图片来源:
https://blog.csdn.net/dylan_frank/article/details/78177368
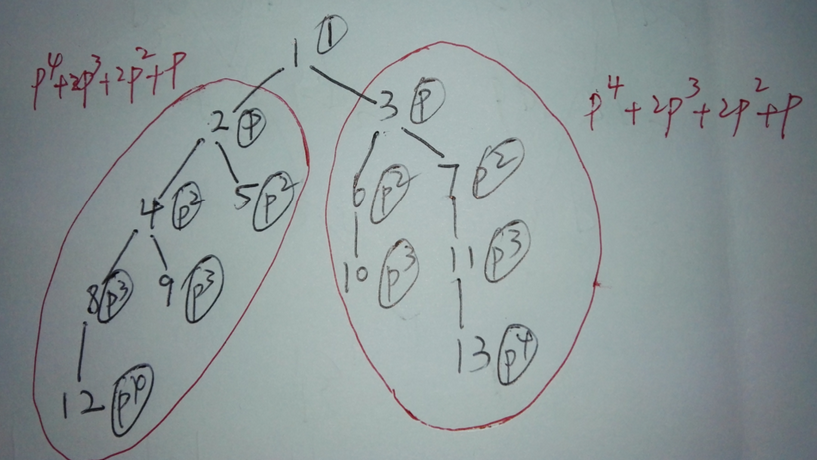
【题意】:
对于每一个节点来说有多少对相同的子树。
【题解】:
利用层数进行hash,返回到对应的节点,最后标记后用等差数列来求出所有方案数。


1 #pragma GCC optimize(2) 2 #include<bits/stdc++.h> 3 using namespace std; 4 typedef unsigned long long ull ; 5 6 const int N = 1e5+10; 7 const ull p = 9901 ; 8 9 vector<int> G[N]; 10 map < ull , int > Mp ; 11 ull Hash[N]; 12 13 void dfs( int u , int Fa ){ 14 Hash[u] = 1 ; 15 for( auto To : G[u] ){ 16 dfs( To , u ) ; 17 Hash[u] = ( Hash[u] + Hash[To] * p ) ; 18 } 19 Mp[ Hash[u] ] ++; 20 } 21 22 int main() 23 { 24 ios_base :: sync_with_stdio(false); 25 cin.tie(NULL) , cout.tie(NULL) ; 26 27 int n ; 28 cin >> n ; 29 for( int i = 1 , u , v ; i < n ; i++ ){ 30 cin >> u >> v ; 31 G[u].push_back( v ); 32 } 33 34 dfs( 1 , 0 ); 35 ull ans = 0 ; 36 37 //map< ll , int > :: iterator it = Mp.begin(); 38 for( auto x : Mp){ 39 ull tmp = x.second ; 40 ans += ( tmp - 1 ) * tmp / 2 ; 41 } 42 cout << ans << endl ; 43 44 return 0 ; 45 }



