本文主要是介绍C++进阶:哈希(2)位图与布隆过滤器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 位图(bitset)
- 1.1 引子:海量整形数据的处理
- 1.2 结构描述
- 1.3 位图实现
- 1.4 位图相关题目练习
- 2. 布隆过滤器(BloomFilter)
- 2.1 引子:海量非int类型数据处理(string)
- 2.2 结构描述
- 3.3 布隆过滤器的实现
- 3.4 相关练习
1. 位图(bitset)
1.1 引子:海量整形数据的处理
- 背景问题:40亿个无序的无符号整数,如何快速判断一个无符号整形是否存在?
- 当我们进行大量数据处理时,内存不足以一次性将全部数据读取处理,我们应该如何解决,接下来,我们就来进行相关的学习。
1.2 结构描述
- 当数据量较小时,内存能够一次性读取所有数据:
<1> 排序 + 二分查找
<2> set + find- 当数据量过大,内存无法一次性读取并处理所有数据,在只需要查找的背景下,我们能否将相关数据状态信息进行压缩,使得内存存储的代价大大降低呢?
- 计算机中,可以标识数据状态的最小单位为bit位,而在数据只有整形的情况下,可以直接将每个数字映射一一对应的bit位,物理上,通过开辟一段指定连续内存空间来映射存储,即位级别的哈希表,我们称之为位图。
- 位图的方式,可以大大较少需要消耗的内存空间,约42亿整形数据范围经过转换仅需大小512的内存空间。
- 开辟空间空间时,我们无法以bit位为单位进行开辟,但可以通过计算机内置类型来间接申请开辟,下面的具体实现我们采用int类型。

1.3 位图实现
- 位图结构
//int类型数据
//unsigned_int类型最大数据范围:UINT_MAN,-1,0x0ffffffff
template<size_t N>//非类型模板参数确定需开辟bit位数量
class bit_set
{
public://构造bit_set(){//N为bit位数量,转换为整形需除32换算//仅除32开辟不够_data.resize(N / 32 + 1, 0);}//bit位置1,非类型模板参数定义的类,类型不带模板参数void set(size_t pos);//bit位置0void reset(size_t pos);//测试某个bit位的状态bool test(size_t pos);private:vector<int> _data;//vector内为动态数组
};- 操作实现
//bit位置1
void set(size_t pos)
{assert(pos <= N);size_t hashi = 1;//第几个数组元素int i = pos / 32;//哪一个bit位int j = pos % 32;//大端机与小端机的数据存储方式不同//但位左移右移的操作并不会因此受影响//编程语言中的左移右移概念,指的是向计算机的高位,低位移动hashi <<= j;_data[i] |= hashi;
}//bit位置0
void reset(size_t pos)
{assert(pos <= N);size_t hashi = 1;int i = pos / 32;int j = pos % 32;hashi = ~(hashi << j);_data[i] &= hashi;
}//测试某个bit为的状态
bool test(size_t pos)
{assert(pos <= N);size_t hashi = 1;int i = pos / 32;int j = pos % 32;hashi <<= j;hashi &= _data[i];return hashi;
}
1.4 位图相关题目练习
- 100亿个int类型的数据,查找其中只出现一次的数据
答:使用两个位图嵌套封装的方式,实现可以使用两个bit位表示多种状态的数据结构,从而来完成筛选。
template<size_t N>
class two_bit_set
{
public://置1void set(size_t pos){if (a.test(pos) == 0 && b.test(pos) == 0)//一次{//0b.set(pos);//1}else if(a.test(pos) == 0 && b.test(pos) == 1)//两次{a.set(pos);//1b.reset(pos);//0}else//三次以上{a.set(pos);//1b.set(pos);//1}}//置0void reset(size_t pos){a.reset(pos);b.reset(pos);}size_t test(size_t pos){if (a.test(pos) == 0 && b.test(pos) == 0){return 0;}else if (a.test(pos) == 0 && b.test(pos) == 1){return 1;}else{return 2;}}private:bit_set<N> a;bit_set<N> b;
};
- 现有两个文件,其中分别有100亿个int类型的数据,现内存大小为1G,如何找到两个文件的交集
答: 将两个文件中的数据分别set入两个位图当中,然后同步遍历两个位图,查找交集
补充:当数据量较小时,可以使用set容器,去重后,使用去重算法遍历
- 现有一个文件,其中有着100亿个int类型的数据,现内存大小为1G,如何找出重复次数不超过两次的数据
答:位图映射,多个bitset嵌套,表示多种状态
- 现有一个文件,有着100亿个int类型的数据,内存大小为512MB,如何找到只出现一次的所有数据
答:因为内存空间相对来说严重不足,我们无法一次性创建出映射包括所有int范围的位图,所以,我们只能较少位图的大小,将数据切分,分批次处理,一次只处理一定数据范围内的数据。

