本文主要是介绍KL散度 kl divergence,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
KL散度也叫KL距离 也叫相对熵 relative entropy。是描述两个概率分布P和Q差异的一种方法。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
离散随机变量的两个概率分布P、Q的KL散度定义为:
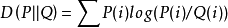
连续随机变量P,Q的KL散度定义为:

所以KL散度始终是大于等于0的,两个分布越接近散度越小(趋近于0)反之越大,当且仅当两分布相同时,KL散度等于0。
KL散度是不对称的,当然,如果希望把它变对称,可以使用如下方法
Ds(p1, p2) = [D(p1, p2) + D(p2, p1)] / 2
这篇关于KL散度 kl divergence的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!