布隆专题

Redis中使用布隆过滤器解决缓存穿透问题
一、缓存穿透(失效)问题 缓存穿透是指查询一个一定不存在的数据,由于缓存中没有命中,会去数据库中查询,而数据库中也没有该数据,并且每次查询都不会命中缓存,从而每次请求都直接打到了数据库上,这会给数据库带来巨大压力。 二、布隆过滤器原理 布隆过滤器(Bloom Filter)是一种空间效率很高的随机数据结构,它利用多个不同的哈希函数将一个元素映射到一个位数组中的多个位置,并将这些位置的值置

布隆过滤器的详解与应用
一、什么是Bloom Filter Bloom Filter是一种空间效率很高的随机数据结构,它的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。这就是布隆过滤器的基本思

Flink实例(六十八):布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上在网络爬虫里,一个网址是否被访问过yahoo, gmail等邮箱垃圾邮件过滤功能 这几个例子有一个共同的特点: 如何判断一个元素是否存在一个集合中? 常规思路 数组链表树、平衡二叉树、TrieMap (红黑树)哈希表 虽然上面描述的

吃透Redis系列(四):布隆(bloom)过滤器详细介绍
Redis系列文章: 吃透Redis系列(一):Linux下Redis安装 吃透Redis系列(二):Redis六大数据类型详细用法 吃透Redis系列(三):Redis管道,发布/订阅,事物,过期时间 详细介绍 吃透Redis系列(四):布隆(bloom)过滤器详细介绍 吃透Redis系列(五):RDB和AOF持久化详细介绍 吃透Redis系列(六):主从复制详细介绍 吃透Redi

143.布隆过滤器原理以及Go使用示例
文章目录 1. 是什么?2. 干什么?3. 为什么?4. 有什么问题?5. Go使用布隆过滤器单机版(Golang)分布式版(Java) 1. 是什么? 它是一个二进制bit数组,初始为 0 采用位存储数据结构,节省存储空间 1 存在,0 不存在 可以添加,但是不能删除 存在误判 2. 干什么? 用于快速查找一个集合中是否存在某个元素。尤其是大数据量中快速查找

【C++杂货铺】海量数据处理(位图、布隆过滤器)
目录 🌈前言🌈 📁 位图 📂 概念 📂 模拟实现 📂 C++中位图 📂 位图的优缺点 📁 布隆过滤器 📂 概念 📂 模拟实现 📂 应用场景 📁 海量数据处理 📁 总结 🌈前言🌈 本期【C++杂货铺】,将介绍关于哈希表的扩展内容,即位图和布隆过滤器,以及如何通过位图和布隆过滤器解决海量数据处理问题。

springboot集成guava布隆过滤器
1.创建springboot项目,引入maven依赖 <dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version></dependency> 2.创建guava布隆过滤器 @Componentpublic class GuavaFilter {/

springboot+redis+mybatis体会布隆过滤器
1.建立数据库表和对应实体类 CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT,`uname` varchar(50) DEFAULT NULL,`usex` varchar(20) DEFAULT NULL,`uage` int(11) DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE)

位图与布隆过滤器 —— 海量数据处理
🌈 个人主页:Zfox_ 🔥 系列专栏:C++从入门到精通 目录 🚀 位图 一: 🔥 位图概念 二: 🔥 位图的实现思路及代码实现三: 🔥 位图的应用四: 🔥 STL中的 bitset 🚀 布隆过滤器 一: 🔥 布隆过滤器提出 二: 🔥 布隆过滤器概念 三: 🔥 布隆过滤器的误判率推导四: 🔥 布隆过滤器的实现五: 🔥 布隆过滤器的删除六: 🔥 布

