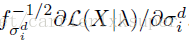本文主要是介绍Fisher散度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Fisher散度(Fisher Divergence)是概率分布相似性或差异性的一种量度,它基于概率分布的对数似然函数的一阶导数(梯度)。Fisher散度是用来量化一个概率分布在参数空间的局部变化情况的,它是Fisher信息矩阵的一部分。
更具体地说,Fisher散度是指概率模型中,真实数据分布 p ( x ) p(x) p(x) 和模型分布 q θ ( x ) q_{\theta}(x) qθ(x)之间的差异,它可以定义为真实分布 p ( x ) p(x) p(x) 下,模型分布 q θ ( x ) q_{\theta}(x) qθ(x) 对数似然梯度的方差:
J ( θ ) = E x ∼ p ( x ) [ ( ▽ θ log q θ ( x ) ) 2 ] J(\theta) = \mathbb{E}_{x \sim p(x)} \left[ \left( \bigtriangledown_{\theta} \log q_{\theta}(x) \right)^2 \right] J(θ)=Ex∼p(x)[(▽θlogqθ(x))2]
其中, ▽ θ log q θ ( x ) \bigtriangledown_{\theta} \log q_{\theta}(x) ▽θlogqθ(x) 是对数似然函数 log q θ ( x ) \log q_{\theta}(x) logqθ(x) 关于参数 θ \theta θ 的梯度, E x ∼ p ( x ) \mathbb{E}_{x \sim p(x)} Ex∼p(x) 表示相对于真实数据分布 p ( x ) p(x) p(x) 的期望。
Fisher散度的一个重要特性是,如果模型分布 q θ ( x ) q_{\theta}(x) qθ(x) 是真实分布 p ( x ) p(x) p(x) 的准确表示(即两者匹配),则此时的Fisher散度为零。因此,Fisher散度可以作为模型拟合优度的一个指标。
在实践中,由于真实数据分布 p ( x ) p(x) p(x)通常是未知的,Fisher散度很难直接计算。但是,它在理论分析中非常有用,特别是在自然梯度下降和其他基于信息几何学的优化算法中,因为Fisher信息矩阵(Fisher散度的矩阵形式)可以用来调整参数更新的方向和步长,以更自然地通过参数空间移动,从而提高学习效率。
Fisher散度本身是一个比较抽象的概念,它通常不直接用于数据分析的实际操作,但它的概念和衍生工具(如Fisher信息和自然梯度)在机器学习中有广泛的应用。下面通过一个简化的例子来说明Fisher散度的一个概念性应用。
假设我们有一个简单的概率模型,这个模型是一维高斯分布,参数为 θ = ( μ , σ 2 ) \theta = (\mu, \sigma^2) θ=(μ,σ2),即均值和方差。模型的概率密度函数为:
q θ ( x ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) q_\theta(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) qθ(x)=2πσ21exp(−2σ2(x−μ)2)
我们想要评估模型 q θ ( x ) q_\theta(x) qθ(x)在参数 θ \theta θ 附近对数据的拟合度。为此,我们可以计算模型分布关于参数的对数似然函数的梯度,即:
▽ θ log q θ ( x ) = ( ∂ ∂ μ log q θ ( x ) , ∂ ∂ σ 2 log q θ ( x ) ) \bigtriangledown_{\theta} \log q_\theta(x) = \left( \frac{\partial}{\partial \mu} \log q_\theta(x), \frac{\partial}{\partial \sigma^2} \log q_\theta(x) \right) ▽θlogqθ(x)=(∂μ∂logqθ(x),∂σ2∂logqθ(x))
对于高斯分布,这些偏导数具体为:
∂ ∂ μ log q θ ( x ) = x − μ σ 2 \frac{\partial}{\partial \mu} \log q_\theta(x) = \frac{x - \mu}{\sigma^2} ∂μ∂logqθ(x)=σ2x−μ
∂ ∂ σ 2 log q θ ( x ) = ( x − μ ) 2 σ 4 − 1 2 σ 2 \frac{\partial}{\partial \sigma^2} \log q_\theta(x) = \frac{(x-\mu)^2}{\sigma^4} - \frac{1}{2\sigma^2} ∂σ2∂logqθ(x)=σ4(x−μ)2−2σ21
然后,我们可以通过取这些梯度的平方,然后计算这个平方值的期望来计算Fisher散度。在理想情况下,如果我们使用的是真实数据分布 p ( x ) p(x) p(x) 下的样本,这个期望可以写成:
J ( θ ) = E x ∼ p ( x ) [ ( x − μ σ 2 ) 2 ] J(\theta) = \mathbb{E}_{x \sim p(x)} \left[ \left( \frac{x - \mu}{\sigma^2} \right)^2 \right] J(θ)=Ex∼p(x)[(σ2x−μ)2]
J ( θ ) = E x ∼ p ( x ) [ ( ( x − μ ) 2 σ 4 − 1 2 σ 2 ) 2 ] J(\theta) = \mathbb{E}_{x \sim p(x)} \left[ \left( \frac{(x-\mu)^2}{\sigma^4} - \frac{1}{2\sigma^2} \right)^2 \right] J(θ)=Ex∼p(x)[(σ4(x−μ)2−2σ21)2]
如果 q θ ( x ) q_\theta(x) qθ(x) 是 p ( x ) p(x) p(x) 的准确表示,那么 μ \mu μ 和 σ 2 \sigma^2 σ2 应该分别接近 p ( x ) p(x) p(x) 的真实均值和方差。在这种情况下,Fisher散度应该接近零,因为对数似然梯度的方差会非常小。
这个例子虽然简化了Fisher散度的使用,但它展示了如何从理论上评估一个概率分布参数化模型在局部参数变化时与真实数据分布的一致性。在实际应用中,例如在参数优化时,通常会使用Fisher信息矩阵来调整学习算法的更新步骤,以此来实现更高效的参数估计。
这篇关于Fisher散度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!