本文主要是介绍Lucene关于实现Similarity自定义排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
开场白:
作为一个人才网站的搜索功能,不但需要考滤搜索性能与效率,与需要注意用户体验,主要体现于用户对搜索结果的满意程度.大家都知道Lucene的排序中,如果单纯使用Lucene的DefaultSimilarity作为一个相似度的排序,意思是说总体上越相关的记录需要排得越前,但事与愿违.这样使用户体现也表现得相当糟糕.关键字"程序员"标题中也不能保证全部都匹配到(搜索结果来自 www.jobui.com 职友集) [下图]
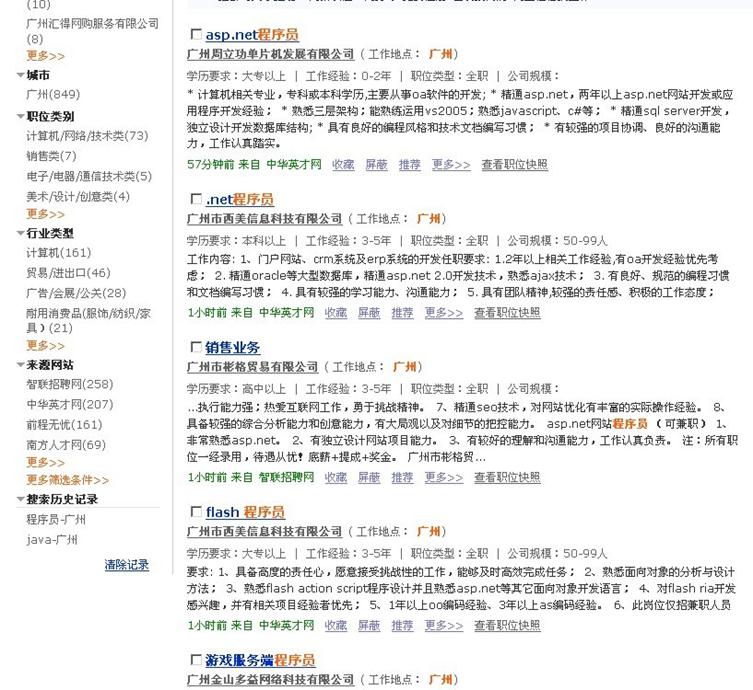
起因:之很长一段时间我都注重于搜索性能与速度的提高,而对于搜索结果对用户的体验却一直没有太多的关注,现在需要关注一下用户体现这个东西了.同时技术上也作为一些调整.具体表现如下.
1,用户最需要的搜索结果是标题命中.
2,因为我们从事人才招聘行业,所以职位的发布时间需要最新的.
所以经过各部门商量,职位搜索的结果排序应该是,相关度优先,然后才是职位的发布时间倒序.即如果关键字匹配是一定要全部命中了才会排在第一位,然后再是只命中一部分关键字记录.具体如下图,(搜索"php 开发",这样的话,只有php,开发这两个关键字都全部匹配了才会排前.然后全部命中关键字的记录按职位的发布时间来递减.)

开始:主要是继承Lucene中的Similarity作为一个相似度的实现,这里简单介绍一下相关的介绍
主要是几个排序影响因素去想的
在看代码之前先看看我们Lucene排序的一些影响因为,大家可以在搜索的时候,开启Explain的选项,这样就能看得清楚了
比如说,我现在要搜索 "开发工程" 这些关键字,然后就会把每一个Document的得分情况都列出来,大家就知道了,同时大家有没发现,这一个详细情况跟Similarity的需要实现的方法的因素基本都是对应的..比如 idf,tf queryNorm等方法..这样大家就有一个可以参考分析的方法了.

