本文主要是介绍【论文阅读笔记】医学多模态新数据集-Large-scale Long-tailed Disease Diagnosis on Radiology Images,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是复旦大学2023.12.28开放出来的数据集和论文,感觉很宝藏,稍微将阅读过程记录一下。
Zheng Q, Zhao W, Wu C, et al. Large-scale Long-tailed Disease Diagnosis on Radiology Images[J]. arXiv preprint arXiv:2312.16151, 2023.
项目主页:https://qiaoyu-zheng.github.io/RP3D-Diag/
代码:https://github.com/qiaoyu-zheng/RP3D-Diag
数据集:https://huggingface.co/datasets/QiaoyuZheng/RP3D-DiagDS
【论文概述】
医学图像新数据集!放射图像上的大规模长尾疾病诊断。
本文的目标是研究放射图像的大规模、大词汇量疾病分类问题,该分类可以表述为多模式、多解剖学、多标签、长尾分类。主要贡献有三个方面:
- 在数据集构建方面,建立了一个学术上可访问的大规模诊断数据集,其中包含与 930 个独特的 ICD-10-CM 代码相关的 5568 种疾病,包含 39,026 例(192,675 次扫描)。
- 在模型设计上,提出了一种新颖的架构,能够处理来自各种成像模态的任意数量的输入扫描,并通过知识增强进行训练,以利用丰富的领域知识;
- 在评估方面,建立了多模态多解剖长尾诊断的新基准。 方法显示出优异的结果。 此外,最终模型作为预训练模型,可以进行微调以有利于对各种外部数据集的诊断。
【引言部分】
引言部分主要讨论了以下内容:
- 放射学技术的革命性作用:论文开头提到,X射线、CT、MRI和超声波等放射学技术极大地改变了医学领域,提供了一种非侵入性且深入的方式来诊断和管理疾病。这些技术,结合人工智能(AI),正处于一个新时代的前沿。
