similarity专题
![[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization](/front/images/it_default.gif)
[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization
引言 为了理解CoSENT的loss,今天来读一下Circle Loss: A Unified Perspective of Pair Similarity Optimization。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 这篇论文从对深度特征学习的成对相似度优化角度出发,旨在最大化同类之间的相似度 s p s_p s
NLP-文本匹配-2016:SiamseNet【Learning text similarity with siamese recurrent networks】
NLP-文本匹配-2016:SiamseNet【Learning text similarity with siamese recurrent networks】

论文笔记:GEO-BLEU: Similarity Measure for Geospatial Sequences
22 sigspatial 1 intro 提出了一种空间轨迹相似性度量的方法比较了两种传统相似度度量的不足 DTW 基本特征是它完全对齐序列以进行测量,而不考虑它们之间共享的局部特征这适用于完全对齐的序列,但不适用于逐步对齐没有太多意义的序列BLEU 适用于不完全对齐的序列将序列中的地点视为单词,它们的连续组合视为地理空间𝑛-gram,应用这种方法基于局部特征评估地理空间轨迹的相似性然而,

Similarity-Preserving Knowledge Distillation
Motivation 下图可以发现,语义相似的输入会产生相似的激活。这个非常好理解,这个C维的特征向量可以代表该输入的信息 因此本文根据该观察提出了一个新的蒸馏loss,即一对输入送到teacher中产生的特征向量很相似,那么送到student中产生的特征向量也应该很相似,反义不相似的话同样在student也应该不相似。 该loss被称为Similarity-preserving,这样stu

737. Sentence Similarity II
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar. For example, words1 = [“great”, “acting”,
734. Sentence Similarity
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar. For example, “great acting skills” and “f

gensim similarity计算文档相似度
向量空间模型计算文档集合相似性。[0] 将原始输入的词转换为ID,词的id表示法简单易用,但是无法预测未登记词,难以挖掘词关系;词汇鸿沟[1]:任意两个词之间是独立的,无法通过词的ID来判断词语之间的关系,无法通过词的id判断词语之间的关系[2] 使用gensim包的models,corpora,similarities,对文档进行相似度计算,结果比较其他lda、doc2vec方法稳定。 主
HDU 3718 Similarity(KM最大匹配)
HDU 3718 Similarity 题目链接 题意:给定一个标准答案字符串,然后下面每一行给一个串,要求把字符一种对应一种,要求匹配尽量多 思路:显然的KM最大匹配问题,位置对应的字符连边权值+1 代码: #include <cstdio>#include <cstring>#include <cmath>#include <algorithm>using n

SSIM(Structural Similarity),结构相似性及MATLAB实现
参考文献 Wang, Zhou; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. (2004-04-01). “Image quality assessment: from error visibility to structural similarity”. IEEE Transactions on Image Processing. 13 (4): 6
PAT 1063 Set Similarity [set]
Given two sets of integers, the similarity of the sets is defined to be Nc/Nt×100%, where Nc is the number of distinct common numbers shared by the two sets, and Nt is the total number of
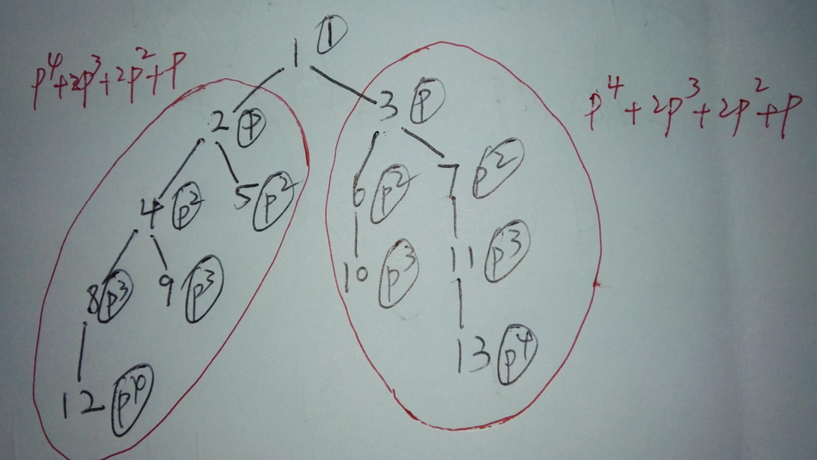
(2016 弱校联盟十一专场10.3) Similarity of Subtrees DFS + hash
题目链接 https://acm.bnu.edu.cn/v3/problem_show.php?pid=52310 problem description Define the depth of a node in a rooted tree by applying the following rules recursively: • The depth of a root node is
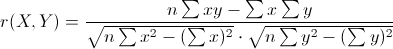
18种和“距离(distance)”、“相似度(similarity)”相关的量的小结
在计算机人工智能领域,距离(distance)、相似度(similarity)是经常出现的基本概念,它们在自然语言处理、计算机视觉等子领域有重要的应用,而这些概念又大多源于数学领域的度量(metric)、测度(measure)等概念。 这里拮取其中18种做下小结备忘,也借机熟悉markdown的数学公式语法。 常见的距离算法和相似度(相关系数)计算方法 摘要: 1.常