200.0 = (MATCH) sum of:
100.0 = (MATCH) weight(Name:开发^100.0 in 5), product of:
100.0 = queryWeight(Name:开发^100.0), product of:
100.0 = boost
1.0 = idf(docFreq=4, maxDocs=6)
1.0 = queryNorm
1.0 = (MATCH) fieldWeight(Name:开发 in 5), product of:
1.0 = tf(termFreq(Name:开发)=0)
1.0 = idf(docFreq=4, maxDocs=6)
1.0 = fieldNorm(field=Name, doc=5)
100.0 = (MATCH) weight(Name:工程^100.0 in 5), product of:
100.0 = queryWeight(Name:工程^100.0), product of:
100.0 = boost
1.0 = idf(docFreq=2, maxDocs=6)
1.0 = queryNorm
1.0 = (MATCH) fieldWeight(Name:工程 in 5), product of:
1.0 = tf(termFreq(Name:工程)=1)
1.0 = idf(docFreq=2, maxDocs=6)
1.0 = fieldNorm(field=Name, doc=5)
0.0 = (MATCH) weight(Info:开发^0.0 in 5), product of:
0.0 = queryWeight(Info:开发^0.0), product of:
0.0 = boost
1.0 = idf(docFreq=4, maxDocs=6)
1.0 = queryNorm
1.0 = (MATCH) fieldWeight(Info:开发 in 5), product of:
1.0 = tf(termFreq(Info:开发)=2)
1.0 = idf(docFreq=4, maxDocs=6)
1.0 = fieldNorm(field=Info, doc=5)
0.0 = (MATCH) weight(Info:工程^0.0 in 5), product of:
0.0 = queryWeight(Info:工程^0.0), product of:
0.0 = boost
1.0 = idf(docFreq=0, maxDocs=6)
1.0 = queryNorm
1.0 = (MATCH) fieldWeight(Info:工程 in 5), product of:
1.0 = tf(termFreq(Info:工程)=0)
1.0 = idf(docFreq=0, maxDocs=6)
1.0 = fieldNorm(field=Info, doc=5)
现在先看看实现 Similarity 类的方法
1 package com.kernaling;
2
3 import org.apache.lucene.index.FieldInvertState;
4
5 public class BaicaiPositionSimilarity extends Similarity {
6
7 /** Implemented as
8 * <code>state.getBoost()*lengthNorm(numTerms)</code>, where
9 * <code>numTerms</code> is {@link FieldInvertState#getLength()} if {@link
10 * #setDiscountOverlaps} is false, else it's {@link
11 * FieldInvertState#getLength()} - {@link
12 * FieldInvertState#getNumOverlap()}.
13 *
14 * <p><b>WARNING</b>: This API is new and experimental, and may suddenly
15 * change.</p> */
16 @Override
17 public float computeNorm(String field, FieldInvertState state) {
18 final int numTerms;
19 if (discountOverlaps)
20 numTerms = state.getLength() - state.getNumOverlap();
21 else
22 numTerms = state.getLength();
23 return (state.getBoost() * lengthNorm(field, numTerms));
24 }
25
26 /** Implemented as <code>1/sqrt(numTerms)</code>. */
27 @Override
28 public float lengthNorm(String fieldName, int numTerms) {
29 // System.out.println("fieldName:" + fieldName + "\tnumTerms:" + numTerms);
30 // return (float)(1.0 / Math.sqrt(numTerms));
31 return 1.0f;
32 }
33
34 /** Implemented as <code>1/sqrt(sumOfSquaredWeights)</code>. */
35 @Override
36 public float queryNorm(float sumOfSquaredWeights) {
37 // return (float)(1.0 / Math.sqrt(sumOfSquaredWeights));\
38 return 1.0f;
39 }
40
41 /** Implemented as <code>sqrt(freq)</code>. */
42 // term freq 表示 term 在一个document的出现次数,这里设置为1.0f表示不考滤这个因素影响
43 // @Override
44 // public float tf(float freq) {
45 return 1.0f;
46
47 }
48
49 /** Implemented as <code>1 / (distance + 1)</code>. */
50 //这里表示匹配的 term 与 term之间的距离因素,同样也不应该受影响
51 @Override
52 public float sloppyFreq(int distance) {
53 return 1.0f;
54 }
55
56 /** Implemented as <code>log(numDocs/(docFreq+1)) + 1</code>. */
57 //这里表示匹配的docuemnt在全部document的影响因素,同理也不考滤
58 @Override
59 public float idf(int docFreq, int numDocs) {
60 return 1.0f;
61 }
62
63 /** Implemented as <code>overlap / maxOverlap</code>. */
64 //这里表示每一个Document中所有匹配的关键字与当前关键字的匹配比例因素影响,同理也不考滤.
65 @Override
66 public float coord(int overlap, int maxOverlap) {
67 return 1.0f;
68 }
69
70 // Default false
71 protected boolean discountOverlaps;
72
73 /** Determines whether overlap tokens (Tokens with
74 * 0 position increment) are ignored when computing
75 * norm. By default this is false, meaning overlap
76 * tokens are counted just like non-overlap tokens.
77 *
78 * <p><b>WARNING</b>: This API is new and experimental, and may suddenly
79 * change.</p>
80 *
81 * @see #computeNorm
82 */
83 public void setDiscountOverlaps(boolean v) {
84 discountOverlaps = v;
85 }
86
87 /**@see #setDiscountOverlaps */
88 public boolean getDiscountOverlaps() {
89 return discountOverlaps;
90 }
91 }
按上面的相似度因素影响,基本上都设置为不受其他影响了,现在只剩下了关键字匹配数据的影响了,也就是我们需求中需要的.