- 医学诊断模型的发展:目前的医学诊断模型主要分为两类:专家模型和通用医学人工智能(GMAI)模型。专家模型在识别和管理各种疾病方面已取得成功,但它们通常只针对特定的疾病类别和解剖区域,限制了它们在真实临床环境中处理多样化和复杂病例的能力。另一方面,GMAI模型旨在整合来自不同来源的数据,如各种成像方法、患者病史和最新医疗研究,以提供更全面的诊断和治疗方案。但GMAI模型的发展面临着诸如需要大量计算能力、精心策划的多模态数据集、以及处理极不平衡的数据分布和领域专业知识等挑战。
- **评估过程:**作者进行了一系列消融研究,以测试不同训练配置的有效性,例如视觉骨干网络(如ViT或ResNet)、增强实施策略,以及3D输入体积的深度。随后,他们在提出的多模态、多扫描、长尾、多标签诊断基准上评估了模型,并证明了所提出方法的优越性。此外,训练后的模型显示出强大的迁移能力。通过微调,该模型能够提升多个外部数据集的性能,无论这些数据集的图像尺寸、成像方式和成像解剖部位如何。
- 本文的目标和贡献:本文的目标是考虑放射学图像的大规模、大词汇量的疾病分类问题,这标志着从专家模型向通用模型的过渡。与现有的专家模型相比,本研究旨在开发一个计算模型,能够处理多模态、多解剖部位和多标签疾病诊断,尤其是在极不平衡的数据分布情况下。与通用模型相比,本研究提供了一个更可行和有针对性的场地,用于在学术实验室探索复杂算法,并提供了详细的错误分析机会。总体来说,本文的贡献包括三个方面:一个大规模开放数据集及其构建流程、初步的模型架构探索和一个评估基准。
【相关工作】
第2部分“相关工作”涵盖了以下主要内容:
- 疾病分类数据集:开源数据集在医学影像分析的AI发展中扮演重要角色。与自然图像不同,医学影像数据集的策划面临隐私、专业知识等方面的独特挑战。例如NIH ChestX-ray、MIMIC-CXR和CheXpert等大型数据集,它们提供了全面的注释X射线图像,促进了自动化疾病分类的研究与进展。但这些数据集存在三个关键限制:大多数是2D影像,专注于二元分类的特定疾病,且包含的疾病类别在不同粒度级别上存在变化,这对于表示学习提出了挑战。因此,构建能反映真实临床场景复杂性的数据集变得必要。
- 专家诊断模型:早期的诊断模型倾向于专门化,针对特定疾病类别。这些模型专注于特定成像模式和解剖区域。例如,基于卷积神经网络(ConvNets)的模型在医学影像分类中因其出色表现而被广泛使用,而近年来视觉变换器(ViT)在医学成像社区引起了极大兴趣,催生了许多创新方法。
