本文主要是介绍(2016 弱校联盟十一专场10.3) Similarity of Subtrees DFS + hash,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目链接
https://acm.bnu.edu.cn/v3/problem_show.php?pid=52310
problem description
Define the depth of a node in a rooted tree by applying the following rules recursively:
• The depth of a root node is 0.
• The depths of child nodes whose parents are with depth d are d + 1.
Let S(T, d) be the number of nodes of T with depth d. Two rooted trees T and T ′ are similar if and only if S(T, d) equals S(T ′ , d) for all non-negative integer d. You are given a rooted tree T with N nodes. The nodes of T are numbered from 1 to N. Node 1 is the root node of T. Let Ti be the rooted subtree of T whose root is node i. Your task is to write a program which calculates the number of pairs (i, j) such that Ti and Tj are similar and i < j.
Input
The input consists of a single test case. N a1 b1 … aN−1 bN−1 The first line contains an integer N (1 ≤ N ≤ 100,000), which is the number of nodes in a tree. The following N − 1 lines give information of branches: the i-th line of them contains ai and bi , which indicates that a node ai is a parent of a node bi . (1 ≤ ai , bi ≤ N, ai ?= bi) The root node is numbered by 1. It is guaranteed that a given graph is a rooted tree, i.e. there is exactly one parent for each node except the node 1, and the graph is connected.
Output
Print the number of the pairs (x, y) of the nodes such that the subtree with the root x and the subtree with the root y are similar and x < y.
Sample Input1
5
1 2
1 3
1 4
1 5
Output for the Sample Input 1
6
Sample Input2
6
1 2
2 3
3 4
1 5
5 6
Output for the Sample Input 2
2
Sample Input3
13
1 2
1 3
2 4
2 5
3 6
3 7
4 8
4 9
6 10
7 11
8 12
11 13
Output for the Sample Input 3
14
题意:
输入一棵由n个点和n-1条边构成的树,求这个树中两棵相似的子树有多少对? 相似的子树:要求在相同的深度,两颗子树的在这一层的节点数相同;
分析:
要找出所有的相似的子树,n<=100000,所以我们不可能两两比较。但是我们可以表示出所有子树,然后在计算结果就可以了。
思路:深搜,hash表示每一个点为子树时的子树状态;
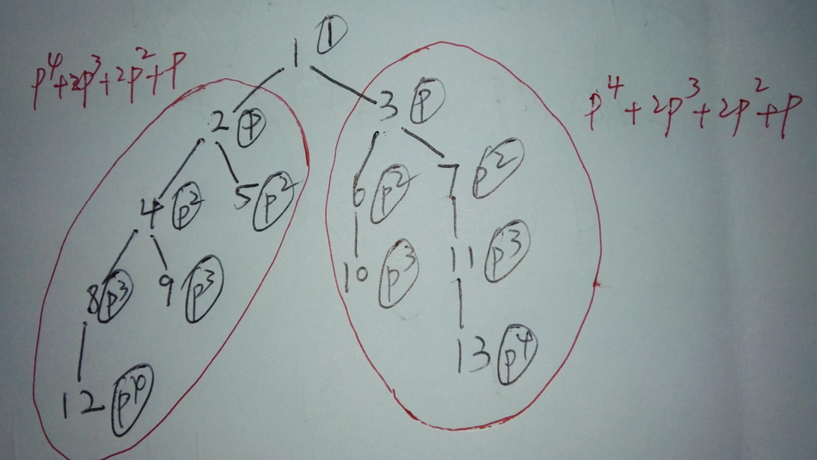
第三组样例:对图上每个点,给一个标识p^d d为这个点的深度,那么每个点的子树状态就可以用子树上所有项的和表示,如2号节点p^4+2p^3+2p^2+p 3号节点p^4+2p^3+2p^2+p 它们的多项式相同,为了方便用map映射统计,可以给p赋一个值,为了减小冲突可以取一个较大的质数,这就是hash;
AC代码:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <map>
#include <cmath>
#include <vector>
using namespace std;
typedef long long LL;
const LL maxn = 1e6+10,p=9901,mod=1e9+7;
vector<LL> G[maxn];
LL hash_v[maxn];
map<LL,LL> mp;
map<LL,LL>:: iterator it;void dfs(LL u)
{hash_v[u] = 1;for(LL i=0;i<G[u].size();i++){LL v = G[u][i];dfs(v);hash_v[u] = (hash_v[u] + hash_v[v]*p)%mod;}mp[hash_v[u]]++;
}int main()
{LL n,u,v;while(scanf("%lld",&n)!=EOF){for(LL i=0;i<=n;i++) G[i].clear();mp.clear();for(LL i=1;i<n;i++){scanf("%lld%lld",&u,&v);G[u].push_back(v);}dfs(1);LL ans = 0;for(it=mp.begin();it!=mp.end();it++)ans += it->second*(it->second-1)/2;printf("%lld\n",ans);}return 0;
}
这篇关于(2016 弱校联盟十一专场10.3) Similarity of Subtrees DFS + hash的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