Lucene随笔-BoomFilter布隆过滤器
lucene:6.5.1 简介 在luncene中布隆过滤器主要保存在.blm文件中,主要是用来判断特定的内容是否存在,比如在写入时判断文档id是否存在。此外,布隆过滤器只能判断特定内容肯定不存在,而不能得出肯定存在的结论。 实现 在luncene中不BloomFilter的具体实现主要是在FuzzySet。其入口为DefaultBloomFilterFactory,这里可以通过ge
布隆过滤器,我也是个处理过十几亿数据的人儿
文章收录在 GitHub JavaKeeper ,N线互联网开发必备技能兵器谱 什么是 BloomFilter 布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。 通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较
redis从入门到进阶——数据类型、 操作、数值操作、发布订阅、消息队列、布隆过滤器、事务
文章目录 基础数据类型操作数值操作 进阶发布订阅消息队列布隆过滤器事务 基础 数据类型 string,set, hash, list, zset 操作 string符串类型: 保存一个字符串:set key value [EX seconds|PX milliseconds...] [NX|XX]EX:设置存活时间,秒为单位PX:设置存活时间,毫秒为单位NX:如果key
2019.08.23日记,通过布隆过滤器,统计渠道的UV
一般情况下,我们统计一个渠道的UV都是先通过select ,然后再插入。 但是我们知道这种方式本身性能效率不高,原因是mysql 的性能决定的。 再上UV这种东西本身的数据量就是会比较大的。那么如果解决了? 参考:https://www.cnblogs.com/liliuguang/p/11112694.html 跟据这个链接的想法,我们可以把查询放到程序去解决,插入交给数据库,这样子的话
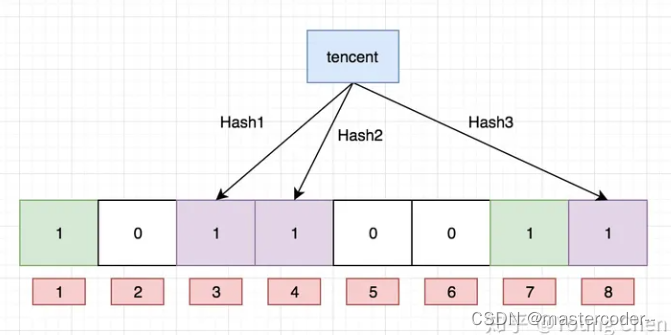
哈希应用——布隆过滤器
布隆过滤器的提出 场景一:在注册账号设置昵称的时候,为了保证每个用户昵称的唯一性,系统必须检测你输入的昵称是否被使用过,这本质就是一个key的模型,我们只需要判断这个昵称被用过,还是没被用过。 场景二:我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时都要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推荐去重的?用服务器记录了用户看过的所有历史

