本文主要是介绍VINS-fusion 跑通Euroc、TUM、KITTI数据集,以及评估工具EVO的下载和使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
零、EVO工具获取与使用
ubuntu20.04中python版本是3.x,因此对应的pip工具会变成pip3,可以先参考如下链接查看自己系统的python和pip版本。
Ubuntu20.04安装evo(详细教程)【亲测有效】_ubantu20.04 evo_学无止境的小龟的博客-CSDN博客
再调用如下命令对evo工具进行安装
pip3 install evo --upgrade --no-binary evo
evo使用如下:
EVO工具的使用_evo rmse-CSDN博客
一、Euroc
1.1 Euroc数据集
Euroc数据集包含双目摄像头和IMU的录制数据格式,可以完成mono+imu、stereo、stereo+imu三种形式的数据播放。
首先应该获取Euroc数据集,Euroc数据集的获取网址如下:
kmavvisualinertialdatasets – ASL Datasets

在该页面,通过下载ROS bag格式数据集,使用ros进行数据读取。下载ASL数据格式,在解压后的压缩包中可以获得gt值,方便EVO工具评估使用。
1.2 VINS-fusion文件存储格式修改
需要修改的有三个地方,修改这三个地方以保证跑完vins后文件的存储格式能够被evo工具识别。
可以参考如下文件:
SLAM中evo评估工具(用自己的数据集评估vinsFusion)_vins-fusion运行自己的数据集_linzs.online的博客-CSDN博客
1.3 数据集运行
使用rosbag运行数据集命令如下,以MH_04_difficult.bag为例。
我选择的方式是双目stereo+imu的形式,命令如下:
#分别在五个终端的vins_ws空间下source后,运行:
roscore
rosrun vins vins_node /home/jetson/vins_ws/src/vins-fusion-master/config/euroc/euroc_stereo_imu_config.yaml
rosrun loop_fusion loop_fusion_node /home/jetson/vins_ws/src/vins-fusion-master/config/euroc/euroc_stereo_imu_config.yaml
roslaunch vins vins_rviz.launch
rosbag play MH_04_difficult.bag
1.4 结果保存与评估
根据euroc_stereo_imu_config.yaml文件中对结果存储路径的改写,我的结果存储在