- 通用医学基础模型:另一类工作是通用医学基础模型,它们旨在创建能够处理多种医学任务的多功能、综合的AI系统,通过利用大规模多样化的医学数据。这些模型代表了医学AI的一个范式转变。例如,MedPaLM M和RadFM等模型在多个医学基准测试中取得了与或超过最先进性能的成果,展示了通用基础模型在疾病诊断和其他方面的潜力。但这些模型的开发需要大量的计算能力,这在学术实验室中探索复杂算法时往往不切实际。
- 长尾分类策略:医学影像诊断天然面临长尾挑战,因为常见疾病的发生率通常远高于罕见疾病。解决不平衡问题的直接方法包括训练过程中的重采样,例如对尾部类别进行过度采样或对头部类别进行欠采样。然而,这种方法往往导致尾部类别的过拟合,头部类别的训练不足。损失权重重新分配是另一种广泛用于解决长尾分布问题的方法,如焦点损失(Focal Loss),通过为易学习的数据分配较低的权重,从而优先考虑挑战性或易错分类的实例。这些方法主要在类别数量有限的相对较小的数据集上探索。本文旨在开启大规模长尾多扫描医学疾病分类问题的研究。
【数据集构建】
本文的第3部分“数据集构建”详细介绍了RP3D-DiagDS数据集的创建过程。主要内容包括:
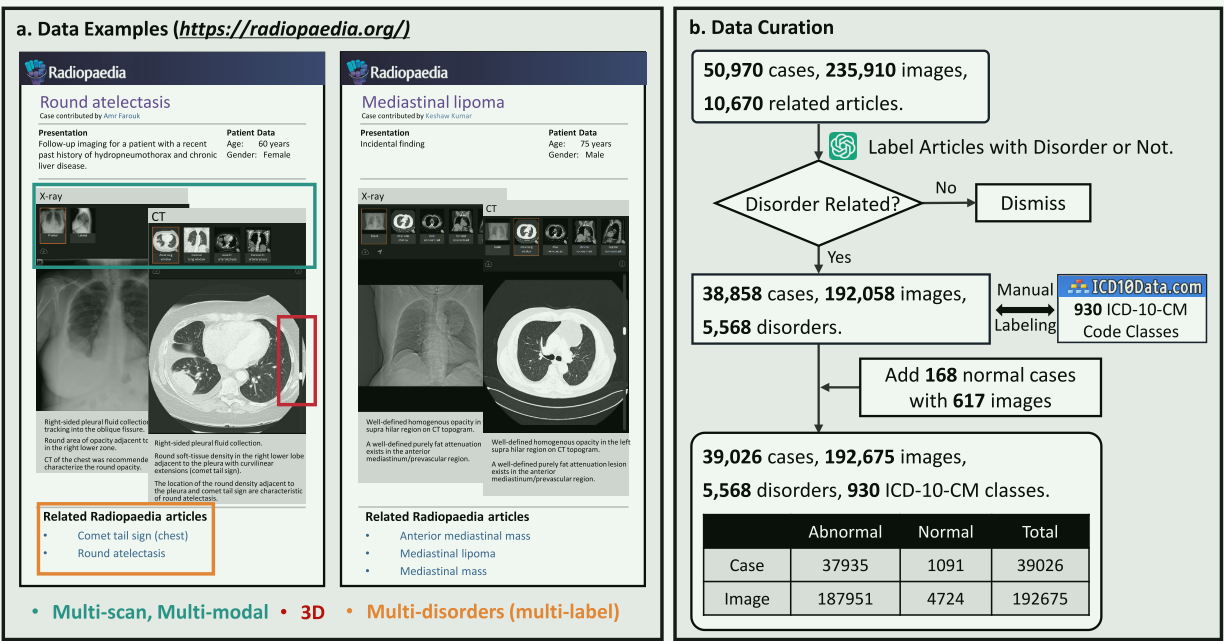
-
数据集来源:该数据集的案例主要来自Radiopaedia网站,一个不断发展的、经过同行评审的放射学教育资源网站。该网站允许临床医生上传3D体积数据,更好地反映真实临床场景。此外,所有隐私问题已由上传时的临床医生解决。
-
数据集特点:RP3D-DiagDS数据集包含39,026个病例和192,675张图像,覆盖9种不同的成像方式和7个人体解剖区域。每个病例可能包含多个扫描的图像。数据涵盖了5568种不同的疾病,被手动映射到了930个ICD-10-CM代码。
-
数据收集:数据收集过程涉及三个主要组成部分:患者数据、放射学图像和相关文章。这些信息都从Radiopaedia网站的每个病例页面收集。其中,“文章”链接到与对应疾病相关的文章,并被视为诊断标签。
-
文章筛选:使用GPT-4自动筛选文章列表,排除那些与疾病无关的文章。使用了两种不同的查询提示,只有在两种提示下都得到一致肯定结果的文章名称才被标记为疾病。筛选过程的准确性通过人工抽样进行质量控制。最终,5568个疾病类别被筛选出来。

-
映射至ICD-10-CM:疾病类别被映射到国际公认的ICD-10-CM(美国医疗保健系统用于编码诊断的国际疾病分类第十次修订临床修改版)代码。由十名医学博士生手动完成映射,经过十年临床医生的交叉检查。这一过程将各种疾病统一到ICD-10-CM代码树的第一层级,共930个类别。