哈希重要思想续——布隆过滤器
布隆过滤器 一 概念1.1布隆过滤器的提出2.概念 二 模拟实现2.1 三个仿函数setTest 全代码三 实际应用 一 概念 1.1布隆过滤器的提出 我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历
详解布隆过滤器,实现分布式布隆过滤器
什么是布隆过滤器? 原理 布隆过滤器是一种基于位数组(bit array)和多个哈希函数的数据结构。其核心原理是: 初始化一个长度为m的位数组,所有位初始化为0。使用k个不同的哈希函数将元素映射到位数组中的k个位置。当插入一个元素时,使用k个哈希函数计算该元素的k个哈希值,并将位数组中对应位置的值设为1。当查询一个元素是否存在时,使用同样的k个哈希函数计算该元素的k个哈希值,并检查位数组中对
Redis 布隆过滤器实战「缓存击穿、雪崩效应」
Java高级互联网架构 2019-03-22 13:52:38 为什么引入 我们的业务中经常会遇到穿库的问题,通常可以通过缓存解决。 如果数据维度比较多,结果数据集合比较大时,缓存的效果就不明显了。 因此为了解决穿库的问题,我们引入Bloom Filter。 我们先看看一般业务缓存流程: 先查询缓存,缓存不命中再查询数据库。 然后将查询结果放在缓存中即使数据不存在,也需要创建一个
从原理到实战:如何通过布隆过滤器防止缓存击穿
java互联网架构 2020-03-07 15:18:48 为什么引入 我们的业务中经常会遇到穿库的问题,通常可以通过缓存解决。如果数据维度比较多,结果数据集合比较大时,缓存的效果就不明显了。 因此为了解决穿库的问题,我们引入Bloom Filter。 适合的场景 数据库防止穿库 Google Bigtable,Apache HBase和Apache Cassandra以及Postgre
详解布隆过滤器的原理,使用场景和注意事项
什么是布隆过滤器 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。 实现原理 HashMap 的问题 讲述布隆过滤器的
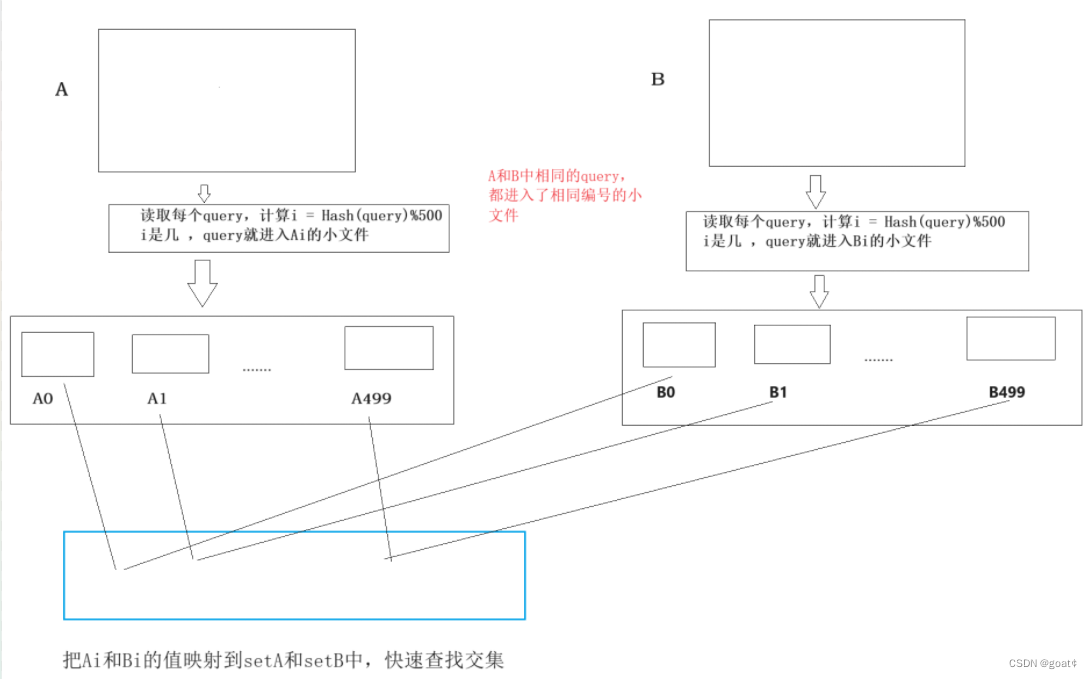
【C++ ——— 哈希】位图 | 布隆过滤器
文章目录 1、位图1.1位图概念 2.位图实现位图的应用1.一百亿个整数,设计算法找到只出现一次的整数?2.给两个文件,分别有一百亿个整数,我们只有1G内存该如何找到两个文件的交集?3.位图应用变形:一个文件有100亿个int,1G内存,设计算法找到出现不超过两次的所有整数。 3.布隆过滤器3.1 布隆过滤器的提出3.2布隆过滤器概念 海量数据的面试题1.给两个文件,分别由100亿个
Spring Boot(七十四):集成Guava 库实现布隆过滤器(Bloom Filter)
