hash专题

Redis的Hash类型及相关命令小结
《Redis的Hash类型及相关命令小结》edisHash是一种数据结构,用于存储字段和值的映射关系,本文就来介绍一下Redis的Hash类型及相关命令小结,具有一定的参考价值,感兴趣的可以了解一下... 目录HSETHGETHEXISTSHDELHKEYSHVALSHGETALLHMGETHLENHSET

hdu1043(八数码问题,广搜 + hash(实现状态压缩) )
利用康拓展开将一个排列映射成一个自然数,然后就变成了普通的广搜题。 #include<iostream>#include<algorithm>#include<string>#include<stack>#include<queue>#include<map>#include<stdio.h>#include<stdlib.h>#include<ctype.h>#inclu
康拓展开(hash算法中会用到)
康拓展开是一个全排列到一个自然数的双射(也就是某个全排列与某个自然数一一对应) 公式: X=a[n]*(n-1)!+a[n-1]*(n-2)!+...+a[i]*(i-1)!+...+a[1]*0! 其中,a[i]为整数,并且0<=a[i]<i,1<=i<=n。(a[i]在不同应用中的含义不同); 典型应用: 计算当前排列在所有由小到大全排列中的顺序,也就是说求当前排列是第
hdu1496(用hash思想统计数目)
作为一个刚学hash的孩子,感觉这道题目很不错,灵活的运用的数组的下标。 解题步骤:如果用常规方法解,那么时间复杂度为O(n^4),肯定会超时,然后参考了网上的解题方法,将等式分成两个部分,a*x1^2+b*x2^2和c*x3^2+d*x4^2, 各自作为数组的下标,如果两部分相加为0,则满足等式; 代码如下: #include<iostream>#include<algorithm
usaco 1.2 Milking Cows(类hash表)
第一种思路被卡了时间 到第二种思路的时候就觉得第一种思路太坑爹了 代码又长又臭还超时!! 第一种思路:我不知道为什么最后一组数据会被卡 超时超了0.2s左右 大概想法是 快排加一个遍历 先将开始时间按升序排好 然后开始遍历比较 1 若 下一个开始beg[i] 小于 tem_end 则说明本组数据与上组数据是在连续的一个区间 取max( ed[i],tem_end ) 2 反之 这个
uva 10029 HASH + DP
题意: 给一个字典,里面有好多单词。单词可以由增加、删除、变换,变成另一个单词,问能变换的最长单词长度。 解析: HASH+dp 代码: #include <iostream>#include <cstdio>#include <cstdlib>#include <algorithm>#include <cstring>#include <cmath>#inc

整数Hash散列总结
方法: step1 :线性探测 step2 散列 当 h(k)位置已经存储有元素的时候,依次探查(h(k)+i) mod S, i=1,2,3…,直到找到空的存储单元为止。其中,S为 数组长度。 HDU 1496 a*x1^2+b*x2^2+c*x3^2+d*x4^2=0 。 x在 [-100,100] 解的个数 const int MaxN = 3000
POJ 1198 双广+Hash
此题采用双广可从bfs的O(16^8)降低到O(2*16^4); 坐标0-7,刚好3位存储, 需要24位存储四个坐标(x,y),也就是[0,2^24) 。 很好的一题。 import java.io.BufferedReader;import java.io.InputStream;import java.io.InputStreamReader;import

C# Hash算法之MD5、SHA
MD5我们用的还是比较多的,一般用来加密存储密码。但是现在很多人觉MD5可能不太安全了,所以都用上了SHA256等来做加密(虽然我觉得都差不多,MD5还是能玩)。 还是跟上一篇说的一样,当一个算法的复杂度提高的同时肯定会带来效率的降低,所以SHA和MD5比较起来的话,SHA更安全,MD5更高效。 由于HASH算法的不可逆性,所以我认为MD5和SHA主要还是应用在字符串的"加密"上。 由于
CPP中的hash [more cpp-7]
写在前面 hash 在英文中是弄乱的含义。在编程中,hash是一种数据技术,它把任意类型的数据通过算法,生成一串数字(hash code),实现hash的函数称为哈希函数,又称散列函数,杂凑函数。在CPP中hashcode是一个size_t类型的数字。 你可能会问?把数据弄乱有什么用?为什么我们要把数据映射到一串数字上?这又什么意义吗?我们先看看hash的性质 一般hash性质 唯一性(唯
apt-get update更新源时,出现“Hash Sum mismatch”问题
转载自:apt-get update更新源时,出现“Hash Sum mismatch”问题 当使用apt-get update更新源时,出现下面“Hash Sum mismatch”的报错,具体如下: root@localhost:~# apt-get update ...... ...... W: Failed to fetch http://us.archive.ubuntu.com/ub

加密方式的判断---神器 hash_identifier
加密作为保障数据安全的一种方式,它不是现在才有的,它产生的历史相当久远,它是起源于要追溯于公元前2000年(几个世纪了),虽然它不是现在我们所讲的加密技术(甚至不叫加密),但作为一种加密的概念,确实早在几个世纪前就诞生了。当时埃及人是最先使用特别的象形文字作为信息编码的,随着时间推移,巴比伦、美索不达米亚和希腊文明都开始使用一些方法来保护他们的书面信息。 加密在网络上的作用就是防止有用或私有
【0323】Postgres内核之 hash table sequentially search(seq_scan_tables、num_seq_scans)
0. seq scan tracking 我们在这里跟踪活跃的 hash_seq_search() 扫描。 需要这种机制是因为如果扫描正在进行时发生桶分裂(bucket split),它可能会访问两次相同的条目,甚至完全错过某些条目(如果它正在访问同一个分裂的桶中的条目)。因此,如果正在向表中插入数据,我们希望抑制桶分裂。 在当前的使用中,这种情况非常罕见,因此只需将分裂推迟到下一次插入即可。