-
添加正常病例:除了Radiopaedia上覆盖大多数解剖区域和成像方式的正常病例外,还从MISTR收集了更多可用于研究的正常病例。这些扩展的正常病例共包括168例。
-
数据集最终规模:最终,RP3D-DiagDS包含39,026个病例,192,675张图像,标记了5568种疾病类别和930个ICD-10-CM类别。数据集将持续维护,增加病例数量。
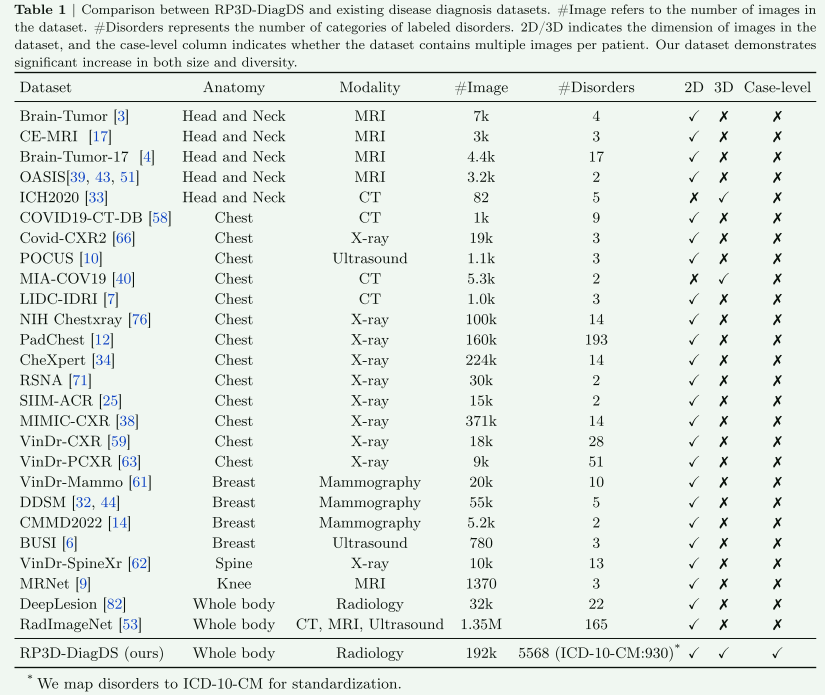
【数据集分布】
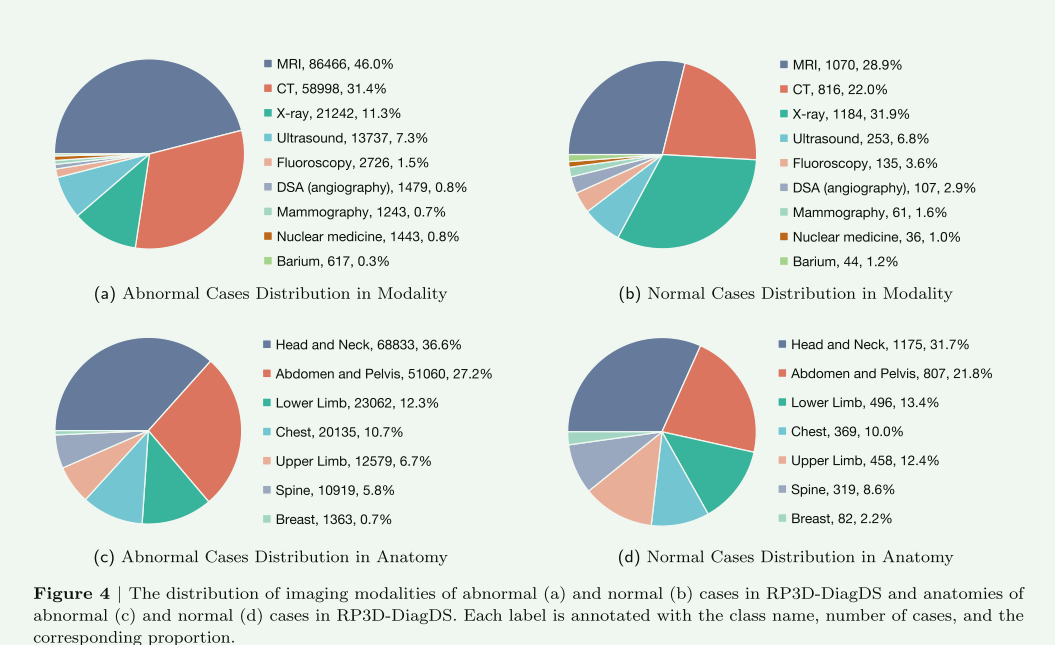
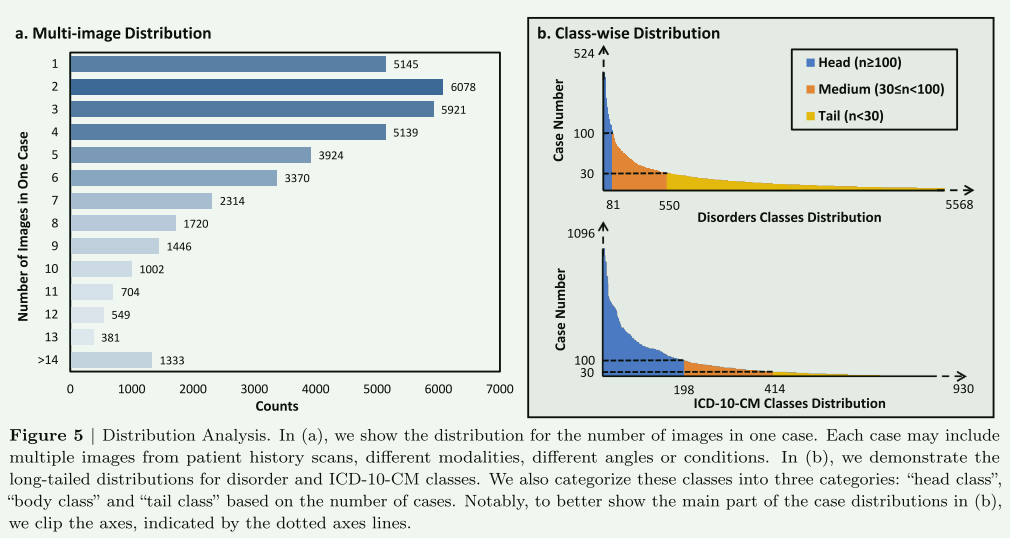
在文章的3.2节“数据集统计”中,提供了对所提出数据集的详细分析,主要从三个方面进行:模态覆盖、解剖学覆盖和疾病覆盖。数据集RP3D-DiagDS包含来自9种模态的图像,包括计算机断层扫描(CT)、磁共振成像(MRI)、X射线、超声、荧光透视、核医学、乳房摄影、DSA(血管造影)和钡灌肠。每个病例可能包含来自多种模态的图像,以确保对疾病进行精确和全面的诊断。
该数据集呈现出自然的不平衡分布,每个疾病类别的病例数从1到964不等。此外,数据集中的每个病例都包括多个多模态扫描,模态的数量从1到5不等,每个病例的图像数量在1到30之间。因此,构建了一个涵盖39026个病例(192675次扫描)、7个人体解剖区域和9种不同模态的长尾多扫描医学疾病分类数据集,覆盖了930个ICD-10-CM代码和5568种疾病,称为Radiopaedia3D诊断数据集(RP3D-DiagDS)。该数据集将发布所有数据,包括相应的疾病、ICD-10-CM代码和详细定义。在架构设计上,展示了一个支持来自各种模态的2D和3D输入的新模型,以及用于全面诊断的基于变压器的融合模块。
【模型方法】
在文章的第4部分“方法”中,作者们初步探讨了用于放射学上大规模长尾疾病诊断的计算架构。这部分首先在4.1节中定义了病例级多标签分类问题,然后在4.2节中详细阐述了架构设计,最后在后续部分讨论了知识增强训练策略。
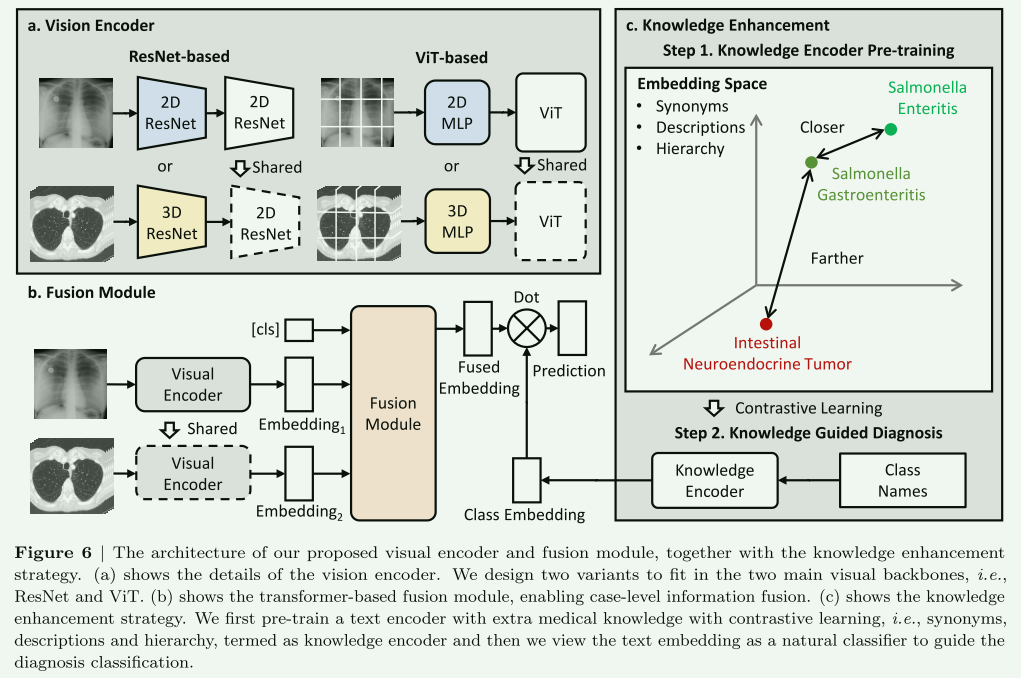