之前在redis(17):什么是布隆过滤器?如何实现布隆过滤器?中介绍了布隆过滤器,以及原理,布隆过滤器有很多实现和优化,由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标 1 引入依赖 <dependency><groupId>com
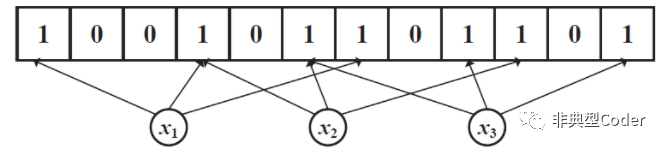
Redis缓存穿透解决方案—布隆过滤器
概念 Bloom Filter(以下简称 BF)是一个空间高效率的概率型数据结构,用来确定一个元素是否是集合中一员。 空间高效是指数据存储使用了 bit 的方式,相对来说比较紧凑,空间利用率较高。 概率型是指查询时返回两种结果:“一定不在” 和 “可能在”。 原理 本质就是bit 数组,初始化每个 bit 都是 0,添加一个元素时, 会使用 n 个 hash 函数计算出 n 个 值,
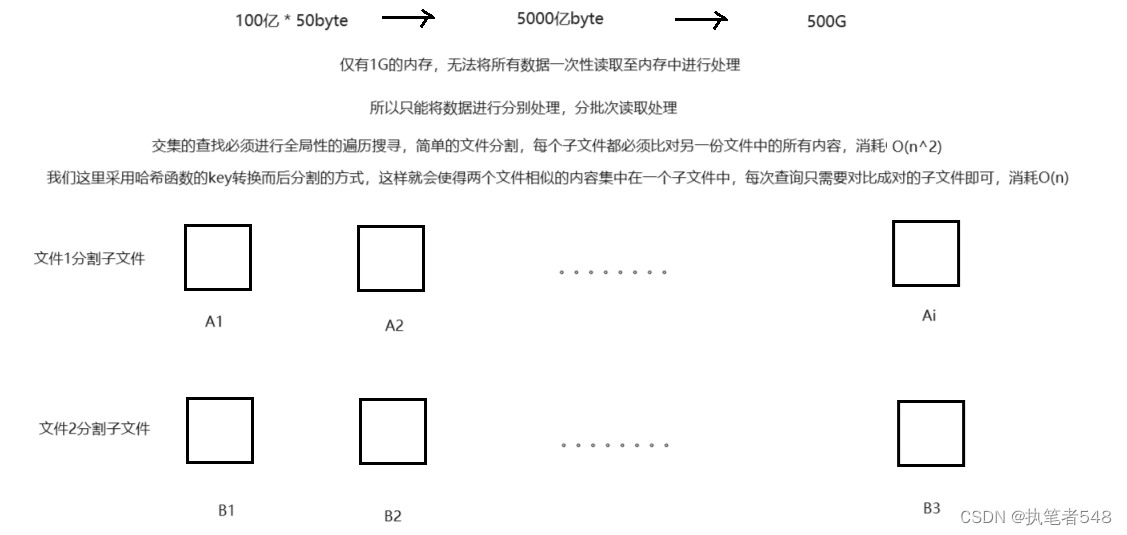
C++进阶:哈希(2)位图与布隆过滤器
目录 1. 位图(bitset)1.1 引子:海量整形数据的处理1.2 结构描述1.3 位图实现1.4 位图相关题目练习 2. 布隆过滤器(BloomFilter)2.1 引子:海量非int类型数据处理(string)2.2 结构描述3.3 布隆过滤器的实现3.4 相关练习 1. 位图(bitset) 1.1 引子:海量整形数据的处理 背景问题:40亿个无序的无符号整数,如

布隆过滤器(Bloom Filter)基础知识
布隆过滤器(Bloom Filter)基础知识 布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种space efficient的概率型数据结构,用于判断一个元素是否在集合中。在网页黑名单系统、垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希

速了解及使用布隆过滤器
布隆过滤器 介绍 概念:是一种高效查询的数据结构 作用:判断某个元素是否在一个集合中。(但是会出现误判的情况) 实现原理 加入元素: 当一个元素需要加入到布隆过滤器中时,会使用一组哈希函数对该元素进行计算,得到多个哈希值。 每个哈希值对应到位数组的一个特定位置,将这些位置的值设置为1。 查询元素: 对给定的元素再次进行相同的哈希计算,得到一组哈希值。 检查位数组中
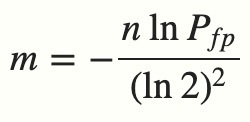
5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有!
在程序的世界中,布隆过滤器是程序员的一把利器,利用它可以快速地解决项目中一些比较棘手的问题。如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有