本文主要是介绍论文学习笔记(三) SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
『写在前面』
无意间看到了《深度学习在点云分割中的应用》干货总结,原视频为SGPN原作者的技术分享,便搜来仔细研读一番~ SGPN是首个使用原始点云作为输入的实例分割网络,本篇blog为方便自己回忆要点用,建议参照原版paper使用。欢迎各位指正纰漏。
论文出处:CVPR 2018
作者机构:Weiyue Wang等,University of Southern California
原文链接:https://arxiv.org/abs/1711.08588v1
作者repo:https://github.com/laughtervv/SGPN
目录
摘要
1 介绍
2 相关工作
3 方法
3.1 SGPN网络设计
SGPN网络框架如下图所示,大致流程描述如下:
相似度矩阵计算&理解
Double-Hinge Loss
Similarity Confidence Network
Semantic Segmentation Map
3.2 推荐点组合并
4 实验
5 结论
摘要
- SGPN通过一个单独网络去预测点组推荐并为各个推荐组分配相应标签。
- 提出深度相似矩阵表征特征空间中每对点之间的相似性,从而帮助产生点分组建议。
- SGPN是首个用在点云数据上的3D实例分割网络。
1 介绍
- 受常见2D场景理解任务启发,作者的目标是构建一种end-to-end的3D实例分割网络。
- SGPN大体框架:首先使用PointNet/PointNet++提取深层特征;然后基于度量学习的思想,引入深度相似矩阵,目的是通过学习使得相同类别的点在特征空间中距离更近。
- SGPN有3个输出分支:
- 相似度矩阵(similarity matrix):用于产生点组推荐,点组推荐其实就是2D分割生成的每个instance的mask
- 置信度映射图(cofidence map):用于对产生的点组推荐进行剪枝,因为相似度矩阵的维度是与点集大小规模相当的
- 语义分割映射(semantic segmentation map):用于预测类别标签
2 相关工作
- 2D目标检测与实例分割方面:
- R-CNN/Faster R-CNN
- YOLO v1-v3
- DeepMask
- Mask R-CNN
- 3D深度学习方面:
- 3D CNN
- Octree-based CNN
- PointNet/PointNet++
- 度量学习方面:
- 本文以一种特殊的方式使用度量学习。作者视图回归两个点属于相同group的可能性,同时基于相似度矩阵还可以产生点组推荐,以适配不同数量的实例
3 方法
3.1 SGPN网络设计
SGPN网络框架如下图所示,大致流程描述如下:
- 输入原始点云:
(个人认为,Fig.2输入点云维度描述有误,按文中描述,
应该是通过多层PointNet/PointNet++后映射到的特征维度);
- 分为三个分支,每个分支会计算得到一个特征矩阵:
: Shape
: Shape
: Shape
- 因为相似度矩阵提供了
个点组推荐,但实际中可能并没有那么多instance,其中有很多点组对应的是同个instance,所以在三个分支的输出后,加了一步Group Merging(点组合并)操作
- 最后,就得到了点云实例分割的结果。训练过程中,loss计算考察三个分支loss的总和。
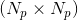
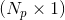
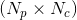

相似度矩阵计算&理解
计算方法:
- 相似度矩阵
尺寸为
,点
表示点
和点
属于同一个object instance的概率
,即两点对应特征向量差的L2范数
为什么要使用相似度矩阵?
- 对图像或体素网格数据这种space-centric结构来说,二进制mask是最自然的实例分割表示,因为它们的特征主要由网格中的高响应区域给出。
- 与之相反,点云数据可以被看做是一种shape-centric结构,它的信息通过点之间的相关性给出。
- 所以,作者认为应该更多关注在点之间相关性上,通过点之间的关系定义实例分割输出是一种更加自然的表示。
Double-Hinge Loss
在训练深度相似矩阵过程中,我们其实并不需要准确地回归矩阵中的数值,只是想通过优化,使得相似的点在特征空间中距离更近。点与点之间的关系可以归为以下三类:1. 属于同一个实例;2.属于同一个类别,但不属于同一个实例;3.属于不同类别。相似度矩阵中元素数值越大,说明其对应的两点在特征空间中距离越远(差的L2范数越大)。
计算公式如下,其中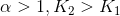

一方面,尽管对于实例分割而言,第2类和第3类点属于同一种情况(不属于同一个实例),但作者在设计Loss时将它们分开来考虑。这样做的好处是,便于手动控制不同分支准确率的增长速度和收敛速度;
另一方面,第二类点会增加实例分割的难度,sem-seg分支会错误地拉近第二类点之间在特征空间中的距离,所以作者加了一个权重因子α > 1以提高其在计算Loss中的权重。
在做Inference时,设置一个小于
的阈值
,如果
,则认为这两个点属于同一个instance。
Similarity Confidence Network
相似度置信网络(对应第二分支)表征的是一个候选点组是一个真实的目标的置信度。因为相似度置信矩阵给出的推荐很多,这一分支的主要任务其实就是剪枝。
先说ground truth groups(G)的计算方法,如果一个点P是背景点,则其对应的那一行都为0;如果它是前景点,则与其属于同个实例的点所处位置置为1,其余为0;
再说Confidence map(CM)的计算方法:对于相似度矩阵S的每一行,计算其与矩阵G的IOU值,这样就可以得到一个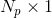
所以,在训练时,Confidence map的计算会依赖于相似度矩阵分支的计算。但是在预测时可以并行计算,只选择CM中置信度大于一定阈值的点组推荐,作为有效的点组推荐。
Semantic Segmentation Map
尺寸:
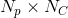
其中,对于每个元素ij,表示点i属于类别j的概率。
在计算Loss时,进行median frequency balancing,目的是为了平衡大类和小类点数上的差异。
举个例子:设有3类点,各类别点数分别为:100、50、10,则中位数为50。在计算SEM Loss时,对于第1类点,赋予50/100的权重;第2类点,赋予50/50的权重;第3类点,赋予50/10的权重。这样就能减轻Loss计算受含点数较多的类的影响。
在做Inference时,只需根据每个点对应的属于不同类别的概率,取argmax即可。
3.2 推荐点组合并
点组推荐数量因为和点集总数相当,其中存在大量的冗余和噪声,所以作者设计了推荐点组合并环节。首先,最容易想到的,如果某个推荐点组的置信度过小,或该推荐点组包含的点数过少,都应被当成一个无效的推荐。进一步,通过NMS去掉重复的推荐点组。
实际中,经过合并以后,可能会有少部分点会被指定到多个类别,这些点往往处于实例的边界。可以理解为基于 网络预测结果,这些点被分配给不同类别的概率差不多,这时候一般的处理办法也是损失最小的处理办法是随机指定其中一个类别。
4 实验
作者在S3DIS、NYUV2、ShapeNet等数据集上都进行了实验,值得一提的是,在NYUV2数据集上,作者提出了一种结合2DCNN和SGPN的思路,体现了SGPN的灵活性。

具体做法如Fig.6所示,彩色图像经过CNNs提取到的特征,与PointNets提取的特征进行拼合,而后继续进行SGPN后续的3个分支计算。其中,点云输入通过对原始数据下采样得到。
5 结论
SGPN是首个使用原始点云作为输入的实例分割网络。SGPN中的相似度矩阵随点数的平方增长,相比voxels来说节省了内存空间,但仍然无法适用于大规模点云数据上。
这篇关于论文学习笔记(三) SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






