本文主要是介绍论文笔记:SimiDTR: Deep Trajectory Recovery with Enhanced Trajectory Similarity,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DASFFA 2023
1 intro
1.1 背景
- 由于设备和环境的限制(设备故障,信号缺失),许多轨迹以低采样率记录,或者存在缺失的位置,称为不完整轨迹
- 恢复不完整轨迹的缺失空间-时间点并降低它们的不确定性是非常重要的
- 一般来说,关于轨迹恢复的先前研究可以分为两个方向
- 第一个方向:模拟用户在不同位置之间的转换模式,以预测用户的缺失位置
- 本质上是一个分类任务,恢复的轨迹通常由位置或POI组成
- 第二个方向:基于记录的不完整轨迹数据,恢复缺失时间戳处的特定地理坐标
- 最终重建的轨迹通常由精确的GPS或道路网络坐标组成
- 论文专注于这个方法
- 针对第二方向的一种直接方法是将单个轨迹直接视为二维时间序列,并应用时间序列插值方法来恢复不完整轨迹
- 在恢复过程中耗尽单个不完整轨迹的所有精确信息
- 当缺失轨迹数据的比例较小时效果非常好
- 随着缺失比例的增加,有效性会显著下降
- ——>无法处理稀疏的轨迹数据
- 另一个常见的解决方案是基于单元格的方法
- 将空间划分为离散的单元格,然后恢复由单元格描述的缺失轨迹,并设计不同的后校准算法来精炼结果
- 将轨迹恢复问题从无限连续空间转换为有限离散空间,降低了预测的复杂性,提高了模型对转换模式的建模能力
- 不足点
- 仅使用不完整轨迹中包含的信息,而没有充分利用来自其他轨迹的信息
