本文主要是介绍AI股票崩盘预测模型(企业建模_论文科研)ML model for stock crash prediction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对齐颗粒度,打通股票崩盘底层逻辑,形成一套组合拳,形成信用评级机制良性生态圈,重振股市信心!--中国股市新展望!By Toby!2024.1.3
综合介绍
股票崩盘,是指证券市场上由于某种原因,出现了证券大量抛出,导致证券市场价格无限度下跌,不知到什么程度才可以停止。这种大量抛出证券的现象也称为卖盘大量涌现。这种情况通常会引发投资者的恐慌性抛售,导致股票价格持续下跌。股票崩盘可能是由多种因素引起的,包括经济衰退、政治不稳定、金融危机等。股票崩盘对投资者和市场都会产生严重的影响,因此需要密切关注市场动向并采取相应的风险管理措施。
股价崩盘风险是近年来公司金融领域的明星指标。知网上以股价崩盘风险为主题的论文,已有 8 篇文章的引用量超过 1000 次,18 篇文章的引用量超过 500 次。股价崩盘风险预测模型在论文市场将会非常火热。

股票崩盘定义
崩盘通常被定义为单日或数日累计跌幅超过20%。
例如:1987崩盘时道指单日暴跌22.6%。1929年连续两个交易日的跌幅分别为12.8%和11.7%。
股票崩盘原因
引发股票崩盘的直接原因很多,有天灾和人祸,归纳如下:
1、一国的宏观经济基本面出现了严重的恶化状况,上市公司经营发生困难;
2、低成本直接融资导致“非效率”金融以及“非效率”的经济发展,极大地催生泡沫导致股价被严重高估。
3、股票市场本身的上市和交易制度存在严重缺陷,造成投机盛行,股票市场丧失投资价值和资源配置功能。