其中,vio.csv和vio_loop.csv为vins运行后的结果。MH_04_GT.tum是根据下载下来的ASL压缩包中data.csv,使用evo工具转换来的,转换命令如下:
evo_traj euroc data.csv --save_as_tum
得到真值文件之后,可以通过evo中的一些命令工具,参考零中的
“EVO工具的使用_evo rmse-CSDN博客”
可以编写如下命令对evo工具进行调用并评估算法性能。
在/home/jetson/vins_ws/data/euroc路径下调用:
evo_ape tum vio_loop.csv /home/jetson/vins_ws/data/euroc/MH_04_GT.tum -va --plot --plot_mode xyz
evo_rpe tum vio_loop.csv /home/jetson/vins_ws/data/euroc/MH_04_GT.tum -r full -va --plot --plot_mode xyz
评估结果如下:
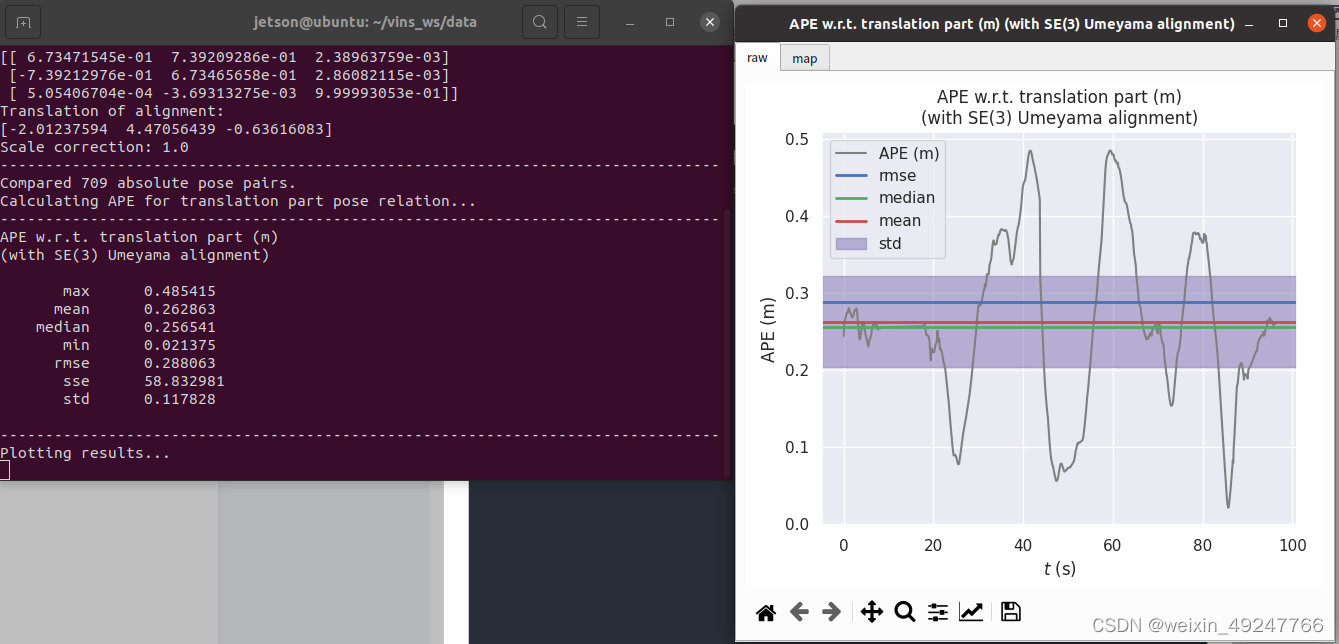
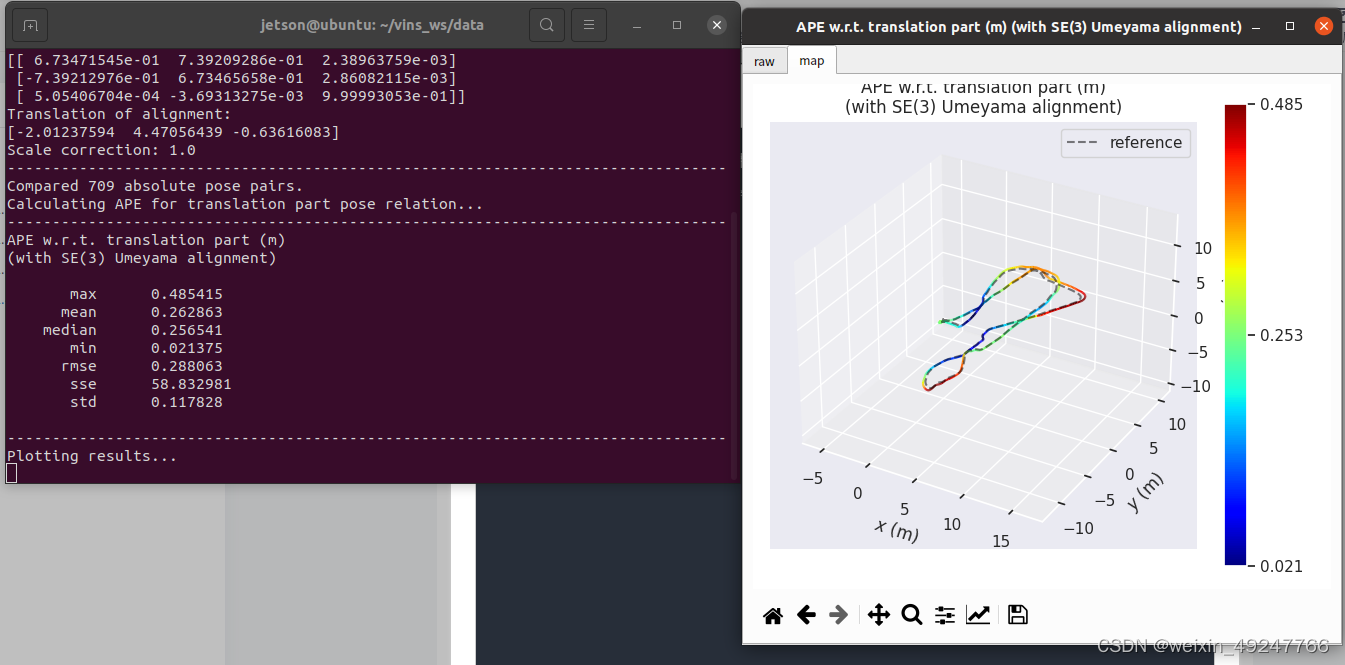
二、TUM数据集
2.1 TUM数据集获取
Computer Vision Group - Datasets - Visual-Inertial Dataset
这里以dataset-room1_512_16.bag文件为例,.bag文件是用rosbag进行播放的,而.tgz文件中包含了gt值,可以用来评估算法性能。
2.2 TUM配置文件编写
首先需要编写对应的TUM配置文件,可以参考euroc文件格式,修改对应的相机内参、相机和IMU之间的外参即可。
目前,我的tum_mono_imu.yaml和cam0.yaml文件编写如下
tum_mono_imu.yaml
这里需要注意,在本身VINS-fusion关于euroc_mono_imu_config.yaml 或者 euroc_stereo_imu_config.yaml中有一个重要参数FLOW_BACK,当该参数调整为1时将会开启光流特征点检测,提升准确性。网上大部分写好的tmu_mono_imu.yaml并没有该参数,需要自行配置。配置好的文件如下:
%YAML:1.0imu: 1
num_of_cam: 1 #common parameters
imu_topic: "/imu0"
image0_topic: "/cam0/image_raw"
output_path: "/home/jetson/vins_ws/data/tum/"cam0_calib: "cam0.yaml"
image_width: 512
image_height: 512# Extrinsic parameter between IMU and Camera.
