本文主要是介绍基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)
目录
- 系列文章目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 数据增强
- 3. 普通CNN模型
- 1)模型结构
- 2)模型优化
- 3)模型训练
- 4)模型保存
- 其他相关博客
- 工程源代码下载
- 其它资料下载

前言
本项目以卷积神经网络(CNN)模型为基础,对收集到的猫咪图像数据进行训练。通过采用数据增强技术和结合残差网络的方法,旨在提高模型的性能,以实现对不同猫的种类进行准确识别。
首先,项目利用CNN模型,这是一种专门用于图像识别任务的深度学习模型。该模型通过多个卷积和池化层,能够有效地捕捉图像中的特征,为猫的种类识别提供强大的学习能力。
其次,通过对收集到的数据进行训练,本项目致力于建立一个能够准确辨识猫的种类的模型。包括各种猫的图像,以确保模型能够泛化到不同的种类和场景。
为了进一步提高模型性能,采用了数据增强技术。数据增强通过对训练集中的图像进行旋转、翻转、缩放等操作,生成更多的变体,有助于模型更好地适应不同的视角和条件。
同时,引入残差网络的思想,有助于解决深层网络训练中的梯度消失问题,提高模型的训练效果。这种结合方法使得模型更具鲁棒性和准确性。
最终,通过本项目,实现了对猫的种类进行精准识别的目标。这对于宠物领域、动物学研究等方面都具有实际应用的潜力,为相关领域提供了一种高效而可靠的工具。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
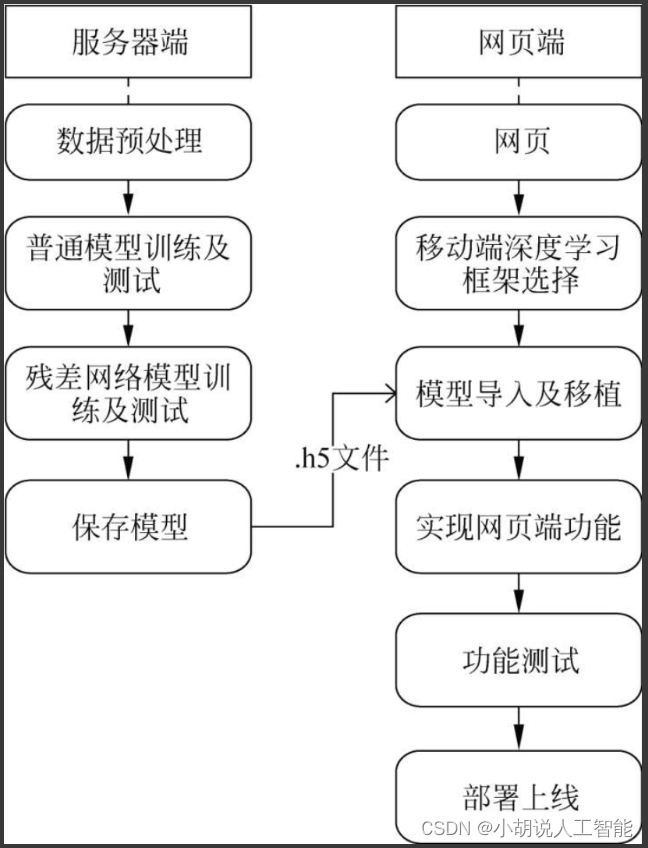
系统流程图
系统流程如图所示。
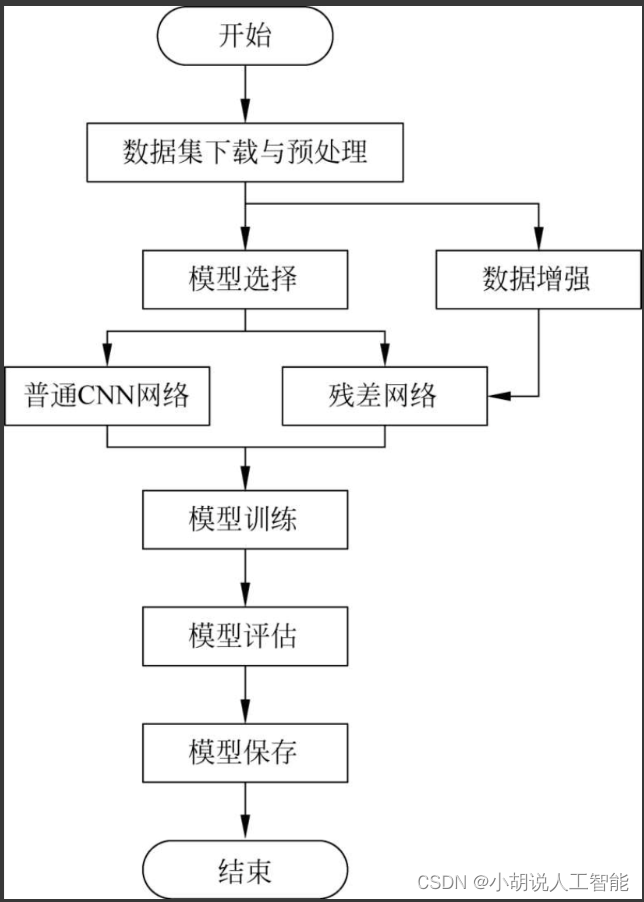
运行环境
本部分包括计算型云服务器、Python环境、TensorFlow环境和MySQL环境。
详见博客。
模块实现
本项目包括5个模块:数据预处理、数据增强、普通CNN模型、残差网络模型、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
打开浏览器,分别搜索布偶猫、孟买猫、暹罗猫和英国短毛猫的图片。用批量下载器下载图片,筛选出特征明显的图片作为数据集。使用的图片包含101张布偶猫、97张孟买猫、101张逼罗猫以及85张英国短毛猫,共计384张图片。(其中在工程代码中/cat_kind_model/cat_data_100与/cat_kind_model/cat_data_224也可下载)
详见博客。
2. 数据增强
所谓数据增强,是通过翻转、旋转、比例缩放、随机裁剪、移位、添加噪声等操作对现有数据集进行拓展。本项目中数据量较小,无法提取图片的深层特征,使用深层的残差网络时易造成模型过拟合。
详见博客。
3. 普通CNN模型
处理图片数据格式后,转换为数组作为模型的输入,并根据文件名提取标签,定义模型结构、优化器、损失函数和性能指标。本项目使用Keras提供类似VGG的卷积神经网络。
1)模型结构
模型结构相关代码如下:
#首先导入相应库
import os
from PIL import Image
import numpy as np
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.optimizers import SGD, RMSprop, Adam
from keras.layers import Conv2D, MaxPooling2D
import argparse
#将图片转换为数组,并提取标签
def convert_image_array(filename, src_dir):img = Image.open(os.path.join(src_dir, filename)).convert('RGB')return np.array(img)
def prepare_data(train_or_test_dir):x_train_test = []#将训练或者测试集图片转换为数组ima1 = os.listdir(train_or_test_dir)for i in ima1:x_train_test.append(convert_image_array(i, train_or_test_dir))x_train_test = np.array(x_train_test)#根据文件名提取标签y_train_test = []for filename in ima1:y_train_test.append(int(filename.split('_')[0]))y_train_test = np.array(y_train_test)#将标签转换格式y_train_test = np_utils.to_categorical(y_train_test)#将特征点从0~255转换成0~1,提高特征提取精度x_train_test = x_train_test.astype('float32')x_train_test /= 255#返回训练和测试数据return x_train_test, y_train_test
搭建网络模型。定义的架构为4个卷积层,每两层卷积后都连接1个池化层,进行数据的降维;一个dropout层,防止模型过拟合;加上Flatten层,把多维的输入一维化;最后是全连接层。