4、政治、军事、自然灾害等危机使证券市场的信心受到严重打击,证券市场出现心理恐慌而无法继续正常运转。
股市崩盘记录
1.1929年美国股市崩盘:也被称为“黑色星期四”,是美国股市历史上最严重的一次崩盘。这次崩盘标志着大萧条的开始,导致了全球范围内的经济衰退。
2.1987年全球股市崩盘:全球股市在1987年10月19日经历了一轮大规模的抛售,导致美国股市暴跌22%,这一天被称为“黑色星期一”。
3.2000年互联网泡沫破裂:在1990年代末和2000年初,互联网和科技股票价格飙升,但随后出现了泡沫破裂,导致了大规模的股票崩盘。
4.2008年金融危机:由次贷危机引发的金融危机导致了全球范围内的股票市场崩盘,包括美国的道琼斯指数和标准普尔500指数等。
5.香港嘉文奇案
近期电影《金手指》讲述了香港上市公司嘉文集团在短短几年间从默默无名到风生水起,再到没落清盘,市值蒸发超过一百亿。该案人物原型陈松青白手起家,几年内就身价百亿,无视法律坑骗港民数十亿,一度动摇香港经济。


信用评分体制预测股票崩盘
预测股票崩盘需要综合考虑多种因素,包括市场情绪、技术指标、基本面分析、宏观经济数据等。针对股票崩盘的预测模型通常会基于这些因素构建复杂的算法模型,以尝试预测市场的未来走势。这些模型可能包括机器学习算法、时间序列分析、风险管理模型等。
虽然信用评分体制本身并不是直接用于预测股票崩盘的工具,但它提供的有关公司财务状况和信用风险的信息可以作为股票崩盘预测模型中的一个重要因素。
利用人工智能,机器学习技术,我们可以预测股票崩盘概率,从而减少机构和散户的投资损失。
然而,需要强调的是,股票市场的预测是一个极其复杂和不确定的任务,没有任何模型能够完全准确地预测股票崩盘。
股市崩盘风险预测指标