- 使用单元格来表示轨迹,不可避免地会引入一些额外的噪声和不准确信息
- 在校准阶段,缺乏获得准确轨迹坐标的有效信息
- 第一个方向:模拟用户在不同位置之间的转换模式,以预测用户的缺失位置
1.2 本文思路
- 利用不同轨迹之间的相似性来建模不完整轨迹的复杂移动规律,论文提出了一个新颖的轨迹恢复框架,称为具有增强轨迹相似性的深度轨迹恢复(SimiDTR),以恢复轨迹的精确坐标
- 为了解决数据稀疏的问题,论文设计了一个基于规则的信息提取器,用于提取一个原始的相似轨迹,该轨迹具有关于给定不完整轨迹的相关空间信息
- 原始的相似轨迹是通过整合来自几个其他相关不完整轨迹的信息得到的
- 考虑到轨迹数据的特性(例如,空间偏差、时间偏差和时间位移),论文使用一个基于注意力的深度神经网络模型来整理这个原始的相似轨迹,并生成一个量身定制的相似轨迹,适应于不完整轨迹
- 这个相似轨迹实际上并不存在,但最适合不完整轨迹的数据,用于恢复不完整轨迹
- 为了充分利用轨迹坐标信息,我们在连续空间中进行轨迹恢复
- 为了解决数据稀疏的问题,论文设计了一个基于规则的信息提取器,用于提取一个原始的相似轨迹,该轨迹具有关于给定不完整轨迹的相关空间信息
2 related works
- 根据要恢复的对象,轨迹恢复可以分为位置恢复和坐标恢复
- 位置恢复旨在预测轨迹的缺失位置(例如,兴趣点POI)
- Bi-STDDP考虑了双向时空依赖性
- Modelling of bi-directional Spatio-temporal dependence and users’ dynamic preferences for missing poi checkin identification AAAI 2019