def train_model():#搭建卷积神经网络model = Sequential()model.add(Conv2D(32,(3,3),activation='relu',input_shape=(100,100,3))) #提取图像的特征model.add(Conv2D(32, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25)) #随机扔掉25%的节点权重,防止模型过拟合model.add(Conv2D(64, (3, 3), activation='relu'))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())
#Flatten层输入“压平”,把多维的输入一维化,常用在从卷积层到全连接层的过渡model.add(Dense(256, activation='relu')) #Dense是常用的全连接层model.add(Dropout(0.5))model.add(Dense(4, activation='softmax'))
2)模型优化
确定模型架构之后,使用compile()方法对模型进行编译,这是多类别的分类问题,因此需要使用交叉熵作为损失函数。由于所有标签都带有相似的权重,通常使用精确度作为性能指标,使用随机梯度下降算法来优化模型参数。
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)#SGD优化器
#完成模型搭建后,使用.compile()方法编译
model.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])
return model
3)模型训练
定义模型架构和编译模型后,使用训练集训练模型,使模型可以识别不同种类的猫。这里,将使用训练集和测试集拟合并保存模型。
def main_args(): #初始化用到的参数parser = argparse.ArgumentParser()parser.add_argument('--train_dir', type=str, default='./cat_data_100/train', help="the path to the training imgs")parser.add_argument('--test_dir', type=str, default='./cat_data_100/test', help='the path to the testing imgs')parser.add_argument("--save_model", type=str, default='./models/cat_weight.h5', help='the path and the model name')parser.add_argument("--batch_size", type=int, default=10, help='the training batch size of data')parser.add_argument("--epochs", type=int, default=32, help='the training epochs')options = parser.parse_args()return options
#开始模型生成
if __name__ == "__main__":#调用函数获取用户参数options = main_args()#调用函数获取模型model = train_model()#调用函数获取训练数据和标签x_train, y_train = prepare_data(options.train_dir)x_test, y_test = prepare_data(options.test_dir)
#训练数据上按batch进行一定次数的迭代训练网络
model.fit(x_train, y_train, shuffle=True, batch_size=options.batch_size, epochs=options.epochs)
#使用一行代码对模型进行评估,看模型的指标是否满足要求
score = model.evaluate(x_test, y_test, batch_size=10)
print("Testing loss:{0},Testing acc:{1}".format(score[0], score[1]))
其中,一个batch就是在一次前向/后向传播过程用到的训练样例数量,每次读入10张图片作为一个批量大小,数据集循环迭代32次。
通过观察训练集和测试集的损失函数、准确率的大小来评估模型的训练程度,进行进一步决策。一般来说,训练集和测试集的损失函数(或准确率)不变且基本相等为模型训练的最佳状态。
4)模型保存
将模型文件保存为.h5格式,以便于移植到其他环境中使用。
#保存训练完成的模型文件
save_model = options.save_model
save_model_path = os.path.dirname(save_model)
save_model_name = os.path.basename(save_model)
if not os.path.exists(save_model_path):os.mkdir(save_model_path)
model.save_weights(save_model, overwrite=True)
其他相关博客
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






