本文主要是介绍科研上新 | 第6期:优化LLM数学推理;深度学习建模基因表达调控;基于深度学习的近实时海洋碳汇估算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
本期内容速览
01. CoT-Influx:突破少样本学习极限,提升LLM数学推理能力
02. CREaTor:通过自注意力机制建模细胞特异的基因表达调控
03. CMO-NRT:近实时监测全球海洋碳汇
CoT-Influx:突破少样本学习极限,提升LLM数学推理能力

论文链接:https://arxiv.org/abs/2312.08901
项目链接(将于近日上线):https://github.com/microsoft/CoT-Influx
大语言模型(LLMs)在各种任务中都展现出了卓越的能力,然而,对于推理任务,尤其是数学推理,提升 LLMs 性能仍然是一个挑战。尽管微调和思维链(CoT)有效提升了 LLMs 的数学推理,但作为与其相辅相成的方法——少样本学习在提升推理能力的边界尚未充分验证。
受人类推理过程启发,如果 LLMs 在解答数学问题前见过更多的解题思路示例(如与问题属于同一类型的 CoT 样本),那么将有望激发其推理能力以生成正确解决方案。而新问题也随之而来:通过输入更多的样本,LLMs 在数学推理方面的性能提升上限是多少?
微软亚洲研究院的研究员们观察发现:1. 增加 CoT 样本可提升 LLMs 推理能力,但受 LLMs 上下文窗口限制存在上界。2. CoT 样本选择至关重要,随机添加更多样本无法提升推理能力。3. CoT 样本存在冗余,通过对 token 进行剪枝可有效节省上下文窗口空间。
基于上述发现,研究员们提出了 CoT-Influx,专注于剪枝冗余的 CoT 样本和 token,为更具信息性的上下文腾出 token 空间, 以拓展少样本学习的极限。作为即插即用的插件,CoT-Influx 旨在适用于各种基础和微调的 LLMs, 通过输入尽可能多的高质量、不含冗余 token 的思维链样本,可显著提高各类 LLMs 解决数学问题的能力。
具体来说, 研究员们设计了一个轻量级的两阶段剪枝模块:(1) 第一阶段 shot pruner 从大量输入样本中选择关键 CoT 样本,(2)第二阶段对于第一阶段中选择的 CoT 样本中的冗余 token 进行剪枝。为了有效训练剪枝模块,研究员们首先设计了一个专用于数学推理的奖励函数,同时考虑剪枝后的少样本 token 总数及其对于 LLMs 数学推理的有效性。其次,研究员们利用 GPT-4 构建了一个高质量的 CoT 样本数据集 MRD3,并利用强化学习来优化该奖励函数。

图1:(上)CoT-Influx 算法; (下)CoT-Influx 进行少样本和 token 剪枝示例