股票崩盘有很多风险预测指标,例如
NCSKEW_Cmdos [NCSKEW(综合市场流通市值平均法)] ,
DUVOL_Cmdos [DUVOL(综合市场流通市值平均法)] ,
CRASH_Cmdos [CRASH(综合市场流通市值平均法)]。

我们能否建立AI量化预测模型,更精准计算股票崩盘概率?答案是肯定的。
股票崩盘预测模型案例

数据一览
该项目基于真实数据,涉及几千只上市企业股票,覆盖十年以上历史数据,有数万数据集,是非常优质数据。
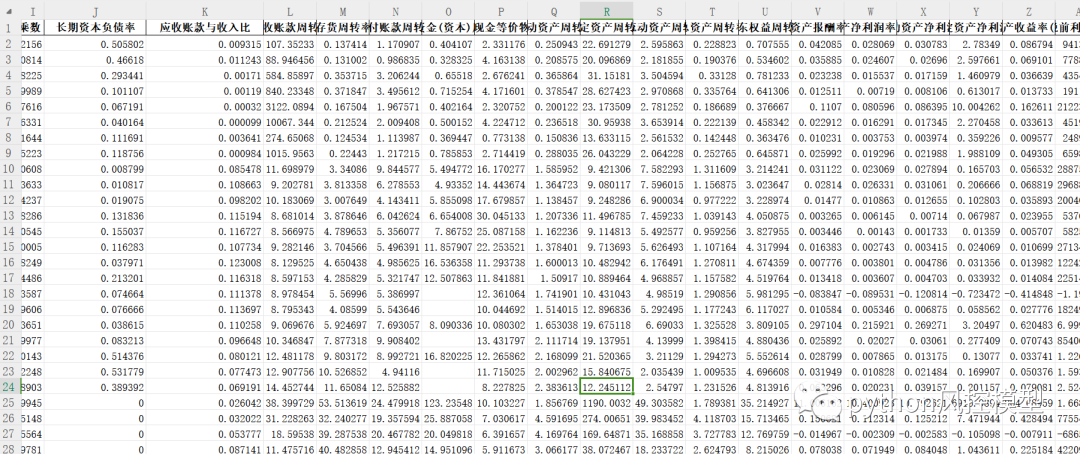
该项目数据集从多个金融数据库下载和经过多年累积,包含上百个上市企业财务数据变量,流动比率,速动比率,现金比率,资产负债率,权益乘数,长期资本负债率,应收账款与收入比,应收账款周转率,存货周转率,应付账款周转率,营运资金(资本)周转率等等。

模型性能
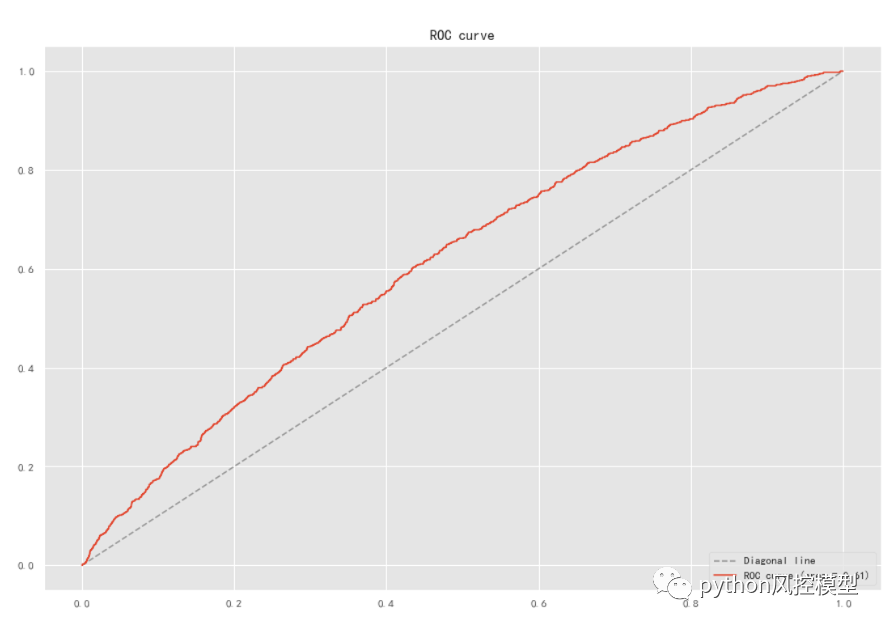
由于股票市场的预测是一个极其复杂和不确定的任务,目前市面上商业模型(股票崩盘预测模型)性能并不理想,模型AUC仅有0.6左右。
我方重庆未来之智信息技术咨询服务有限公司训练的模型(股票崩盘预测模型)经过商业算法拟合,得到AUC达到0.7以上,显著高于市场同行水平。
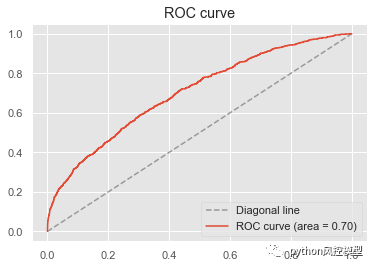
我方重庆未来之智信息技术咨询服务有限公司通过机器学习算法对数据特殊预处理,可以让模型性能大幅提升。模型性能AUC可达到0.95,非常适合证监会,证券公司,金融公司调研或研究生,博士生发布科研论文。
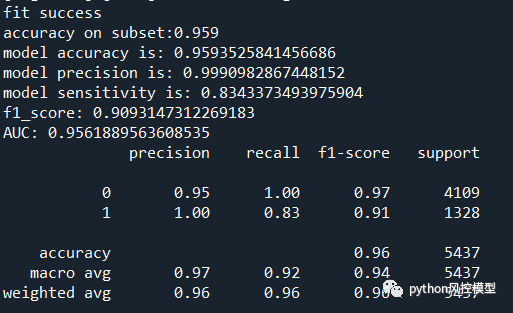
