icassp2024专题
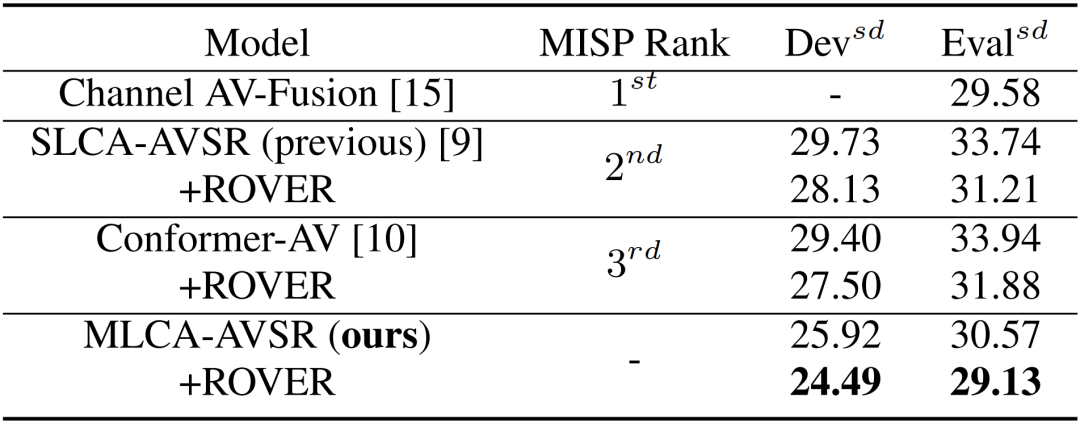
ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别
视听语音识别(Audio-visual speech recognition, AVSR)是指结合音频和视频信息对语音进行识别的技术。当前,语音识别(ASR)系统在准确性在某些场景下已经达到与人类相媲美的水平。然而在复杂声学环境或远场拾音场景,如多人会议中,ASR系统的性能可能会受到背景噪音、混响和多人说话的重叠的干扰而严重下降。基于视频的视觉语音识别(VSR)系统通常不会受到声学环境的干扰。因此