论文学习笔记(三) SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation
『写在前面』 无意间看到了《深度学习在点云分割中的应用》干货总结,原视频为SGPN原作者的技术分享,便搜来仔细研读一番~ SGPN是首个使用原始点云作为输入的实例分割网络,本篇blog为方便自己回忆要点用,建议参照原版paper使用。欢迎各位指正纰漏。 论文出处:CVPR 2018 作者机构:Weiyue Wang等,University of Southern California 原文链接:
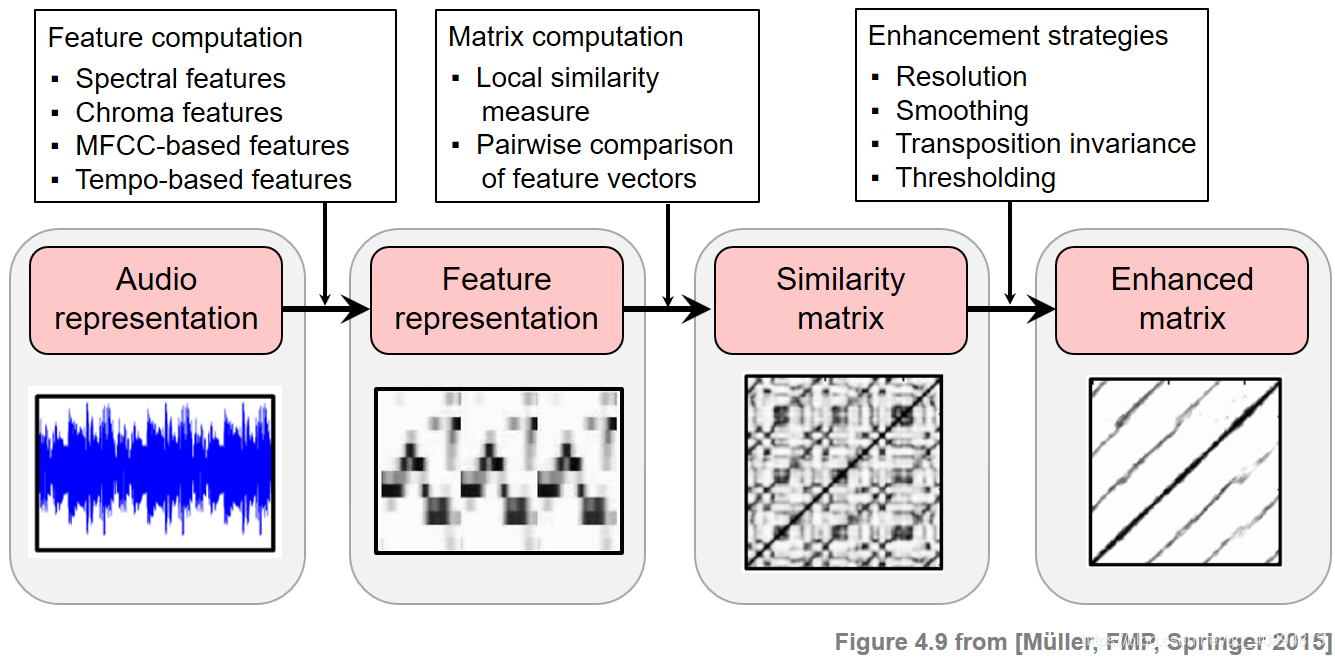
机器学习——自相似矩阵(Self-Similarity Matrix,SSM)
研究音乐结构及其相互关系的一般思路是将音乐信号转换为合适的特征序列,然后将特征序列中的每个元素与序列中的所有其他元素进行比较。这就产生了一种自相似矩阵(SSM),它不仅对音乐结构分析具有重要意义,而且对多种时间序列的分析也具有重要意义。 目录 基本定义块和路径结构基于色谱图特征的SSMSSM Based on MFCC FeaturesSSM Based on Tempogram Featu
Lintcode 1900 · Gene Similarity [Python]
一开始当然是暴力了,结果绝对是MLE了。然后可以这么思考吧,双指针,先把两个串的数字量和字母转化为两对list。然后先对比两个数字,并减去两个数字的较小的数字量,然后判断此时,两个list数字的index对应的字母一样不,一样则说明对位的字母一样,res作为一样位置和字母的统计量,增加两个数字的较小的数字。不一样,则说明对位对比每一个对的上的。然后判断,此时两个数字减去较小数字后,哪一个为0,为0