- AttnMove利用注意力机制将聚合的历史轨迹信息注入恢复过程
- AttnMove: history enhanced trajectory recovery via attentional network 2021 Arxiv
- 在AttnMove的基础上,PeriodicMove考虑了轨迹移动周期性的影响
- PeriodicMove: shiftaware human mobility recovery with graph neural network CIKM 2021
- Bi-STDDP考虑了双向时空依赖性
- 坐标恢复
- 基于时间序列的方法
- 将轨迹数据视为二维时间序列,时间序列插补方法可以用来恢复轨迹(时间序列)中缺失的坐标
- 基于单元格的方法
- 生成由单元格表示的恢复轨迹,然后使用后校准算法获取轨迹的坐标
- Wei等人构建了一个通过聚合轨迹的top-k路线推断框架
- 使用线性回归作为后校准模块
- Ren等人提出了一个深度学习模型,该模型利用传统的seq2seq框架和注意力机制
- 将单元格级轨迹输入深度学习模型,并直接预测道路段ID和移动比例
- 基于时间序列的方法
- 位置恢复旨在预测轨迹的缺失位置(例如,兴趣点POI)
3 问题定义
3.1 位置
一个位置由 l=(lon,lat) 表示,其中 lonlon 和 latlat 分别代表其经度和纬度
3.2 区域
将地理空间划分为一组离散且不相交的正方形区域,记为 R。每个区域(也称为网格或单元格),记为 r∈R
3.3 轨迹点