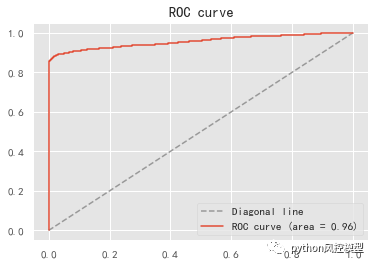
如下图AUC达到0.95以上,模型区分能力非常优秀。
信用分数
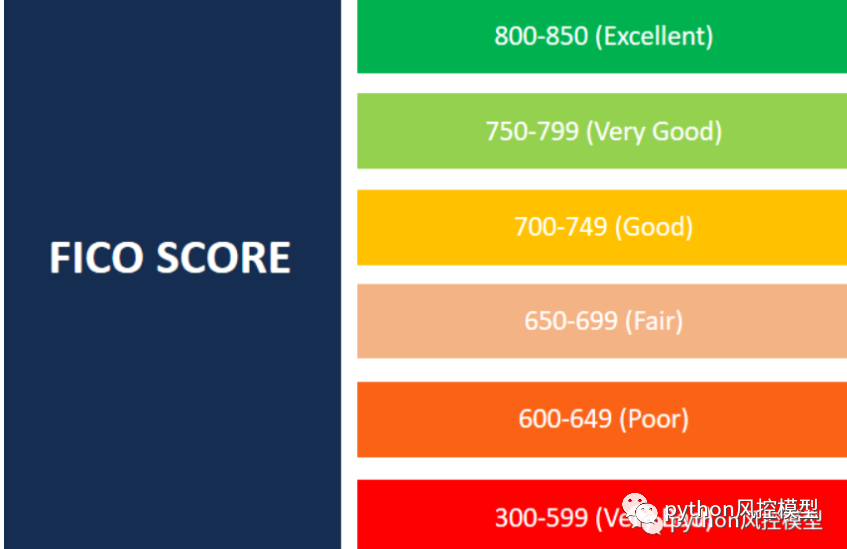
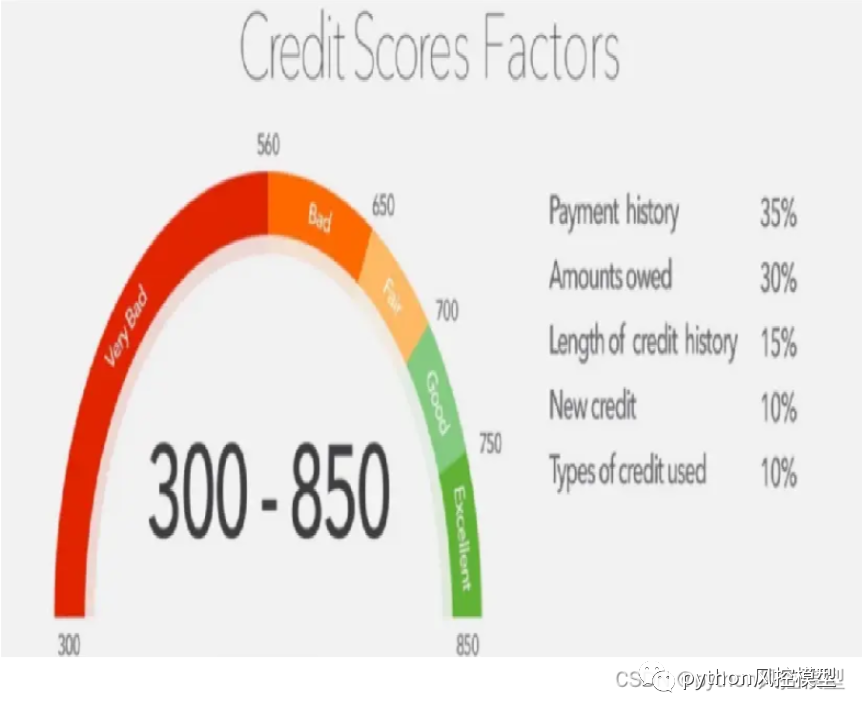
在美国,FICO 评分,通常称为信用评分,是一个三位数的数字,用于评估一个人在获得信用卡或贷方贷款时偿还信用的可能性。FICO 分数还用于帮助确定提供给个人的任何信贷的利率。FICO 分数范围从 300 到 850(从最差到最好)。每年 FICO 分数(Fair, Isaac and Company)都被各个金融机构和组织广泛使用,可以说是一个人信用好坏的很重要的评判标准。不论是贷款的成功与否还是贷款的利率与优惠,都与你的 FICO 信用分数息息相关。事实上,90% 的金融机构都会参考 FICO 分数来做决定,FICO 分数的重要性可见一斑。
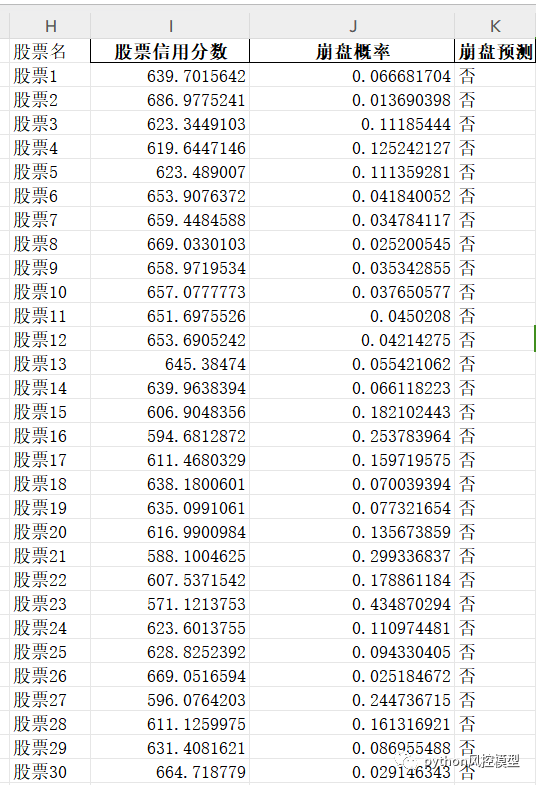
我们对股票崩盘预测模型建立好后,也可以效仿建立类似FICO的信用分数,如下图。
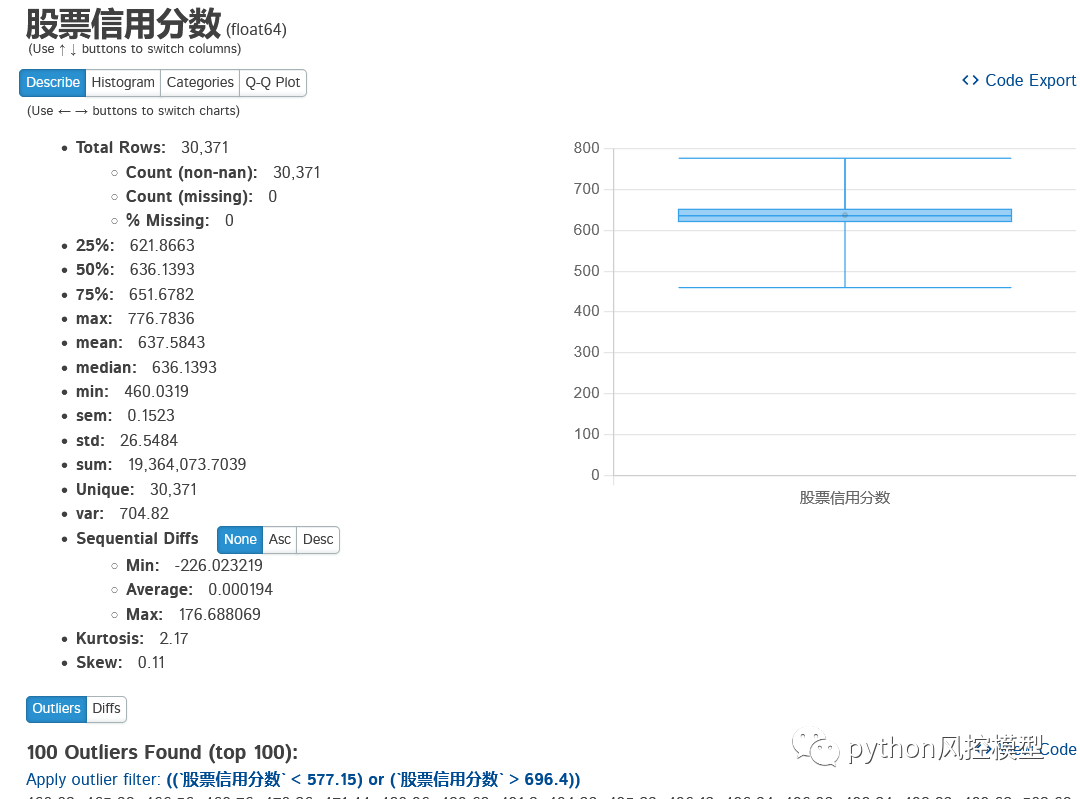
股票崩盘预测模型信用分数分布图如下,主要集中在637分左右。股市信用评分整体较好,信用分数最高股票达到776分,最低的股票信用分只有460分。
计算出股票信用分数和崩盘概率后,散户和机构就可以预测股票崩盘概率,购买信用分数高的股票,避开信用分数低,进而减少投资风险。
股票崩盘预测模型的变量可解释性
