” in Proc. ICASSP. IEEE, 2022, pp. 92569260.
[6] Tao Li, Haodong Zhou, Jie Wang, Qingyang Hong, and Lin Li, “The XMU system for audio-visual diarization and recognition in MISP challenge 2022,” in Proc. ICASSP. IEEE, 2023, pp. 1–2.
[7] Hang Chen, Jun Du, Yusheng Dai, Chin Hui Lee, Sabato Marco Siniscalchi, Shinji Watanabe, Odette Scharenborg, Jingdong Chen, et al., “Audio-visual speech recognition in misp2021 challenge: Dataset release and deep analysis,” in Proc. Interspeech. ISCA, 2022, pp. 1766–1770.
[8] Zhe Wang, Shilong Wu, Hang Chen, Mao-Kui He, Jun Du, Chin-Hui Lee, Jingdong Chen, Shinji Watanabe, et al., “The multimodal information based speech processing (MISP) 2022 challenge: Audio-visual diarization and recognition,” in Proc. ICASSP. IEEE, 2023, pp. 1–5
[9] Pengcheng Guo, He Wang, Bingshen Mu, Ao Zhang, and Peikun Chen, “The NPU-ASLP system for audio-visual speech recognition in MISP 2022 challenge,” in Proc. ICASSP. IEEE, 2023, pp. 1–2.
[10] Tao Li, Haodong Zhou, Jie Wang, Qingyang Hong, and Lin Li, “The XMU system for audio-visual diarization and recognition in MISP challenge 2022,” in Proc. ICASSP. IEEE, 2023, pp. 1–2.
[11] Jaesong Lee and Shinji Watanabe, “Intermediate loss regularization for CTC-based speech recognition,” in Proc. ICASSP. IEEE, 2021, pp. 6224–6228.
[12] Kwangyoun Kim, Felix Wu, Yifan Peng, Jing Pan, Prashant Sridhar, Kyu J Han, and Shinji Watanabe, “E-branchformer: Branchformer with enhanced merging for speech recognition,” in Proc. SLT. IEEE, 2023, pp. 84–91.
[13] David Snyder, Guoguo Chen, and Daniel Povey, “Musan: A music, speech, and noise corpus,” arXiv preprint arXiv:1510.08484, 2015.
[14] Bowen Pang, Huan Zhao, Gaosheng Zhang, Xiaoyue Yang, et al., “Tsup speaker diarization system for conversational short-phrase speaker diarization challenge,” in Proc. ISCSLP. IEEE, 2022, pp. 502–506.
[15] Gaopeng Xu, Xianliang Wang, Sang Wang, Junfeng Yuan, Wei Guo, Wei Li, and Jie Gao, “The NIO System for audio-visual diarization and recognition in MISP challenge 2022,” in Proc. ICASSP. IEEE, 2023, pp. 1–2.
[16] Jonathan G Fiscus, “A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (ROVER),” in Proc. ASRU. IEEE, 1997, pp. 347–354.
文章来源于音频语音与语言处理研究组 ,作者王贺
这篇关于ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