similarity network fusion for aggregating data types on a genomic scale 翻译
基因组规模上的聚合数据类型的相似性网络融合 (本文是对similarity network fusion for aggregating data types on a genomic scale 整体文章的翻译,对于后面理论公式部分可以参照该朋友的笔记) 摘要 近期的技术已经使收集不同类型的全基因组数据十分划算,结合这些数据去创建一个给定的疾病或生物过程的一个全面视图的计算方法是有必要的。
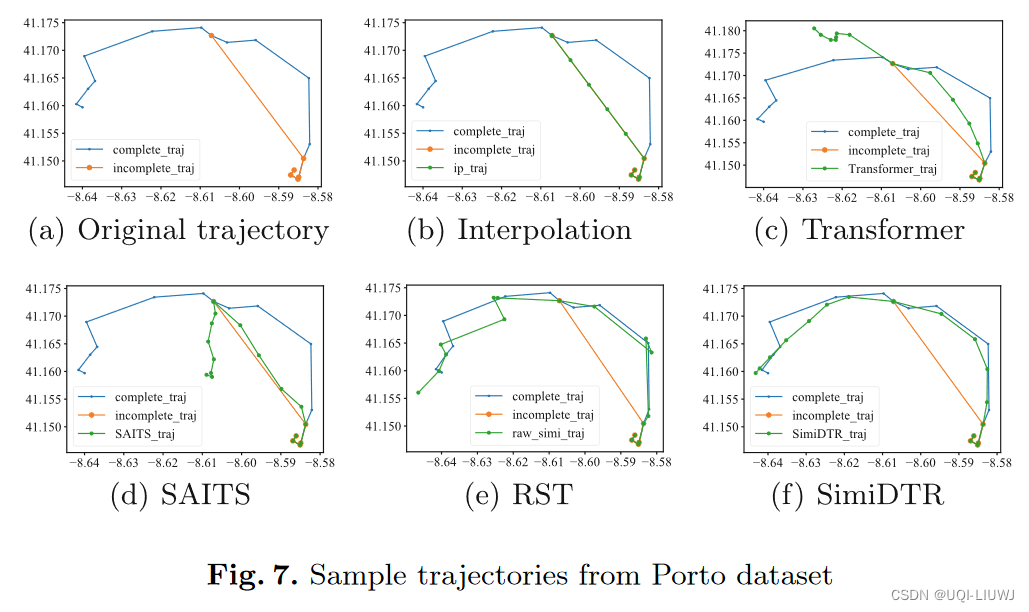
论文笔记:SimiDTR: Deep Trajectory Recovery with Enhanced Trajectory Similarity
DASFFA 2023 1 intro 1.1 背景 由于设备和环境的限制(设备故障,信号缺失),许多轨迹以低采样率记录,或者存在缺失的位置,称为不完整轨迹 恢复不完整轨迹的缺失空间-时间点并降低它们的不确定性是非常重要的一般来说,关于轨迹恢复的先前研究可以分为两个方向 第一个方向:模拟用户在不同位置之间的转换模式,以预测用户的缺失位置 本质上是一个分类任务,恢复的轨迹通常由位置或POI组成
CF Edu94Div2(1400)A String Similarity
题面 题目大意 给出字符串s,长度为2*n-1 定义两个01串(a和b)相似为:存在一个位置i,使得a[i]=b[i] 求一个01串w,使得w和s[1…n],s[2…n+1],s[n…2*n-1]这n个串相似 数据保证有解 题解 看到网上有神仙构造法,这里讲一下我的解法 考虑到两个01串不相似,当且仅当一个串是另一个串的取反,那么对于从s中截取的n个串,它们取反后的串是不能选的,剩