- 轨迹点是从移动对象采样的点,表示为 )p=(lon,lat,t),其中 t 表示其时间戳。
- 如果已知轨迹点的位置,则为记录的轨迹点(简称记录点),我们可以得到该点所在的区域 r。
- 否则,它是一个缺失的轨迹点(简称缺失点),表示为
3.4 采样间隔
- 采样间隔,记为 Δ,是两个连续轨迹点之间的时间差
- 理想情况下,轨迹数据的采样间隔是固定常数,但由于轨迹数据的固有时间偏差,采样间隔在大多数情况下经常接近 Δ 变化
3.5 完整轨迹
记为tr=p1→…→pi→…→pn,是从移动对象采样的记录点序列,其中 pi 是 tr 的第 i 个轨迹点
3.6 不完整轨迹
一个不完整轨迹由记录点序列和缺失点组成
3.7 问题定义
给定一组具有采样间隔 Δ 的不完整轨迹,目标是恢复它们缺失的坐标
4 模型

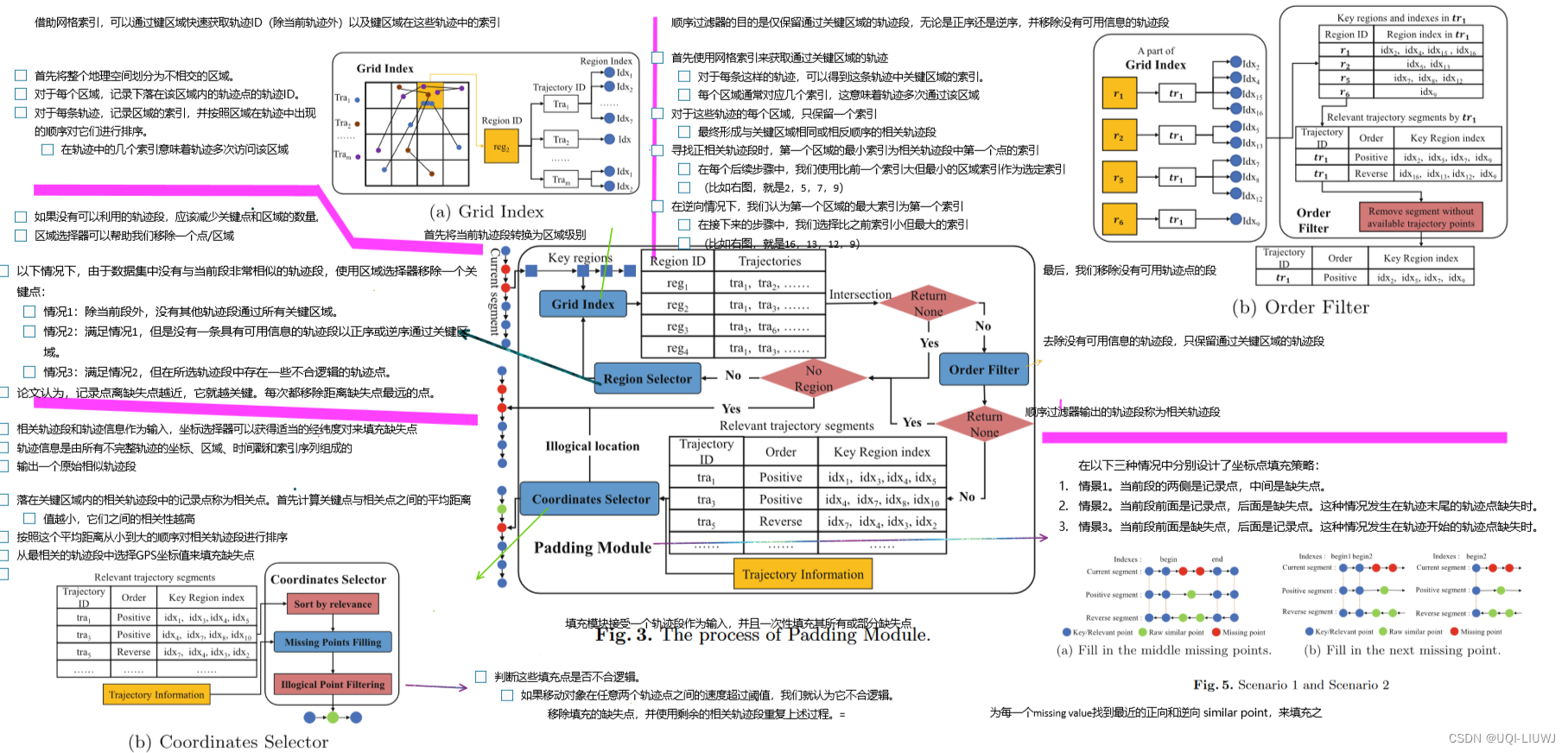
4.1 基于规则的信息提取器
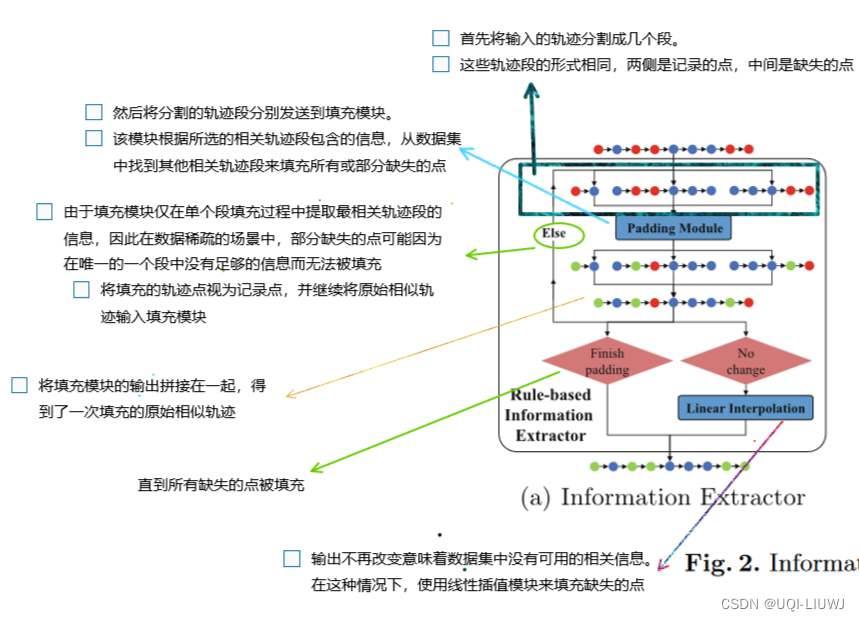

4.1.1 填充模组
4.2 轨迹embedding层
- 对于一个不完整的轨迹 tr=p1→⋯→pn,n∈N,其中 n 是轨迹 tr 的长度,N 是数据集中最长轨迹的长度。
- 轨迹 tr 的位置和时间戳分别是 L∈Rn×2 和T∈Rn×1
4.2.1 位置嵌入

4.2.2 时间戳嵌入
- 对于 T 中的每个时间戳 t,可以计算出 t 是当前小时的第
分钟和当前分钟的第
秒
- 然后我们将它们映射到区间 [-0.5, 0.5] 并遵循线性变换

4.2.3 坐标嵌入
为了确保缺失点(由填充)在映射到高维空间时仍然是 0 (
