本文主要是介绍Fisher vector学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文:http://blog.csdn.net/carrierlxksuper/article/details/28151013
最近在看fisher vector的相关知识,fisher vector被广泛应用到了图像的分类,目标识别等领域,特别是结合着BOW model。
模式识别方法可以分为生成方法和判别方法。前者注重对类条件概率密度函数的建模,而后者聚焦于分类。而Fisher核方法同时具有这两种方法的优点[4]。这里fisher 核和fisher vector是不一样的(感觉像是废话),其实在文章[4]中,作者证明了采用Fisher vector+线性分类器可以等价于Fisher 核的分类器。于是引出了我们下面要讲的Fisher vector。有关Fisher 的一些知识可以参考这篇blog :点击打开链接。
Fisher vector本质上是用似然函数的梯度vector来表达一幅图像,这个梯度向量的物理意义就是describes the direction in which parameters should be modified to best fit the data[1,2],说白了就是数据拟合中对参数调优的过程。似然函数是哪里来的呢?这里就涉及到上面所说的生成方法了。对于一幅图像 ,有T个描述子(比如SIFT),那么这幅图像就可以表示为:
,在这里lamda是参数集合
,取对数之后就是:
------------1。
现在需要一组K个高斯分布的线性组合来逼近这些i.i.d.,假设这些高斯混合分布参数也是lamda,于是---------2。在这个式2中Pi表示的就是高斯分布

。
在这里D是特征矢量的维数,协方差矩阵计算的是不用维数之间的关系。在这这里假设协方差矩阵是对角阵也就是feature的不同dim之间是相互独立的。
有了公式1,2,3之后,就可以对公式1求导,然后将偏导数,也就是梯度作为fisher vector了。在此之前再定义一个变量:
,表征的是occupancyprobability,也就是特征xt是由第i个高斯分布生成的概率。
下面的公式给出了偏导计算公式:

值得注意的是上面求出来的都是没有归一化的vector,需要进行归一化操作,正如上一篇blog介绍的那样,由于是在概率空间中,与欧式空间中的归一化不同,引入Fisher matrix进行归一化。
公式4的三个变量分别引入三个对应的归一化需要的fisher matrix:
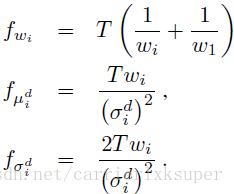
于是最终归一化之后的fisher vector就是:
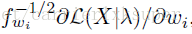
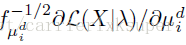
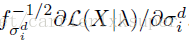
由于每一个特征是d维的,需要K个高斯分布的线性组合,有公式5,一个Fisher vector的维数为(2*d+1)*K-1维。
有了Fisher vector,你就可以做图像分类了。当然,在文章[2,3]中都介绍了对这个Fisher vector的进一步改进,在此不再赘述。
参考文献:
[1] Fisher Kernels on Visual Vocabularies for Image Categorization Florent Perronnin and Christopher Dance. CVPR 2007
[2] Improving the Fisher Kernel for Large-Scale Image Classification. Florent Perronnin, Jorge Sanchez, and Thomas Mensink. ECCV 2010
[3] Image Classification with the Fisher Vector: Theory and Practice. Jorge Sánchez , Florent Perronnin , Thomas Mensink , Jakob Verbeek.
以及更早的一篇:
[4] exploiting generative models in discriminative classification
这篇关于Fisher vector学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







