avsr专题
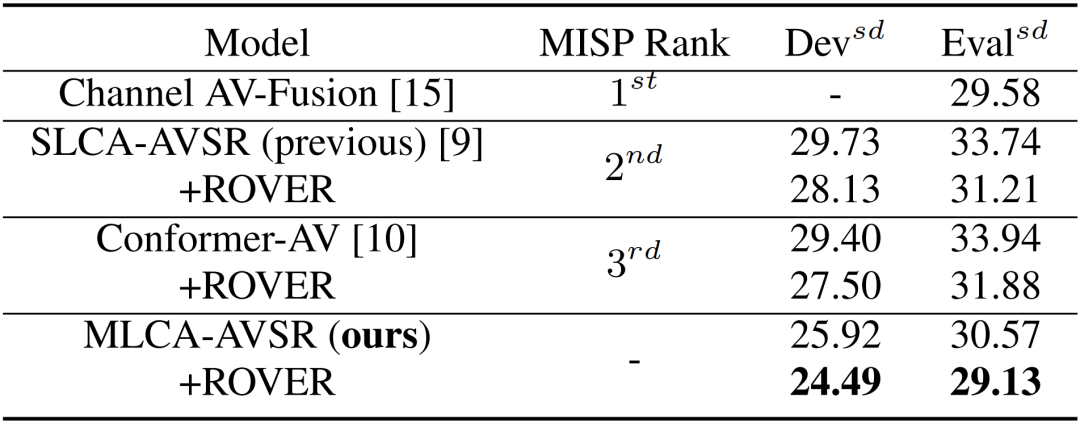
ICASSP2024 | MLCA-AVSR: 基于多层交叉注意力机制的视听语音识别
视听语音识别(Audio-visual speech recognition, AVSR)是指结合音频和视频信息对语音进行识别的技术。当前,语音识别(ASR)系统在准确性在某些场景下已经达到与人类相媲美的水平。然而在复杂声学环境或远场拾音场景,如多人会议中,ASR系统的性能可能会受到背景噪音、混响和多人说话的重叠的干扰而严重下降。基于视频的视觉语音识别(VSR)系统通常不会受到声学环境的干扰。因此

景联文科技语音数据标注:AUTO-AVSR模型和数据助力视听语音识别
ASR、VSR和AV-ASR的性能提高很大程度上归功于更大的模型和训练数据集的使用。 更大的模型具有更多的参数和更强大的表示能力,能够捕获到更多的语言特征和上下文信息,从而提高识别准确性;更大的训练集也能带来更好的性能,更多的数据可以提供更多的上下文信息,帮助模型更好地理解语音和视觉信号,减少噪声和干扰的影响。 AUTO-AVSR是一种自动标注辅助下的视听语音识别技术。它通过使
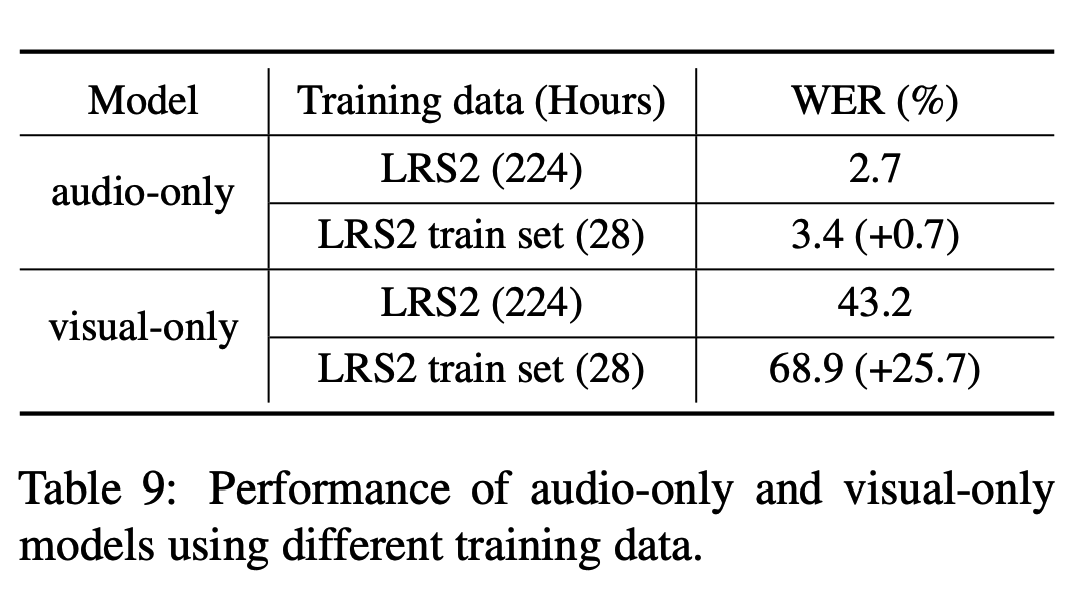
论文分享 | 利用单模态自监督学习实现多模态AVSR
本次分享上海交通大学发表在 ACL 2022 会议 的论文《Leveraging Unimodal Self-Supervised Learning for Multimodal AVSR》。该论文利用大规模单模态自监督学习构建多模态语音识别模型。 论文地址: https://aclanthology.org/2022.acl-long.308.pdf 代码仓库: https://gith