dot product为何能衡量similarity
https://developers.google.com/machine-learning/clustering/similarity/check-your-understanding https://math.stackexchange.com/questions/689022/how-does-the-dot-product-determine-similarity cosine

Lucene关于实现Similarity自定义排序
开场白: 作为一个人才网站的搜索功能,不但需要考滤搜索性能与效率,与需要注意用户体验,主要体现于用户对搜索结果的满意程度.大家都知道Lucene的排序中,如果单纯使用Lucene的DefaultSimilarity作为一个相似度的排序,意思是说总体上越相关的记录需要排得越前,但事与愿违.这样使用户体现也表现得相当糟糕.关键字"程序员"标题中也不能保证全部都匹配到(搜索结果来自 www.jobui

Chapter 6:Similarity-Based Methods
①Similarity Measure 相似度的衡量方法: Euclidean Distance(欧几里得距离): Mahalanobi Distance(马氏距离):,其中Q是一个半正定的协方差矩阵,是多维度数据之间的方差。马氏距离比高斯距离考虑的更全面,因为他把数据的维度和数据的大小都考虑了进来。中间的Q矩阵就是起到这个作用, Cossim Similarity:这个是余弦距离,常用于在文

DeepSim: Deep Learning Code Functional Similarity
论文阅读 DeepSim: Deep Learning Code Functional Similarity 代码的功能相似性检测 1、现存的大多数方法聚焦于代码的语法相似性,功能相似性还是一个挑战 (现存方法:都一般遵循相同的流程 首先从源代码中提取语法特征,以原始文本、tokens或者AST的形式 然后使用某个距离度量公式,如欧氏距离来检测相似的代码) 本文中提出的方法:将代码的控制流

sentence similarity vs text (multi-sentence) similarity
1. sentence similarity 1.1 方法列举 BERT Universal Sentence Encoder ELECTRA embedding 1.2 介绍 1.2.1 BERT With the advancement in language models, representation of sentences into vectors has been getti