具体来说,作者们提出了一种视觉编码器和融合模块的架构,以及一种知识增强策略。这种架构设计了两种变体,以适应两种主要的视觉后端架构,即ResNet和ViT(视觉变换器)。此外,还展示了基于变换器的融合模块,该模块能够实现病例级别的信息融合。在知识增强策略方面,作者首先使用对比学习对文本编码器进行预训练,以增加额外的医学知识,比如同义词、描述和层次结构,这被称为知识编码器。然后,将文本嵌入视为一种自然的分类器,以指导诊断分类。
-
结构
文章第4.2节“架构”中介绍了一种用于多类别、多扫描诊断问题的模型架构。该架构包含两个关键组件:
- 视觉编码器 (Visual Encoder): 该部分的目标是处理2D或3D输入扫描。在视觉编码器中,考虑了两种流行的变体,即ResNet和ViT。这些编码器负责将输入的医学影像转换为可以被模型进一步处理的特征表示。
- 基于Transformer的融合模块 (Transformer-based Fusion Module): 为了进行病例级诊断,提出了一个可以聚合多个扫描信息的可训练模块。首先,初始化了一组可学习的模态嵌入,分别代表不同的成像模态。针对每种特定的视觉嵌入(来自某一成像模态),首先加入相应的模态嵌入,以指示其来源于哪种放射学模态。然后,将一个病例中的所有视觉嵌入输入到融合模块中,输出融合后的视觉嵌入,这通过“[cls]”标记实现。
这种架构旨在处理来自不同模态(如CT、MRI、X射线等)的2D和3D扫描,通过融合这些不同来源的数据,提高对疾病的诊断准确性。
-
知识增强训练
在第4.3节“知识增强训练”中,文章描述了一种利用医学领域丰富知识来增强长尾分类的方法。该方法的核心思想是,长尾疾病可能在根本上与头部类别疾病共享某些症状或放射学病理,这些信息可以通过文本格式编码。具体来说,作者首先使用医学知识预训练文本编码器,称为知识编码器。
为了构建这个知识编码器,作者们利用了多个额外的知识库,包括Radiopaedia、ICD10-CM和UMLS。对于每个疾病术语,他们收集了从Radiopaedia文章中的定义和放射学特征,以及从ICD10-CM和UMLS中的同义词、临床信息和层次结构。这种训练考虑了以下几点:
- 同义词:如果两个术语被确定为类似的同义词,预期它们在文本嵌入空间中靠近,如“沙门氏菌性肠炎”和“沙门氏菌胃肠炎”。
- 层次结构:通过考虑层次结构,使相似的疾病或疾病名称在嵌入空间中投影到相似的嵌入,例如“肺病”在嵌入空间中比“脑病”更接近“肺炎”。
