lucene专题

MySQL和Lucene(Elasticsearch)索引对比分析
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 大数据真好玩 点击右侧关注,大数据真好玩! 本文是来自略速互联网笔记的分享。 你可以在这里查看原文:http://www.lvesu.com/?uri=/blog/main/cms-611.html 前言 相比于大多数人熟悉的 MySQL 数据库的索引,Elasti

9、索引库的查询三之:Lucene的多样化查询
1.4 Lucene的多样化查询 在指定的项范围内搜索-TermRangeQuery类通过字符串搜索-PrefixQuery类 组合查询-BooleanQuery类通过短语搜索-PhraseQuery类通配符查询-WildcardQuery类搜索类似项-FuzzyQuery类不匹配文档-MatchNoDocsQuery类解析查询表达式-QueryParser类多短语查询-MultiPh

lucene搜索关键词错误
问题 遇到的异常信息 : Lexical error at line 1, column 38. Encountered: <EOF> afterat org.apache.lucene.queryparser.classic.QueryParserBase.parse(QueryParserBase.java:114) 解决办法 查询搜索时遇到了特殊字符,需要对字符串进行转义 p

Lucene索引过程详解
使用addDocument方法向索引添加文档 segment的概念,所谓segment,其实指的是一个逻辑概念,在每个segment里,有许多的Document,一个索引中,可能有很多个segment。 .Lucene 对索引的管理的最大的单位就是segment.每个segment内的索引文件都具有相同的前缀。 package indexwriter; import java.io.IO
Lucene中Document的内部实现
//Document 内部的实现 package document; import org.apache.lucene.document.Field; import org.apache.lucene.document.*; public class Document { //为Document加入一个Field, 这个也是对常用到的方法 //public final void add(F

一个自定义的用语过滤非字符的Lucene分析器
<strong><span style="font-size:18px;">/**** @author YangXin* @info 一个定义的用语过滤非字字符的Lucene分析器*/package unitNine;import org.apache.lucene.analysis.Analyzer;import java.io.IOException;import java.io.Rea
apache lucene solr 官网历史版本下载地址
lucene的历史版本下载地址: http://archive.apache.org/dist/lucene/java/ solr的历史版本下载地址: https://archive.apache.org/dist/lucene/solr/

LUCENE 3.6 学习笔记
目前,主流的全文索引工具有:Lucene , Sphinx , Solr , ElasticSearch。其中Solr和Elastic Search都是基于Lucene的。Sphinx不是 apache的项目,如果你想把Sphinx放到某个商业性的项目中,你就得买个商业许可证。 此文章为个人学习备忘之用,仅适合lucene的初学者参考阅读。至于lucene能做什么,自己百度就
Lucene的一个简单的标准测试(Lucene包基于3.5版本的)
Lucene编程一般分为:索引、分词、搜索 索引源代码: package lucene的一个标准测试;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;

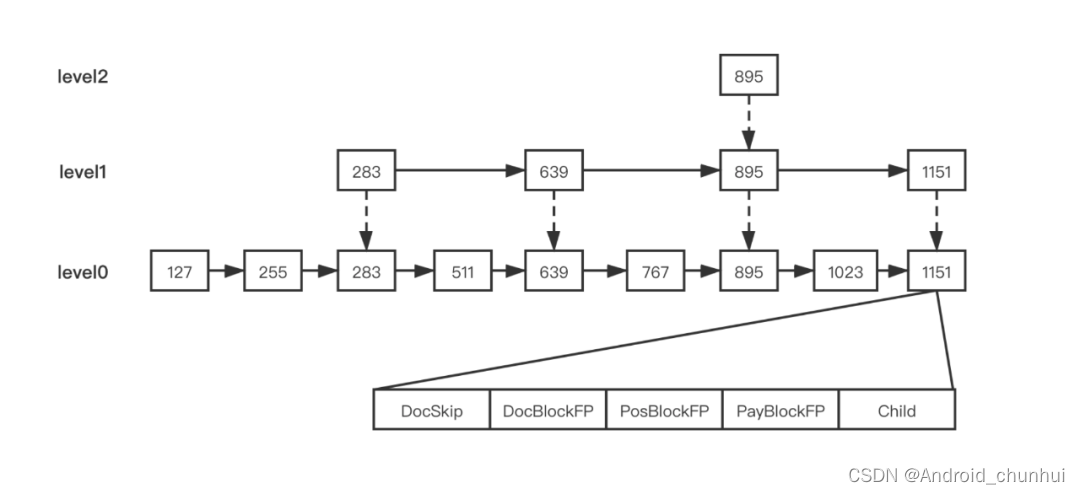
Block-Max-Maxscore(Lucene 9.10.0)
Lucene中基于论文:Optimizing Top-k Document Retrieval Strategies for Block-Max Indexes 实现了Block-Max-Maxscore (BMM) 算法,用来优化关键字之间只有OR关系,并且minShouldMatch <= 1时的查询。比如有查询条件为:term1 OR term2 OR term3,那么文档中至少包含其中一个