2. 布隆过滤器(BloomFilter)
2.1 引子:海量非int类型数据处理(string)
- 问题背景: 当存在大量非int类型的数据,诸如,string,内存空间无法容纳处理,有因为非整形数据,也无法直接使用位图映射时,我们该如何对其中的相应数据进行查询
2.2 结构描述
- 在之前的学习中,我们学习与简单实现了哈希表这一数据结构,在key映射的操作上,其中对于非int类型数据的处理,采用了哈希函数转换,将非int类型数据转换为int类型,而后再进行映射。
- 对于大量非int类型数据的处理,我们也采用哈希函数的方式,转换key值将其存储在位图当中,进行数据信息的压缩,但由于并非1:1直接映射,同时数据量又非常大,所以此种哈希函数的映射方式很大可能存在着误判(将原本不存在的数据,判断为存在)。
- 因为哈希函数key值映射的不稳定性,key值大概率可能发生越界情况,所以,对此的处理采用key值越界回绕映射的方式。
- 因为存在误判的可能,当只有单个哈希函数时,这种误判的概率是极高的,所以,我们一般采用多个哈希函数共同映射。
- 经过查阅资料,得到如下一个的插入数据个数与位图开辟空间大小之间的数学公式,而位图开辟的空间越大,key值得误判率越低。

- 此种非int类型,多哈希函数位图映射的数据结构,我们就称之为布隆过滤器(BloomFilter)
- 因为多哈希函数共同映射,每个数据得key值之间可能存在交集,所以布隆过滤器不支持置0删除key值的操作。

3.3 布隆过滤器的实现
- 哈希函数
//BKDR
struct HashBKDR
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 131;hash += ch;}return hash;}
};//AP
struct HashAP
{size_t operator()(const string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶数位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇数位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));}}return hash;}
};//DJB
struct HashDJB
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};
- 具体实现
//非类型模板参数声明先于模板参数
template<size_t M, class K = string, class HashFunc1 = HashBKDR, class HashFunc2 = HashAP, class HashFunc3 = HashDJB>
class BloomFilter
{
public://添加void set(K key){//key值可能越界,需进行回绕size_t key1 = hs1(key) % N;size_t key2 = hs2(key) % N;size_t key3 = hs3(key) % N;bs.set(key1);bs.set(key2);bs.set(key3);}//布隆过滤器不支持删除,可能会同时影响其他值//查询bool test(K key){//匿名对象size_t key1 = HashFunc1()(key) % N;size_t key2 = HashFunc2()(key) % N;size_t key3 = HashFunc3()(key) % N;//存在有误判,不存在无误判if (bs.test(key1) == false)return false;if (bs.test(key2) == false)return false;if (bs.test(key3) == false)return false;return true;}private://非类型模板参数必须是整形家族,且为const修饰static const size_t N = 8 * M;//计算公式,M为插入数据个数,N为开辟空间大小bit_set<N> bs;HashFunc1 hs1;HashFunc2 hs2;HashFunc3 hs3;
};
3.4 相关练习
- 两个文件分别有100亿个query(查询请求,可以简单理解为字符串,一个query的大小为50byte),现只有1G内存
<1> 如何大致找出两个文件的交集
<2> 如何精确找出两个文件的交集
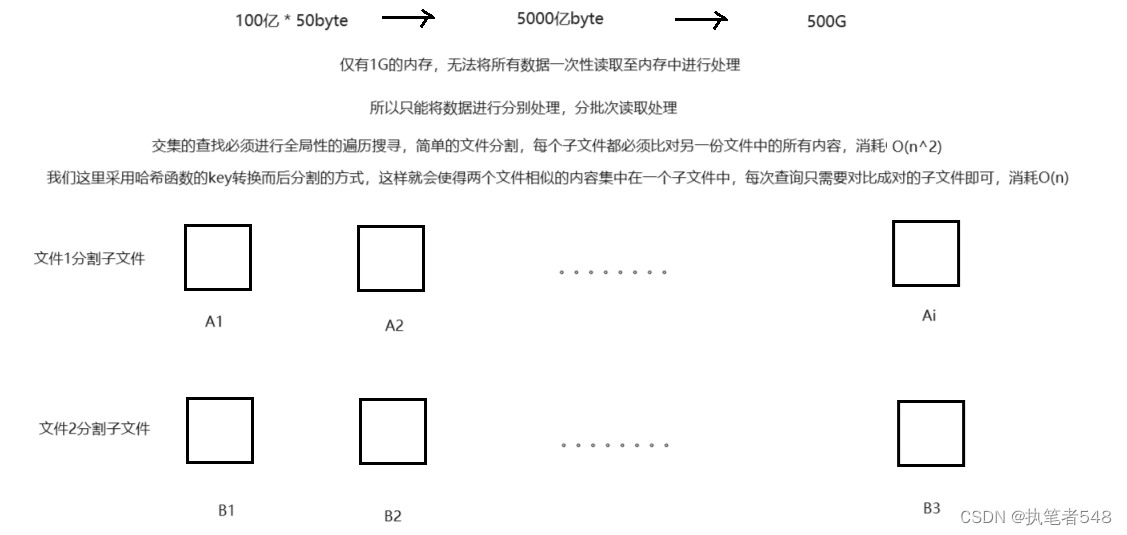
- 答:
<1> 将文件至内存足够一次性容纳的大小,分批次读取
<2> 但哈希切分的方式,并非是按照文件大小来切分,所以导致文件的大小存在不确定性
<3> 当文件存在有较多相似,相同内容时,哈希切分后还会存在大型文件,内存仍无法容纳
<4> 位图具有自动去重的特性,当出现大型子文件时,我们可以现进行内容读取,当读取过程中出现异常,那么,就证明文件体积过大的原因并非相同内容堆积所引起,此时,我们只需要再切换另一种哈希函数来进行切分文件,重复上述步骤即可
这篇关于C++进阶:哈希(2)位图与布隆过滤器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