),我们使用一维卷积作为映射函数
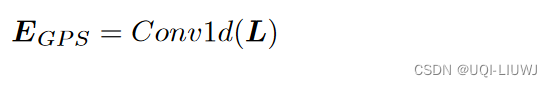
4.2.4 嵌入整合
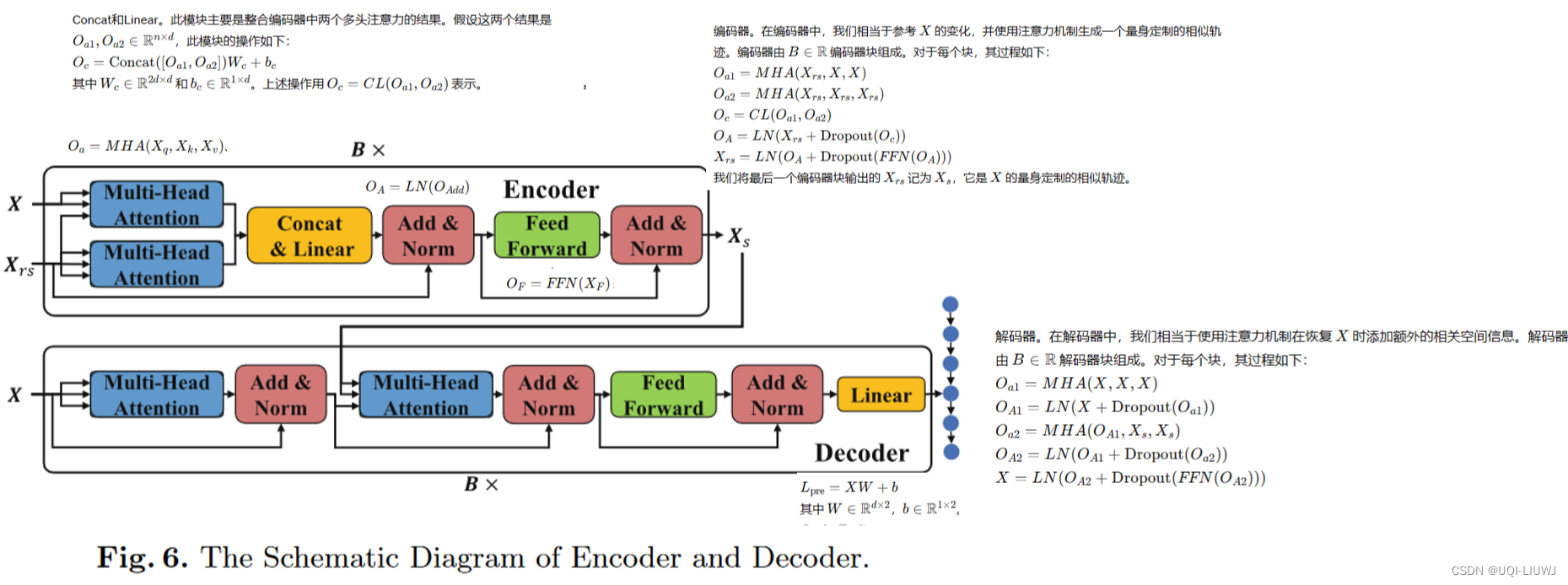
- 假设 tr 的原始相似轨迹表示为 trrs。
- 因为trrs只是相关空间信息的刚性组合,这意味着 T 在缺失点上不适合 trrs

4.3 encoder-decoder
5 实验
5.1 数据
- 从波尔图1和上海2收集的两个真实世界出租车轨迹数据集。
- 对于波尔图数据集,我们将间隔从15秒转换为1分钟
- 对于上海出租车数据集,我们将出租车的停留点视为边界来分割它们整天的轨迹
- 移除所有包含超出纬度和经度范围点的轨迹
- 如果某一区域中的轨迹点数量少于区域点阈值,我们将移除这些区域以及其中的点
- 经过预处理后,波尔图的时间间隔是常数,即60秒,而上海的时间间隔是可变的
- 将每个数据集分成三个部分,分割比例为7:1:2,作为训练集、验证集和测试集
- 随机保留每条轨迹1 − ratio%(ratio =30, 50, 70)的点
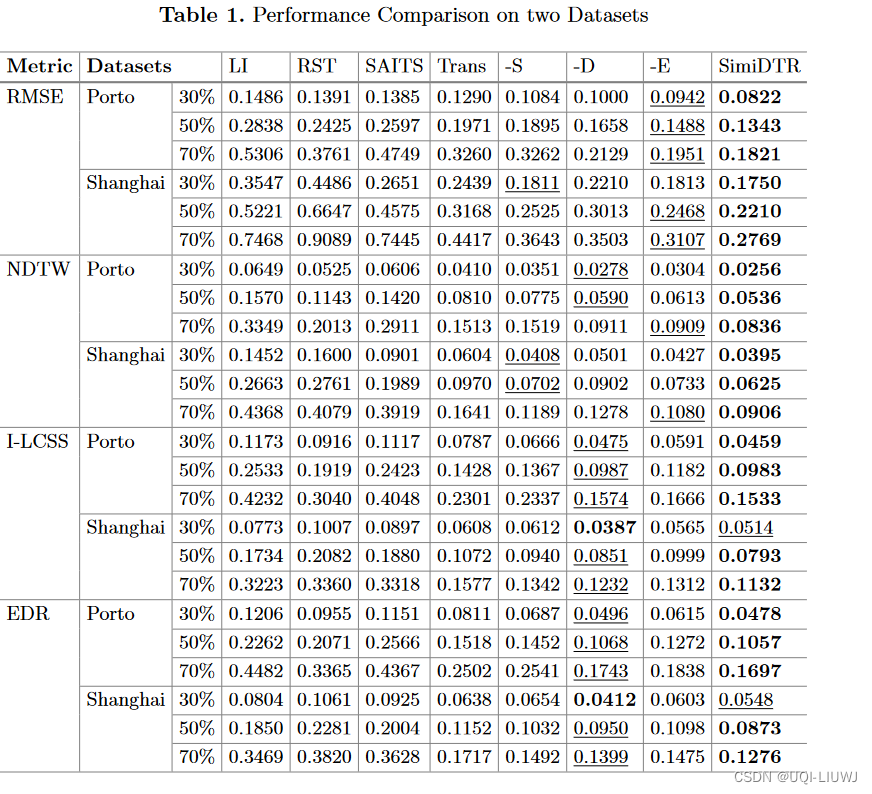
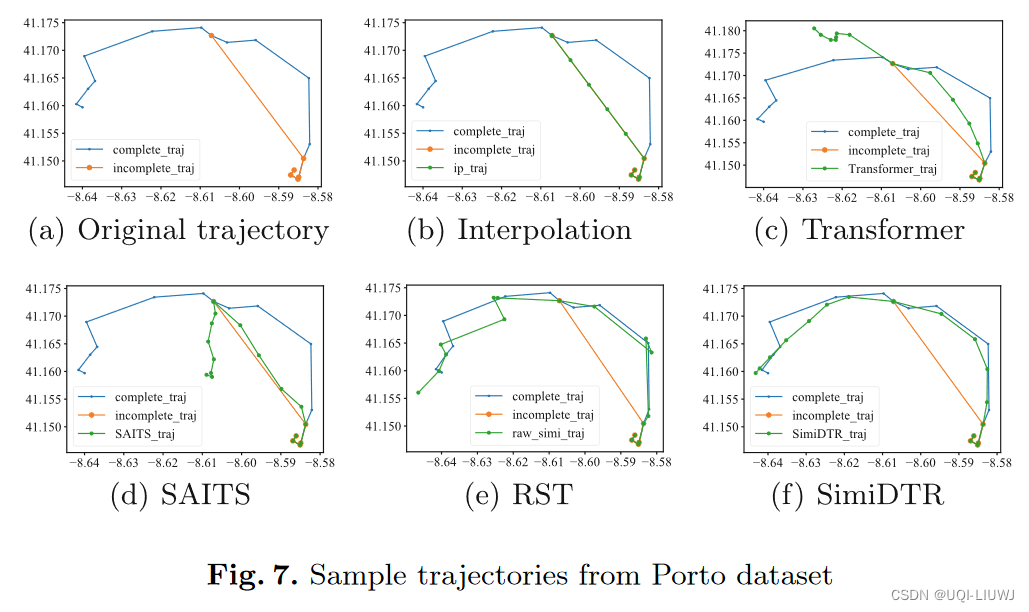
5.2 结果
这篇关于论文笔记:SimiDTR: Deep Trajectory Recovery with Enhanced Trajectory Similarity的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