实验结果表明,CoT-Influx 在多个 LLMs 和不同数学数据集上均显著提升推理能力,明显优于各种基于 prompting 的方法。例如,在 GSM8K 数据集上,通过剪枝长度是 LLaMA2 上下文窗口两倍的大量样本,CoT-Influx 带来了4.55%的绝对准确率提升。LLaMA2-70B 在 CoT-Influx 的增强下,在 GSM8K 上表现优越,超越了更大的 LLMs (PaLM 540B、Minerva 540B 等),比 GPT-3.5 高出2.5%个绝对准确率。未来,研究团队将进一步探索 CoT-Influx 对于指令微调大模型(如 WizardMath)和 GPT-4 的性能提升。
CREaTor:通过自注意力机制建模细胞特异的基因表达调控

论文链接:https://genomebiology.biomedcentral.com/articles/10.1186/s13059-023-03103-8
项目链接:https://github.com/DLS5-Omics/CREaTor
通过基因表达调控机制,具有相同基因组的细胞可以产出不同数量的基因产物(RNA 或蛋白质),并呈现不同的转录组与蛋白组状态。因此,基因调控与随之产生的细胞特异基因表达是生物体应对环境变化、执行生理功能、进行生长发育等生命活动的关键。构建不同细胞类型的基因调控网络,能够帮助人们理解细胞行为,改变细胞状态,推动生物工程与治疗工程的发展。
然而,由于基因调控的层级性、动态性与细胞特异性,通过实验方法系统性观测基因表达规律面临许多挑战。机制复杂与数据缺失的矛盾加剧了通过计算方法建模基因调控程序的难度,使得计算方法的有效性与泛化性成为瓶颈。
为了更有效地建模细胞特异的基因调控网络,发现跨细胞类型的通用表达调控机制,微软研究院科学智能中心的研究员们提出了一套基于自注意力机制的深度学习模型 CREaTor(Cis-Regulatory Element auto Translator)。该模型将细胞特异的基因表达作为模型预测目标,使用多层自注意力机制建模基因调控规律,从而同时解决了数据缺失与调控机制表征复杂的问题。
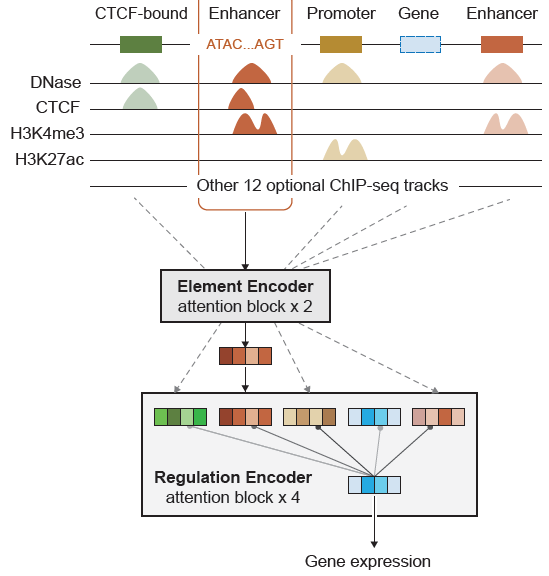
图2:CREaTor 模型框架
CREaTor 的训练策略是利用目标基因近邻的功能基因组学特征与 DNA 功能元件预测目标基因的表达水平。由于相同目标基因会在不同细胞中表现出不同表达水平,这一策略能够迫使模型学习通用基因调控机制(网络参数),建立细胞当前调控状态(模型输入)与基因调控结果(模型输出)之间的联系。高通量测序技术的发展让功能基因组学与转录组学数据飞速积累,为模型训练提供了海量而多样的样本。
研究员们通过两组顺式基因调控(一类基于 DNA 序列相互作用的基因调控模式)预测任务验证了这套方法的可行性。实验表明,CREaTor 生成的自注意力矩阵可以有效捕捉顺式调控元件与靶基因间的相互作用关系,区分实验证实的正负样本。其预测准确度优于经典的基于元件-基因距离的预测方法与 ABC score 方法,以及两种最先进的深度学习方法 Enformer (DeepMind, 2021)和 GraphReg (2022)。同时,CREaTor 还具有优秀的泛化能力与零样本学习能力,即使在模型从未见过的细胞类型中也能展现出优越的性能。此外,研究员们发现,CREaTor的多层自注意力矩阵还能够捕获元件间相互作用,并表征更高层次的基因调控模式与基因组组织特性。