在训练过程中,将与目标医学文本相关的术语和描述视为正例,并用文本编码器进行编码。然后,使用对比损失优化方法来进一步微调文本编码器,结果产生了知识编码器。最终,这些文本嵌入被用于指导视觉编码器的训练。通过这种方式,知识增强训练策略旨在利用医学领域的丰富知识来提高对长尾疾病的分类和诊断能力。
【实验】
第5节“实验”中,文章介绍了使用RP3D-DiagDS数据集进行的一系列实验和评估。这部分首先建立了用于病例级多模态、多扫描、长尾疾病/疾患诊断的基准。接着,将RP3D-DiagDS作为一个大规模数据集用于预训练,并评估其转移到各种现有数据集的能力。
- 长尾数据分布
在实验中,将问题视为在长尾分布下的多标签分类任务。数据集被随机分为训练(训练和验证)和测试集,比例为(7:1):2。作者在研究中使用了详细的训练和评估协议概述。
实验结果显示,添加融合模块可以显著改善在疾病和ICD-10-CM水平上的头部、中部和尾部类别的结果,显示出病例级信息融合在诊断任务中的关键作用。这些结果与预期相符。在临床实践中,通常单一模态的检查对于诊断是不够的。一个彻底和细致的诊断过程通常涉及对所有测试结果的综合审查,每项测试根据其与其他测试结果的对应关系被不同地加权。作者的融合模型巧妙地模拟了这种全面的方法,证明了它在模拟临床诊断的细微过程中的有效性。
最终,实验结果使用了经典的二元交叉熵(BCE)损失作为最终训练目标。这些实验结果在表格中详细报告,分别针对头部、中部和尾部类别集进行了报告。
-
迁移学习
第5.2节“对外部数据集的迁移学习”讨论了将最终模型应用于其他外部数据集的过程,展示了模型在图像分布变化和标签空间变化上的迁移能力。在这部分中,作者首先介绍了所使用的外部数据集,这些数据集涵盖了各种医学成像模态和解剖结构。然后,他们详细描述了微调设置。
在外部数据集的选择上,作者遵循了以下原则:希望在外部评估中涵盖大多数放射学模态。例如,他们使用了MosMedData,这是一个包含1110张图像的3D胸部CT数据集,用于5级COVID-19分级。该数据集遵循官方的划分,随机划分为888/222的训练和测试集,并在其上复现了最新的方法。
在微调诊断方面,最终模型可以作为预训练模型,然后在每个下游任务上进行微调,以改善最终性能,展示了数据集的优势。具体来说,对于只有单图像输入的数据集,简单采用预训练的视觉编码器模块,即丢弃融合模块。而对于多图像输入的数据集,将会使用所有图像。在两种情况下,最终的分类层都将从头开始训练。除了使用所有可用的外部训练数据外,作者还考虑使用1%、10%、30%的数据进行小样本学习。