【hash】Similarity of Subtrees
图片来源: https://blog.csdn.net/dylan_frank/article/details/78177368 【题意】: 对于每一个节点来说有多少对相同的子树。 【题解】: 利用层数进行hash,返回到对应的节点,最后标记后用等差数列来求出所有方案数。 1 #pragma GCC optimize(2) 2 #include<bits/s
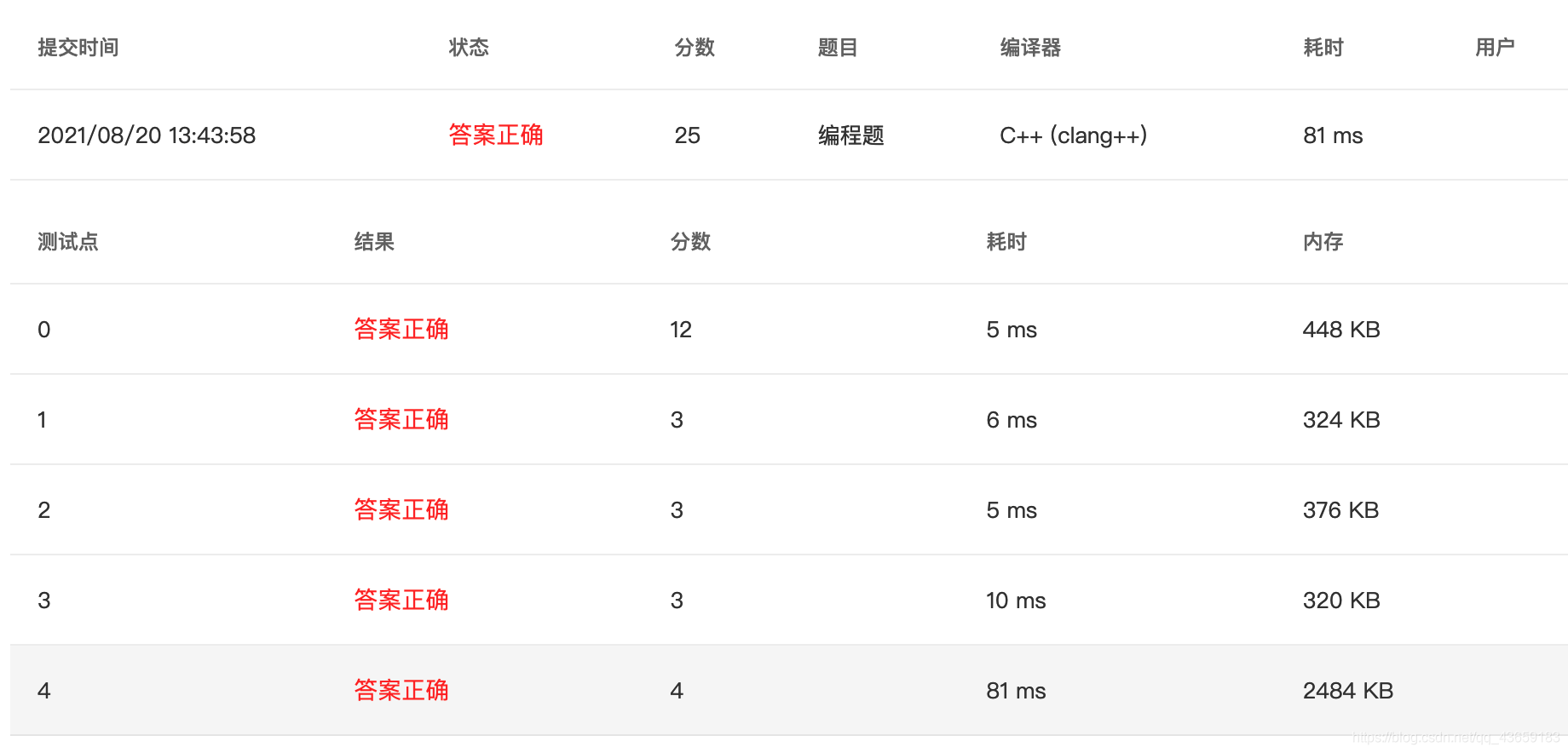
PTA甲级 1063 Set Similarity (C++)
Given two sets of integers, the similarity of the sets is defined to be N c / N t × 100 N_c/N_t ×100% Nc/Nt×100, where N c N_c Nc is the number of distinct common numbers shared by the two sets,

【论文解读】Count- and Similarity-aware R-CNN for Pedestrian Detection(基于计数和相似度感知的R-CNN用于行人检测)
论文题目:Count- and Similarity-aware R-CNN for Pedestrian Detection 论文出处:European Conference on Computer Vision(ECCV)2020 论文链接:文章下载 代码链接:代码 一、创新点 提出了计数和相似性分支网络——count-and-similarity branch(CSB)提出了计数加权检测