然后做一个测试类:
1 package com.kernaling;
2
3 import java.io.File;
4 import java.io.StringReader;
5
6 import org.apache.lucene.document.Document;
7 import org.apache.lucene.document.Field;
8 import org.apache.lucene.index.IndexWriter;
9 import org.apache.lucene.index.Term;
10 import org.apache.lucene.index.IndexWriter.MaxFieldLength;
11 import org.apache.lucene.search.BooleanClause;
12 import org.apache.lucene.search.BooleanQuery;
13 import org.apache.lucene.search.Explanation;
14 import org.apache.lucene.search.IndexSearcher;
15 import org.apache.lucene.search.ScoreDoc;
16 import org.apache.lucene.search.Sort;
17 import org.apache.lucene.search.SortField;
18 import org.apache.lucene.search.TermQuery;
19 import org.apache.lucene.search.TopDocs;
20 import org.apache.lucene.search.TopFieldCollector;
21 import org.apache.lucene.store.NIOFSDirectory;
22 import org.wltea.analyzer.IKSegmentation;
23 import org.wltea.analyzer.Lexeme;
24 import org.wltea.analyzer.lucene.IKAnalyzer;
25
26 public class LuceneSortSample {
27 public static void main(String[] args) {
28 try{
29
30 String path = "./Index";
31 IKAnalyzer analyzer = new IKAnalyzer();
32 MySimilarity similarity = new MySimilarity();
33
34 boolean isIndex = false; // true:要索引,false:表示要搜索
35
36 if(isIndex){
37 IndexWriter writer = new IndexWriter(new NIOFSDirectory(new File(path)),analyzer,MaxFieldLength.LIMITED);
38 writer.setSimilarity(similarity); //设置相关度
39
40 Document doc_0 = new Document();
41 doc_0.add(new Field("Name","java 开发人员", Field.Store.YES, Field.Index.ANALYZED));
42 doc_0.add(new Field("Info","招聘 网站开发人员,要求一年或以上工作经验", Field.Store.YES, Field.Index.ANALYZED));
43 doc_0.add(new Field("Time","20100201", Field.Store.YES, Field.Index.NOT_ANALYZED));
44 writer.addDocument(doc_0);
45
46
47 Document doc_1 = new Document();
48 doc_1.add(new Field("Name","高级开发人员(java 方向)", Field.Store.YES, Field.Index.ANALYZED));
49 doc_1.add(new Field("Info","需要有四年或者以上的工作经验,有大型项目实践,java基本扎实", Field.Store.YES, Field.Index.ANALYZED));
50 doc_1.add(new Field("Time","20100131", Field.Store.YES, Field.Index.NOT_ANALYZED));
51 writer.addDocument(doc_1);
52
53
54 Document doc_2 = new Document();
55 doc_2.add(new Field("Name","php 开发工程师", Field.Store.YES, Field.Index.ANALYZED));
56 doc_2.add(new Field("Info","主要是维护公司的网站php开发,能独立完成网站的功能", Field.Store.YES, Field.Index.ANALYZED));
57 doc_2.add(new Field("Time","20100201", Field.Store.YES, Field.Index.NOT_ANALYZED));
58 writer.addDocument(doc_2);
59
60
61 Document doc_3 = new Document();
62 doc_3.add(new Field("Name","linux 管理员", Field.Store.YES, Field.Index.ANALYZED));
63 doc_3.add(new Field("Info","管理及维护公司的linux服务器,职责包括完成mysql数据备份及日常管理,apache的性能调优等", Field.Store.YES, Field.Index.ANALYZED));
64 doc_3.add(new Field("Time","20100201", Field.Store.YES, Field.Index.NOT_ANALYZED));
65 writer.addDocument(doc_3);
66
67
68 Document doc_4 = new Document();
69 doc_4.add(new Field("Name","lucene开发工作师", Field.Store.YES, Field.Index.ANALYZED));
70 doc_4.add(new Field("Info","需要两年或者以上的从事lucene java 开发工作的经验,需要对算法,排序规则等有相关经验,java水平及基础要扎实", Field.Store.YES, Field.Index.ANALYZED));
71 doc_4.add(new Field("Time","20100131", Field.Store.YES, Field.Index.NOT_ANALYZED));