estimate_extrinsic: 0 # 0 Have an accurate extrinsic parameters. We will trust the following imu^R_cam, imu^T_cam, don't change it.# 1 Have an initial guess about extrinsic parameters. We will optimize around your initial guess.# 2 Don't know anything about extrinsic parameters. You don't need to give R,T. We will try to calibrate it. Do some rotation movement at beginning.
#If you choose 0 or 1, you should write down the following matrix.
#Rotation from camera frame to imu frame, imu^R_cam
body_T_cam0: !!opencv-matrixrows: 4cols: 4dt: ddata: [ -9.9951465899298464e-01, 7.5842033363785165e-03, -3.0214670573904204e-02, 4.4511917113940799e-02,2.9940114644659861e-02, -3.4023430206013172e-02, -9.9897246995704592e-01, -7.3197096234105752e-02,-8.6044170750674241e-03, -9.9939225835343004e-01, 3.3779845322755464e-02 ,-4.7972907300764499e-02,0, 0, 0, 1]#Multiple thread support
multiple_thread: 1#feature traker paprameters
max_cnt: 150 # max feature number in feature tracking
min_dist: 15 # min distance between two features
freq: 10 # frequence (Hz) of publish tracking result. At least 10Hz for good estimation. If set 0, the frequence will be same as raw image
F_threshold: 1.0 # ransac threshold (pixel)
show_track: 1 # publish tracking image as topic
equalize: 1 # if image is too dark or light, trun on equalize to find enough features
fisheye: 1 # if using fisheye, trun on it. A circle mask will be loaded to remove edge noisy points
flow_back: 1 # perform forward and backward optical flow to improve feature tracking accuracy#optimization parameters
max_solver_time: 0.04 # max solver itration time (ms), to guarantee real time
max_num_iterations: 8 # max solver itrations, to guarantee real time
keyframe_parallax: 10.0 # keyframe selection threshold (pixel)#imu parameters The more accurate parameters you provide, the better performance
acc_n: 0.04 # accelerometer measurement noise standard deviation. #0.2 0.04
gyr_n: 0.004 # gyroscope measurement noise standard deviation. #0.05 0.004
acc_w: 0.0004 # accelerometer bias random work noise standard deviation. #0.02
gyr_w: 2.0e-5 # gyroscope bias random work noise standard deviation. #4.0e-5
g_norm: 9.80766 # gravity magnitude#unsynchronization parameters
estimate_td: 0 # online estimate time offset between camera and imu
td: 0.0 # initial value of time offset. unit: s. readed image clock + td = real image clock (IMU clock)#rolling shutter parameters