基于lucene的搜索方案
说是电子商务搜索架构方案,其实就是lucene.net的应用,公司庙小,人少,也就自己平时看看,以前做过一点例子,这样就被拉上去写架构方案了。我这个懒惰的家伙,在网上疯狂的搜集搜索架构方面的东西,因为做做架构,暂时没写代码,每天就看人家博客,结果两个星期了才弄了个大概的草图,这不清明节过后就要详细方案了,现在只能把我的草图分享一下,希望大家板砖伺候,闷在家里鼓捣比较郁闷啊,效率太低。

全文搜索Lucene.Net优化
像www.verycd.com、博客园、淘宝、京东都有实现站内搜索功能,站内搜索无论在性能和用户体验上都非常不错,本节,通过使用Lucene.Net来实现站内搜索。 演示效果预览如下图10-22~10-24所示。 图10-22 图10-23 图10-24 在10.4节,已经完成了搜索的第一个版本,但是还有许多地方需要优化。比如说,我要统计关键词搜索的频率

Lucene随笔-BoomFilter布隆过滤器
lucene:6.5.1 简介 在luncene中布隆过滤器主要保存在.blm文件中,主要是用来判断特定的内容是否存在,比如在写入时判断文档id是否存在。此外,布隆过滤器只能判断特定内容肯定不存在,而不能得出肯定存在的结论。 实现 在luncene中不BloomFilter的具体实现主要是在FuzzySet。其入口为DefaultBloomFilterFactory,这里可以通过ge
Lucene随笔-LogMergePolicy
lucene版本:6.5.4 当IW索引中的数据发生任何变化时,都会触发merge检测,即找出可以合并的merge的segment集合;并且判断是否需要合并,如果需要合并则返回一组OneMerge,一个OneMerge对应的时一个Segment。**那么如何取获取那些需要合并的段集合呢?**这就是我们本节所要讲的。在Lucene4版本前,其默认的MergePolicy为LogMergePo
Lucene随笔-ThreadState
Lucene 6.5.4 ThreadState在lucene的curd扮演者非常重要的角色。首先,DocumentsWriterPerThreadPool是一个逻辑上的线程池,它实现了类似Java线程池的功能, 在Java的线程池中,新来的一个任务可以从ExecutorService中获得一个线程去处理该任务,而在DocumentsWriterPerThreadPool中,每当Index
Lucene随笔-记录一下自动flush的触发条件
Luncene 6.5.1 在lucene中flush存在两种flush:主动flush与自动flush。那么在哪些情况下会触发自动flush呢? MaxBufferedDocs MaxBufferedDocs描述了索引信息被写入到磁盘前暂时缓存在内存中允许的文档最大数量,也就是每个DWPT缓存的最大文档数量,当一个DWPT中的文档数量超过这个值时会触发自动flush,该参数在建立In
Lucene随笔-聊聊IndexWriter
Lucene版本:6.5.1 Package: org.apache.lucene.index; IndexWriter示例 这里以"hello world"的索引过程为例,探究以下IndexWriter的原理: doc1:索引文件。path: 索引相关的文件所存放的文件夹位置。 IndexWriter的大致过程如下: 首先创建IndexWriter。创建需要索引的文档。通过Ind

lucene的默认评分算法-向量空间模型(Vector Space Model)
在lucene4以前,一直都是使用经典的向量空间模型作为其检索模型,这种方式虽然统一了评分算法,简化了计算,但是带来的问题是很难去调整,一旦向量空间模型不适合,也很难去替换一种更好的算法。 而lucene4则将检索模型与事实上的搜索做了解耦和抽象,并且加入了另外几种检索模型的实现,其中就有经典的BM25。 经典的向量空间模型的理论基础及其在lucene中的应用 向量空间模型

Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1、什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug Cutting 开发,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的库,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为
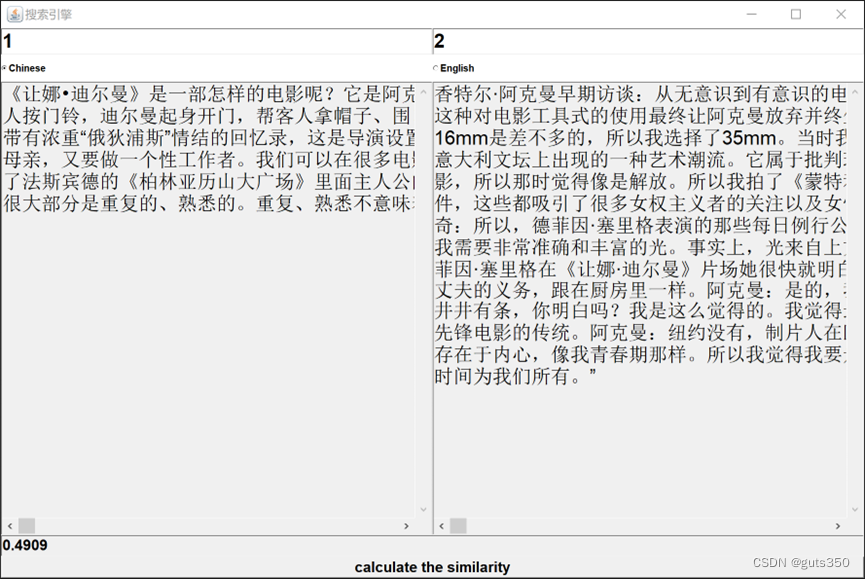
【java、lucene、python】互联网搜索引擎课程报告二:建立搜索引擎
一、项目要求 建立并实现文本搜索功能 对经过预处理后的500个英文和中文文档/网页建立搜索并实现搜索功能对文档建立索引,然后通过前台界面或者已提供的界面,输入关键字,展示搜索结果前台可通过网页形式、应用程序形式、或者利用已有的界面工具显示实现英文搜索及中文搜索功能 比较文档之间的相似度 通过余弦距离计算任意两个文档之间的相似度,列出文档原文,并给出相似 度值。 对下载的文档,利用K-M

Lucene、Compass学习以及与SSH的整合
本文转载自:http://blog.csdn.net/ygj26/article/details/5552059 一、准备 个人在学习中采用Struts2 + Hibernate3.2 + Spring2.5 + Compass2.2.0, 一下图片为本次学习中用到的jar包: 图中圈出的jar包为本次学习的主要部分,另外用绿色框圈出的jar包为分词器,主要用来做实
lucene4.5源码分析系列:lucene的默认评分算法-向量空间模型(Vector Space Model)
在lucene4以前,一直都是使用经典的向量空间模型作为其检索模型,这种方式虽然统一了评分算法,简化了计算,但是带来的问题是很难去调整,一旦向量空间模型不适合,也很难去替换一种更好的算法。 而lucene4则将检索模型与事实上的搜索做了解耦和抽象,并且加入了另外几种检索模型的实现,其中就有经典的BM25。 经典的向量空间模型的理论基础及其在lucene中的应用 向量空间模型是信息
solr 错误:Caused by: org.wltea.analyzer.lucene.IKAnalyzer
一、 问题描述 CDH5.15.2的solr集群下,创建ik分词器的实例,但是报错。Ik分词器的配置文件都已经上传各个节点solr对应目录下,但是还是报错: solrctl collection --create test_ik4 -s 2 -c test_ik -r 1 -m 3报错<?xml version="1.0" encoding="UTF-8"?> <response> <
Lucene暴走之巧用内存倒排索引高效识别垃圾数据
[size=medium] 识别垃圾数据,在一些大数据项目中的ETL清洗时,非常常见,比如通过关键词 (1)过滤垃圾邮件 (2)识别yellow网站 (3)筛选海量简历招聘信息 (4)智能机器人问答测试 ........ 各个公司的业务规则都不一样,那么识别的算法和算法也不一样,这里提供一种思路,来高效快速的根据关键词规则识别垃圾数据。 下面看下需求: 业务定义一些主关键

Lucene/Solr/ElasticSearch搜索问题案例分析
最近收集的两个搜索的case,如下: 案例一: 使用 A关键词:“中国诚通控股公司”搜索,不能搜到 B结果“中国诚通控股集团有限公司” 从关键词字面上看,确实不应该出现这种问题,因为A的关键词完全被B包含,如果说搜索B,搜不到A到还可以接受,因为 在关键词越长的情况下,term之间是AND的关系,这样返回结果集就越少,这一点从Google或者其他电商的搜索都可以得