【实验结果】
第6节“结果”中,文章详细介绍了实验结果和评估。以下是该部分的关键内容:
- 消融研究:为了确定最佳的架构和超参数,作者进行了一系列消融研究。这些研究包括融合策略、视觉编码器架构、3D扫描深度和数据增强等方面的探索。通过这些研究,作者旨在优化模型的结构和参数配置,以实现更好的疾病分类性能。
- ICD-10-CM和疾病分类结果:实验结果专注于ICD-10-CM分类和疾病分类。在ICD-10-CM分类中,作者报告了针对头部、中部和尾部类别的不同分数,包括随机挑选、最大池化和平均池化等不同模式的性能指标,如AUC(曲线下面积)、AP(平均精确度)和F1分数。这些结果表明了模型在不同类别的疾病识别方面的效果。
- 在Rad3D-DiagDS上的评估:作者在整个Rad3D-DiagDS训练集上训练模型,并在测试集上进行评估。实验在疾病和ICD-10-CM类别两个层面上进行。为了展示融合模块的有效性,作者从没有融合模块或知识增强的基线开始,然后逐步添加这些组件以提高模型性能。这一部分的结果证实了融合模块在改进诊断性能方面的重要性。
- 基于 ResNet 的模型采用增强策略并将 3D 扫描深度统一为 32 是最适合长尾病例级多模态诊断任务的设置,该任务将用于整个数据集的训练在以下部分中。
【局限性】
尽管提出的数据集和架构非常有效,但仍然存在一些改进:首先,在模型设计上,在融合步骤中,可以使用更多图像标记来表示扫描而不是合并的单个向量。后者可能会导致融合过程中图像信息过多丢失。可以进一步增加模型大小以研究模型容量的影响;其次,应该探索新的损失函数来解决这种大规模、长尾的疾病分类任务。第三,在ICD-10-CM的无序映射过程中,注释器被标记在类名称级别,即仅提供无序名称,导致一些不明确的类无法找到严格对应的ICD-10-CM代码。尽管在共享数据文件中标记了此类,但如果提供更多案例级别的信息,映射可能会更准确。
这篇关于【论文阅读笔记】医学多模态新数据集-Large-scale Long-tailed Disease Diagnosis on Radiology Images的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