72 writer.addDocument(doc_4);
73
74
75 Document doc_5 = new Document();
76 doc_5.add(new Field("Name","php 软件工程师", Field.Store.YES, Field.Index.ANALYZED));
77 doc_5.add(new Field("Info","具有大量的php开发经验,如熟悉 java 开发,数据库管理则更佳", Field.Store.YES, Field.Index.ANALYZED));
78 doc_5.add(new Field("Time","20100130", Field.Store.YES, Field.Index.NOT_ANALYZED));
79 writer.addDocument(doc_5);
80
81 writer.close();
82 System.out.println("数据索引完成");
83 }else{
84 IndexSearcher search = new IndexSearcher(new NIOFSDirectory(new File(path)));
85 search.setSimilarity(similarity);
86 String keyWords = "java开发";
87
88
89 String fiels[] = {"Name","Info"};
90
91 BooleanQuery bq = new BooleanQuery();
92 for(int i=0;i<fiels.length;i++){
93
94 IKSegmentation se = new IKSegmentation(new StringReader(keyWords), true);
95 Lexeme le = null;
96
97 while((le=se.next())!=null){
98 String tKeyWord = le.getLexemeText();
99 String tFeild = fiels[i];
100 TermQuery tq = new TermQuery(new Term(fiels[i], tKeyWord));
101
102 if(tFeild.equals("Name")){ //在Name这一个Field需要给大的比重
103 tq.setBoost(100.0f);
104 }else{
105 tq.setBoost(0.0f); //其他的不需要考滤
106 }
107
108 bq.add(tq, BooleanClause.Occur.SHOULD); //关键字之间是 "或" 的关系
109 }
110 }
111 System.out.println("搜索条件Query:" + bq.toString());
112 System.out.println();
113 Sort sort = new Sort(new SortField[]{new SortField(null,SortField.SCORE,false),new SortField("Time", SortField.INT,true)});
114 //先按记录的得分排序,然后再按记录的发布时间倒序
115 TopFieldCollector collector = TopFieldCollector.create(sort , 10 , false , true , false , false);
116
117 long l = System.currentTimeMillis();
118 search.search(bq, collector);
119 TopDocs tDocs = collector.topDocs();
120
121 ScoreDoc sDocs[] = tDocs.scoreDocs;
122
123 int len = sDocs.length;
124
125 for(int i=0;i<len;i++){
126 ScoreDoc tScore = sDocs[i];
127 // tScore.score 从Lucene3.0开始已经不能通过这样来得到些文档的得分了
128 int docId = tScore.doc;
129 Explanation exp = search.explain(bq, docId);
130
131 Document tDoc = search.doc(docId);
132 String Name = tDoc.get("Name");
133 String Info = tDoc.get("Info");
134 String Time = tDoc.get("Time");
135
136 float score = exp.getValue();
137 // System.out.println(exp.toString()); 如果需要打印文档得分的详细信息则可以通过此方法
138 System.out.println("DocId:"+docId+"\tScore:" + score + "\tName:" + Name + "\tTime:" + Time + "\tInfo:" + Info);
139 }
140 l = System.currentTimeMillis() - l;
141 System.out.println("搜索用时:" + l + "ms");
142 search.close();
143 }
144
145 }catch(Exception ex){
146 ex.printStackTrace();
147 }
148 }
149 }
建立完索引后然后就可以直接搜索了.效果图如下: 
可以看到,我们现在搜索关键字"开发工程", 然后就可以看到DocID:为 0,2为关键字全部命中的文档,然后这两个文档就按时间倒序排了.
然后,DocId 1,4,5的话,就只匹配到部分的关键字,它肯定会比全部命中关键字的记录要排序要后,然后中命中部分关键字的记录又会按发布时间来倒序排了一次
对了,我是用 Lucene3.0 作为开发包的.与Lucene2.XX的很多接口都改了,包括Similarity 的继承类的方法也不同, 所以大家要注思,不过经过测试,只要相同的实现那么效果也是一样的.
注意:从上边的测试结果可以看到一个疑问,这些记录匹配的关键字 开发工程 中,无论是命中全部关键字还是一个,得到的score都是一样的,但是排序的时候却按我们之前设置的意义去排序,理论上来说,只匹配一半的关键字,score会是全部匹配的一半的,这里的话,不知道是否是一个bug.有待继续研究.同时职友集www.jobui.com与百才招聘 www.baicai.com 这两个网站的搜索功能还没有把这个想法用到上边去,现在只在本地的测试服务器中有效,因为这段时间有其他事情要做.请大家见谅.过年后左右,大家会有一个全新的搜索体验..谢谢.
来自互联网
这篇关于Lucene关于实现Similarity自定义排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