机器学习可解释性是指机器学习模型的输出结果能够以一种可理解的方式被人类理解和解释。这一点对于许多应用非常重要,尤其是在需要对模型的决策进行解释和理解的场景下,比如医疗诊断、金融风险评估、司法决策等领域。
机器学习模型的可解释性有助于增强信任:当人们能够理解模型是如何做出预测或决策的,他们更有可能对模型的结果产生信任。
机器学习模型的可解释性主要通过特征重要性分析和可视化技术实现。
特征重要性分析:通过分析模型中各个特征对最终预测结果的影响程度,来解释模型的决策。可视化技术:通过图表、图像等可视化手段来呈现模型的工作原理和决策过程。
下图是对上市股票财务变量重要性排序,找出对股票崩盘风险最大变量因子。其中我们发现年份,GDP和CPI这三个宏观金融指标和股票崩盘有着密切联系。
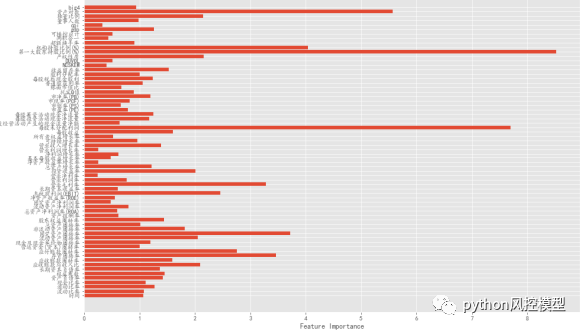
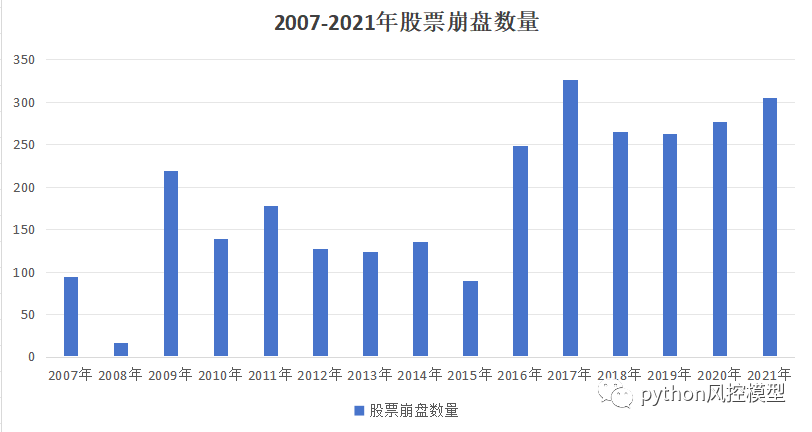
年份-被忽视因素
大家最容易忽视的就是年份,我们分类统计后发现从2007年-2021年崩盘股票数量趋势限制上升。这不是一个好的征兆,这暗示着股票震动和波动越来越大。之前郎咸平教授说过QFII入场资金越多,股市渗透能力和控场能力越强,看来这里面黑手真不少。
GDP-惊人发现
我们对变量可提供充分解释性,例如下面是GDP变量的SHAP值计算。
让我们吃惊的发现是AI认为GDP数据越大,股票崩盘概率越高;反之亦然。这简直颠覆我们认知。按照学校教科书说法,GDP越高,综合国力越强。目前地方大员升迁也和GDP有紧密关系,GDP越高,政绩工程越高,升迁概率越高。看来我们要重新思考问题。

按照温铁军教授观念,GDP只是金融资本国家的玩法,并不能反应一个国家综合国力。GDP越高代表金融资本占比越高,其他行业则萎缩,居民消费能力也将下降。金融资本占比过高将产生一个畸形经济结构,并不利于国家长远发展。