Vue 项目hash和history模式打包部署与服务器配置
你好,我是沐爸,欢迎点赞、收藏、评论和关注。 在开发 Vue 项目时,Vue Router 提供了两种模式来创建单页面应用(SPA)的 URL:hash 模式和 history 模式。 简单说下两者的主要区别: hash 模式下的 URL 看起来不那么美观,带有一个 # 符号。在这种模式下,URL 中的 hash 值(# 后面的部分)会改变,但页面不会重新加载。因为不会向服务器发送请求,服
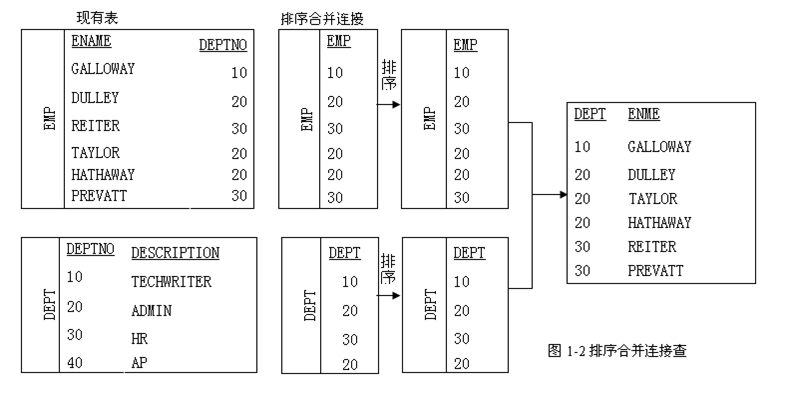
多表连接的三种方式hash join,merge join,nested loop
多表之间的连接有三种方式:Nested Loops,Hash Join和 Sort Merge Join. 下面来介绍三种不同连接的不同: 一. NESTED LOOP: 对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回

初识redis(String,Hash,List,Set,SortedSet)
认识NoSql sql关系型数据库 nosql非关系型数据库 nosql具有非结构化,Key/Value,Document,Draph 无关联的,非sql,BASE(原子性,持久性,一致性,隔离性) 认识redis 特征: 键值(key-value)型,value支持多种不同数据结构,功能丰富 单线程,每个命令具备原子性 低延迟,速度快(基于内存、I0多路复用、良好的编码)
Java SE面试—Hash Map
目录 HashMap底层原理 Put方法 Get方法 哈希冲突 HashMap的扩容 HashMap与HashTable区别 LinkedHashMap TreeMap HashMap底层原理 HashMap底层数据结构是数组+链表+红黑树,在1.7之前是数组+链表,由于链表是顺序查询,查询效率低,所以在链表长度大于8的时候,会将链表升级为红黑树 Put方法 当一个键
Codeforces Round #FF (Div. 2/A)/Codeforces447A_DZY Loves Hash(哈希)
A. DZY Loves Hash time limit per test 1 second memory limit per test 256 megabytes input standard input output standard output DZY has a hash table with p buckets, numbered from

一致性Hash算法,Java代码实现
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法、一致性Hash算法的算法原理做了详细的解读。 算法的具体原理这里再次贴上: 先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个H
Redis的String和Hash
String Redis底层是使用C实现的,但是它并没有使用C中char* 的方法,而是自己定义了一个SDS,也就是简单字符串,先说一下char*以及它的缺点。 char*是C中String的实现,它在读取到 '\0'后就会停止,C中把这个符号作为String的结尾。因此如果 '\0'后还有其他字符,C中并不会把它算在里面。并且如果想要知道String的长度,需要遍历所有字符串,在时间复杂度上
C++ tbb::concurrent_hash_map怎么用
Intel TBB 提供高并发的容器类,Windows或者Linux线程能使用这些容器类或者和基于task编程相结合(TBB)。 concurrent_hash_map<Key,T,HashCompare>是一个hash表,允许并行访问,表是一个从Key到类型T的映射,类型HashCompare定义怎样hash一个Key和怎样比较2个Key。 concurrent_hash_map i
C++ 洛谷 哈希表(对应题库:哈希,hash)习题集及代码
马上就开学了,又一个卷季,不写点东西怎么行呢?辣么,我不准备写那些dalao们都懂得,熟练的,想来想去,最终还是写哈希表吧!提供讲解&题目&代码解析哦! 奉上题目链接: 洛谷题目 - 哈希,hash 1、哈希、哈希表(hash)简介 哈希(Hash)是一种将任意长度的输入映射为固定长度输出的算法。哈希函数的输出值称为哈希值或散列值。哈希函数具有以下特性: 确定性:对于相同的输入

Nginx: 负载均衡基础配置, 加权轮序, hash算法, ip_hash算法, least_conn算法
负载均衡 在真正的反向代理场景中,必然涉及到的一个概念,就是负载均衡所谓负载均衡,也就是将Nginx的请求发送给后端的多台应用程序服务器通常的应用程序服务器,后面的每台服务器都是一个同等的角色,提供相同的功能 用户发送一个request 到我们的这个负载均衡器(Nginx)负载均衡器会将这个请求发给后端的任何一台服务器它会依据一定的负载均衡算法去后端的三台服务器中选择其中的一台从而将

零基础学习Redis(7) -- hash类型命令使用
Redis本身就是通过哈希表的方式组织数据,同时redis中的value也可以是另一个哈希表。 1. 常用命令 1. hset / hsetnx hset key filed1 value1 filed2 value2 ... hset 用于把键值对存入value中,这里的key为redis组织的键, filed1 value1 filed2 value2 为key的value,为了