该研究展示了利用深度学习模型模拟细胞基因调控网络的可行性,并表明 CREaTor 可以作为基因调控规律研究的有力工具,用于系统性预测各类细胞(包括正常发育过程和与疾病相关的细胞)的基因调控模式。
CMO-NRT:近实时监测全球海洋碳汇

论文链接:https://arxiv.org/abs/2312.01637
海洋能够吸收大气中的二氧化碳,从而在调节气候变化中发挥至关重要的作用。及时且具有地理详细性的全球海洋-大气二氧化碳通量估计能帮助人类深入认识全球碳循环的时间变化和区域差异,对全球碳预算有重要影响。然而,以往的这类通量估计存在1-2年的延迟,无法及时监测全球海洋碳汇的最新变化。
为了解决这个问题,微软亚洲研究院的研究员们推出了一个近实时的、基于月度网格的全球海洋二氧化碳浓度和海洋-大气二氧化碳通量数据集(Carbon Monitor Ocean,简称 CMO-NRT),该数据集覆盖了2022年1月至2023年7月的数据(随着时间推移,数据的区间也在不断更新中)。研究员们通过使用卷积神经网络和半监督学习方法学习模型估计或产品与观测预测因子之间的非线性关系,将10个全球海洋生物地球化学模型和8个全球碳预算2022年数据产品的估计更新到近实时框架。
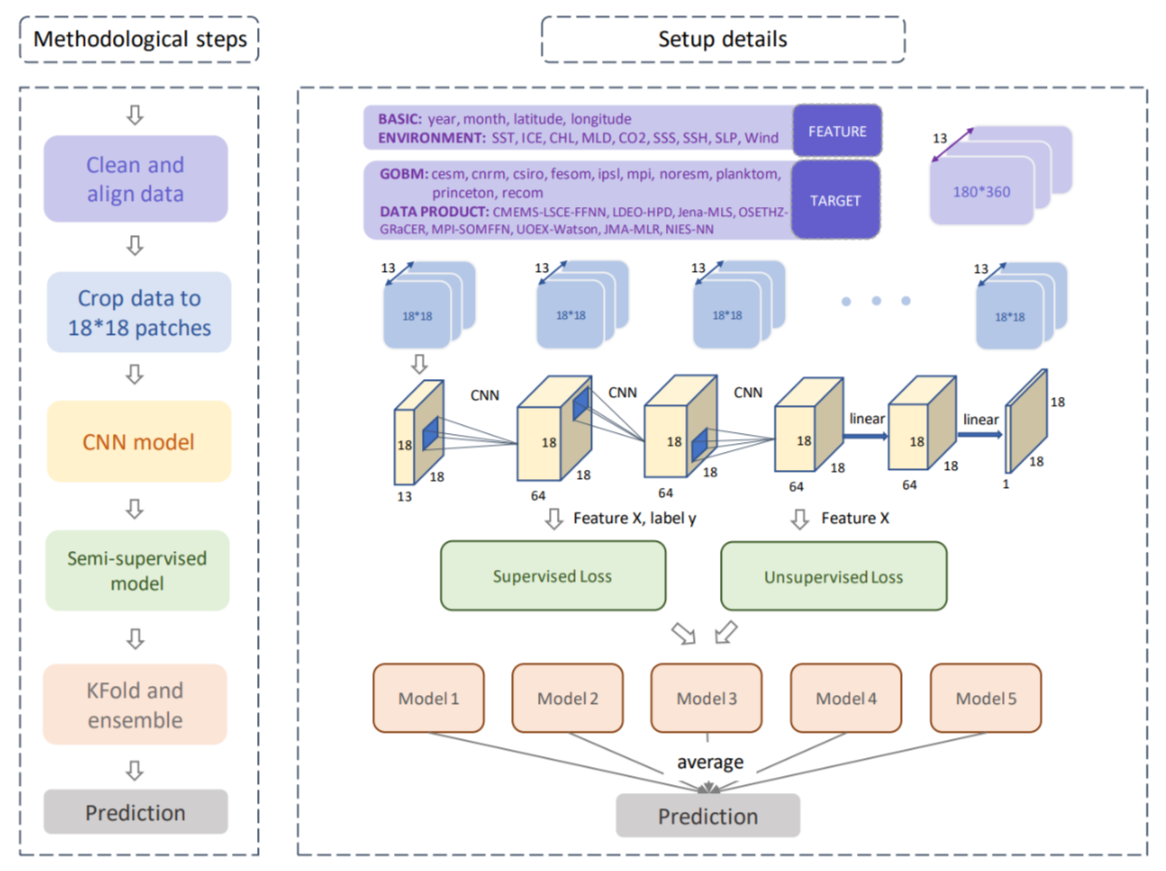
图3:CMO-NRT 方法和数据来源示意图
具体来说,研究员们提出了一种基于深度学习的技术,旨在近实时估算海洋碳汇数据。该方法将年份、月份、纬度、经度及9种环境因子数据如风速、海面温度,CO2 浓度等作为输入,预测目标则是基于全球海洋生物地球化学模型(GOBM)和海洋数据产品。所有数据均被处理成180x360的网格格式。为了在保证模型质量的同时提高计算效率,研究员们将所有环境因素切割成更小的18x18区块进行模型训练。
该研究采用了卷积神经网络(CNN)和线性模型的混合架构。经过领域知识和实验结果的分析,研究员们发现 CNN 模型能够有效地捕获预测目标与各种特征以及周边环境数据之间的关系,从而得出最优的预测结果。在模型训练过程中,研究员们使用带标签的数据计算监督损失,同时利用所有数据计算无监督损失。最终的损失函数是这两种损失的加权和,通过反向传播更新模型参数。为了进一步提高模型的稳定性和可靠性,研究员们采取了 k-fold 交叉验证的方法,对五个预测模型的结果进行平均处理,从而得出最终的预测结果。这一方法大大提高了模型的稳健性,使得预测结果更为可靠。
该数据集的目标是通过提高海洋二氧化碳浓度和海洋-大气二氧化碳通量估计的及时性,使全球海洋碳汇的评估更加准确和即时。通过捕捉模型估计或产品与观测预测因子之间的非线性关系,CMO-NRT 提供了对全球海洋-大气二氧化碳通量更即时、精确和全面的理解。这一进步提高了科学家和政策制定者监控及有效应对海洋二氧化碳吸收变化的能力,从而对气候变化管理做出贡献。
这篇关于科研上新 | 第6期:优化LLM数学推理;深度学习建模基因表达调控;基于深度学习的近实时海洋碳汇估算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