rolling_shutter: 0 # 0: global shutter camera, 1: rolling shutter camera
rolling_shutter_tr: 0 # unit: s. rolling shutter read out time per frame (from data sheet). #loop closure parameters
load_previous_pose_graph: 0 # load and reuse previous pose graph; load from 'pose_graph_save_path'
pose_graph_save_path: "/home/jetson/vins_ws/data/tum/" # save and load path
save_image: 0 # save image in pose graph for visualization prupose; you can close this function by setting 0
cam0.yaml
%YAML:1.0
---
model_type: KANNALA_BRANDT
camera_name: camera
image_width: 512
image_height: 512
mirror_parameters:xi: 3.6313355285286337e+00gamma1: 2.1387619122017772e+03
projection_parameters:k2: 0.0034823894022493434k3: 0.0007150348452162257k4: -0.0020532361418706202k5: 0.00020293673591811182mu: 190.97847715128717mv: 190.9733070521226u0: 254.93170605935475v0: 256.8974428996504
2.3 数据集运行
#分别在五个终端的vins_ws空间下source后,运行:
roscore
rosrun vins vins_node /home/jetson/vins_ws/src/vins-fusion-master/config/TUM/tum_mono_imu.yaml
rosrun loop_fusion loop_fusion_node /home/jetson/vins_ws/src/vins-fusion-master/config/TUM/tum_mono_imu.yaml
roslaunch vins vins_rviz.launch
rosbag play dataset-room1_512_16.bag
2.4 结果保存与评估
首先,调用如下命令将真值转换成tum格式,方便evo进行评比
evo_traj euroc gt_imu.csv --save_as_tum
evo_traj tum groundtruth.txt --save_as_tum之后,再将得到的vio_loop.csv与真值文件进行比较,得到比较结果
在/home/jetson/vins_ws/data/tum路径下调用(为了与tum其它数据集区分开,我这里选择命名为_room1)
evo_ape tum vio_loop.csv /home/jetson/vins_ws/data/tum/gt_tum_room1.tum -va --plot --plot_mode xyz
evo_rpe tum vio_loop.csv /home/jetson/vins_ws/data/tum/gt_tum_room1.tum -r full -va --plot --plot_mode xyz
多轨迹比较(根据slam方案的存储文件格式,需要自主修改名字,这里举例是真值、开回环和无回环的情况):
evo_traj tum vio.csv vio_loop.csv /home/jetson/vins_ws/data/tum/gt_tum_room1.tum -p --plot_mode=xyz评估结果如下:
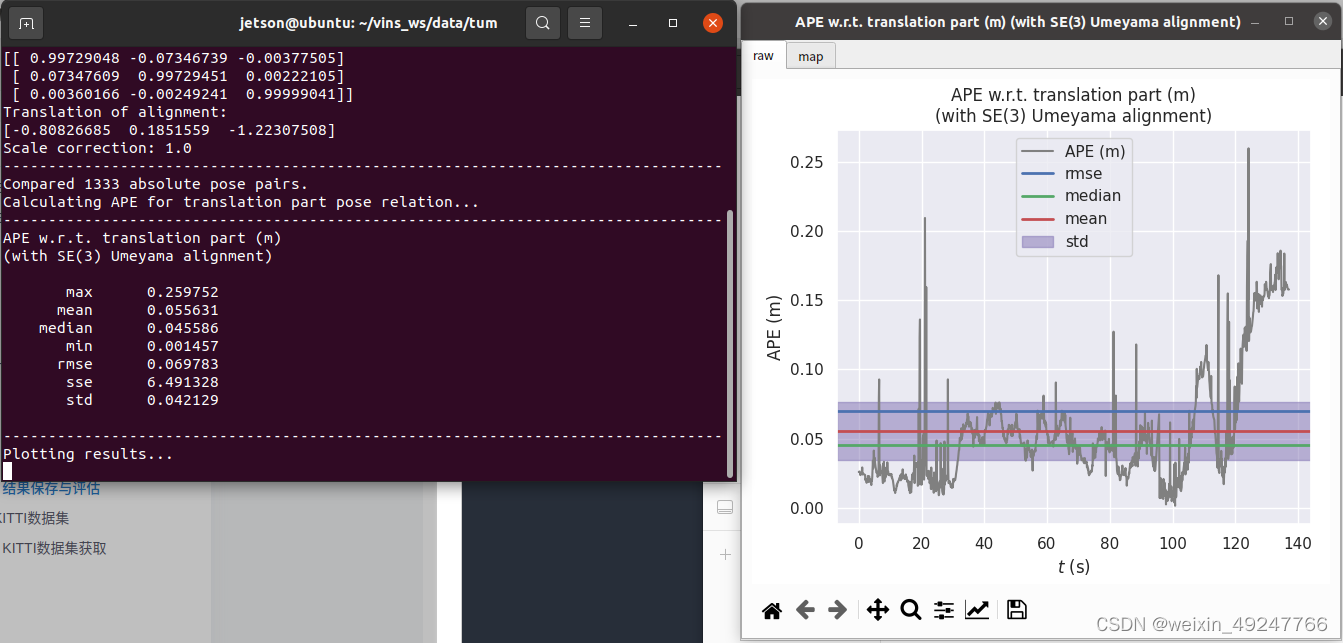

三条轨迹比较结果如下:

如果想比较多轨迹并对齐,可以调用如下命令:
evo_traj tum Ours_tumroom1.csv VINS+F_tumroom1.csv VINS+TH_tumroom1.csv MASOR1_tumroom1.csv VINS_tumroom1.csv --ref=/home/jetson/vins_ws/data/tum/gt_tum_room1.tum -p --plot_mode=xy --align --correct_scale三、KITTI数据集
KITTI数据集是纯双目的,不考虑IMU的融合。
3.1 KITTI数据集获取
下载地址为The KITTI Vision Benchmark Suite,GT值也可以在这个页面下载。
或者在下面的博客里有KITTI的链接。
VINS-Fusion : EUROC、TUM、KITTI测试成功 + 程序进程详细梳理_vins fusion kitti-CSDN博客
这篇关于VINS-fusion 跑通Euroc、TUM、KITTI数据集,以及评估工具EVO的下载和使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



