本文主要是介绍Lucene随笔-BoomFilter布隆过滤器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
lucene:6.5.1
简介
在luncene中布隆过滤器主要保存在.blm文件中,主要是用来判断特定的内容是否存在,比如在写入时判断文档id是否存在。此外,布隆过滤器只能判断特定内容肯定不存在,而不能得出肯定存在的结论。
实现
在luncene中不BloomFilter的具体实现主要是在FuzzySet。其入口为DefaultBloomFilterFactory,这里可以通过getSetForField函数获取一个布隆过滤器。这里的两个参数分别为
maxNumUniqueValues:可能存在的最大不同值的数量
desiredMaxSaturation: 包和度,接下来会具体介绍,默认为0.1
public FuzzySet getSetForField(SegmentWriteState state,FieldInfo info) {//Assume all of the docs have a unique term (e.g. a primary key) and we hope to maintain a set with 10% of bits setreturn FuzzySet.createSetBasedOnQuality(state.segmentInfo.maxDoc(), 0.10f);}
在FuzzySet.java中首先会根据输入的segment中的文档个数以及饱和度估算出一个set的容量。
public static FuzzySet createSetBasedOnQuality(int maxNumUniqueValues, float desiredMaxSaturation){int setSize=getNearestSetSize(maxNumUniqueValues,desiredMaxSaturation);return new FuzzySet(new FixedBitSet(setSize+1),setSize, hashFunctionForVersion(VERSION_CURRENT));}
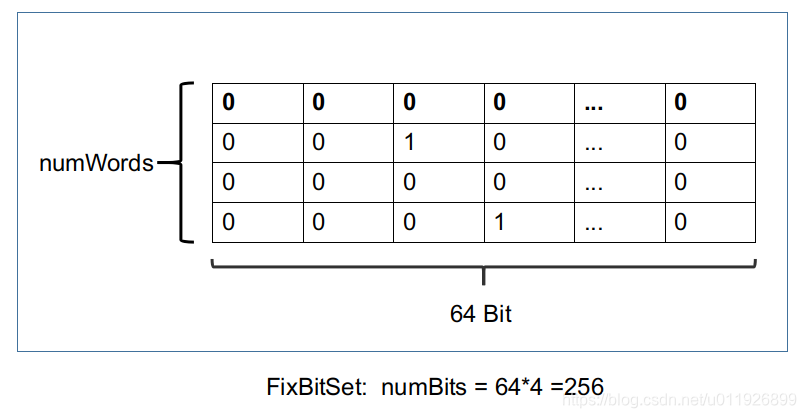
这里的FixBitSet是一个在lucene中非常重要的数据结构。它的其中一个用途用来存储文档号,用一个bit位来描述(存储)一个文档号。该类特别适合存储连续并且没有重复的int类型的数值。最好情况可以用8个字节来描述64个int类型的值。其结构如下,我们首先探究以下FixBitset的实现原理
private final long[] bits; // Array of longs holding the bits private final int numBits; // The number of bits in useprivate final int numWords; // The exact number of longs needed to hold numBits (<= bits.length)
bit:存储bit的数组
numBits:参数numBits用来确定需要多少bit位来存储我们的int数值。如果我们另numBits的值为300,实际会分配一个64的整数倍的bit位。因为比300大的第一个64的倍数是 320 (64 * 5),所以实际上我们可以存储 [0 ~319]范围的数值。
numWords:表示bit数组的容量,即需要numWords的long值存储numsBit的数组
在FixBit中给我们提供了两个基本的操作函数:读取与写入
public boolean get(int index) {assert index >= 0 && index < numBits: "index=" + index + ", numBits=" + numBits;int i = index >> 6; // div 64// signed shift will keep a negative index and force an// array-index-out-of-bounds-exception, removing the need for an explicit check.long bitmask = 1L << index;return (bits[i] & bitmask) != 0;}public void set(int index) {assert index >= 0 && index < numBits: "index=" + index + ", numBits=" + numBits;int wordNum = index >> 6; // div 64long bitmask = 1L << index;bits[wordNum] |= bitmask;}
此外BitSet还提供了用户不同BitSet之间的交并集操作。
然后我们接下来看一下FuzzySet中的插入和查询操作。
public void addValue(BytesRef value) throws IOException { int hash = hashFunction.hash(value);if (hash < 0) {hash = hash * -1;}// Bitmasking using bloomSize is effectively a modulo operation.// 取模 (正数与取余一样,负数)int bloomPos = hash & bloomSize;filter.set(bloomPos);}
- 通过MurMurHash2生成一个int的Hash编码
- 对BloomSize(预设的文档的数量)进行取余操作
- filter调用add方法添加value
整体的数据流转如下:

存在的问题
生命周期
目前es主要在uid上字段上维护布隆过滤器,主要用于判定文档是否存在:
- 数据写入时:判断是否存在
- 数据查询时:判断id文档是否存在
创建时期:构建IndexReader时,从b1m文件中加载bit数组到内存
回收时期:在IndexReader.close内存的bit数组进行gc回收
merge:因为每个seg的bit信息时独立的因此在merge时,会读取bit信息并进行merge
对GC的影响
实验表明1亿的文档通常情况下会占用120mb左右的内存,同时会对GC产生如下影响:
- 小文件产生的内存碎片
- 大文件触发GC
这篇关于Lucene随笔-BoomFilter布隆过滤器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





