mlca专题

YOLOv8改进实战 | 引入混合局部通道注意力模块MLCA(2023轻量级)
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进

YOLOv10改进 | 注意力篇 | YOLOv10引入MLCA
1. MLCA介绍 1.1 摘要:注意力机制是计算机视觉中使用最广泛的组件之一,可以帮助神经网络强调重要元素并抑制不相关的元素。然而,绝大多数信道注意力机制只包含信道特征信息,忽略了空间特征信息,导致模型表示效果或目标检测性能较差,且空间注意力模块往往复杂且成本高昂。为了在性能和复杂度之间取得平衡,该文提出一种轻量级的混合局部信道注意力(MLCA)模块来提高目标检测网络的性能,该模块可以同
![【YOLOv10改进[注意力]】使用注意力MLCA改进C2f + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/72fdccaa605c4bb88d16bd92bde4bee4.png)
【YOLOv10改进[注意力]】使用注意力MLCA改进C2f + 含全部代码和详细修改方式 + 手撕结构图
本文将进行使用注意力MLCA改进C2f的实践,助力YOLOv10目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 MLCA 二 使用注意力MLCA改进C2f 1 整体修改 2 配置文件
![【YOLOv9改进[注意力]】在YOLOv9中使用注意力MLCA的实践 + 含全部代码和详细修改方式](https://img-blog.csdnimg.cn/direct/ae91e064b4a7452daa79bdf63f39e33f.png)
【YOLOv9改进[注意力]】在YOLOv9中使用注意力MLCA的实践 + 含全部代码和详细修改方式
本文将进行在YOLOv9中使用注意力MLCA的实践,助力YOLOv9目标检测效果的实践,文中含全部代码、详细修改方式。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 MLCA 二 在YOLOv9中使用注意力MLCA的实践 1 整体修改 2 配置文件
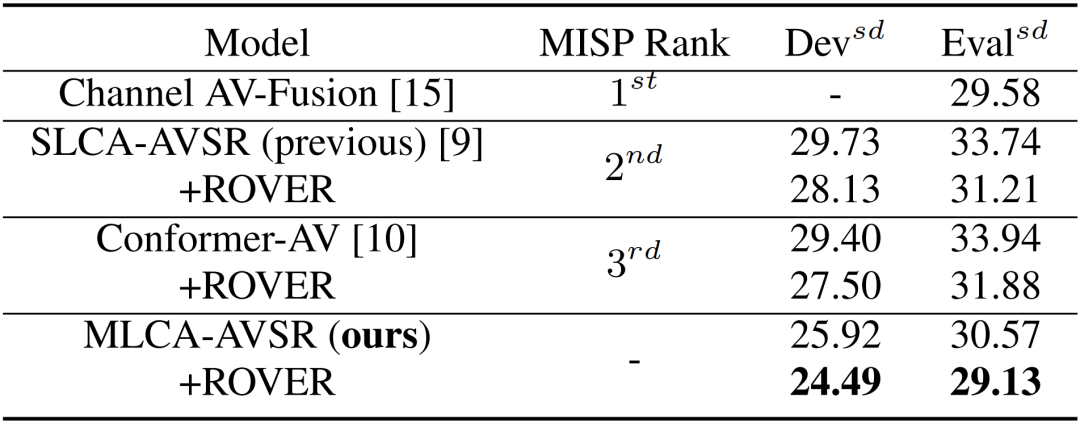
ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别
视听语音识别(Audio-visual speech recognition, AVSR)是指结合音频和视频信息对语音进行识别的技术。当前,语音识别(ASR)系统在准确性在某些场景下已经达到与人类相媲美的水平。然而在复杂声学环境或远场拾音场景,如多人会议中,ASR系统的性能可能会受到背景噪音、混响和多人说话的重叠的干扰而严重下降。基于视频的视觉语音识别(VSR)系统通常不会受到声学环境的干扰。因此

Pointnet++改进注意力机制系列:全网首发MLCA轻量级的混合本地信道注意力机制 |即插即用,实现有效涨点
简介:1.该教程提供大量的首发改进的方式,降低上手难度,多种结构改进,助力寻找创新点!2.本篇文章对Pointnet++特征提取模块进行改进,加入MLCA注意力机制,提升性能。3.专栏持续更新,紧随最新的研究内容。 目录 1.理论介绍 2.修改步骤 2.1 步骤一 2.2 步骤二 2.3