模型部署

模型可以封装为一个包,上传到服务器应用。

我方模型可以部署到web服务器,手机移动端APP,平板电脑APP,实现商业化应用,无论机构还是散户都可以使用股票崩盘预测模型。模型还具备快速批量预测多只股票功能,高效,快捷,准确。
模型商业化应用
用户通过web服务器,手机移动端APP或平板电脑APP使用股票崩盘预测软件。用户输入股票名字,软件自动输出股票信用分数,散户和机构就可以购买信用分数高的股票,避开信用分数低的股票,进而减少投资风险。
例如用户输入股票A名称,软件输出信用分为841分,则该股票崩盘概率很低,可作为购买的依据之一。

用户输入股票B名称,软件输出信用分为356分,则该股票崩盘概率很高,建议不要购买此股票。

模型除了能输出股票信用分数,还能输出该股票崩盘的概率,概率值从0-1分布,概率越接近1,崩盘的概率越高。
机器学习崩盘股票预测模型就为大家介绍到这里。如果对此项目感兴趣,例如论文,专利,银行建模,企业建模,企业调研需要,可联系我方公司,商务咨询请留言作者。我方提供公司正规发票,项目合同。
欢迎学习更多风控评分卡建模相关知识《python信用评分卡建模(附代码)》,我们提供专业评分卡模型等知识,实现自动化信用评分功能,打造金融风控信贷审批模型,降低风险。
作者Toby,文章来源公众号:python风控模型,机器学习股票崩盘预测模型
这篇关于AI股票崩盘预测模型(企业建模_论文科研)ML model for stock crash prediction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









