样本专题

医院检验系统LIS源码,LIS系统的定义、功能结构以及样本管理的操作流程
本文将对医院检验系统LIS进行介绍,包括LIS系统的定义、功能结构以及样本管理的操作流程方面。 LIS系统定义 LIS系统(Laboratory Information System)是一种专门为临床检验实验室开发的信息管理系统,其主要功能包括实验室信息管理、样本管理、检验结果管理、质量控制管理、数据分析等。其主要作用是管理医院实验室的各项业务,包括样本采集、检验、结果录入和报告生成等。Li

PDF样本图册转换为一个二维码,随时扫码打开无需印刷
在这个数字化时代,纸质样本图册已成为过去。如今,一切都变得触手可及,包括我们的PDF样本图册。想象一下,将这些图册转换为一个二维码,让客户随时扫码打开,无需印刷,这将带来多大的便利和环保效益!接下来就让我来教你如何轻松实现PDF样本图册到二维码的转换,让您与时俱进,走在环保科技的前沿吧。 1. 准备好制作工具:FLBOOK在线制作电子杂志平台 2. 转换文档:点击开始

论文速读|利用局部性提高机器人操作的样本效率
项目地址:SGRv2 本文提出了SGRv2,一个系统的视觉运动政策框架,通过整合动作局部性提高了样本效率。在多个模拟和真实世界环境中进行的广泛评估表明,SGRv2在数据有限的情况下表现出色,并且在不同的控制模式下保持一致的性能。未来的工作可以进一步探索将扩散政策与局部性框架结合,以增强在现实世界中的性能,并扩展泛化测试的范围。 论文初读:

在目标检测模型中使用正样本和负样本组成的损失函数。
文章目录 背景例子说明1. **样本和标签分配**2. **计算损失函数**3. **组合损失函数** 总结 背景 在目标检测模型中,损失函数通常包含两个主要部分: 分类损失(Classification Loss):用于评估模型对目标类别的预测能力。定位损失(Localization Loss):用于评估模型对目标位置的预测准确性。 例子说明 假设我们有一个目标检测模

R-Adapter:零样本模型微调新突破,提升鲁棒性与泛化能力 | ECCV 2024
大规模图像-文本预训练模型实现了零样本分类,并在不同数据分布下提供了一致的准确性。然而,这些模型在下游任务中通常需要微调优化,这会降低对于超出分布范围的数据的泛化能力,并需要大量的计算资源。论文提出新颖的Robust Adapter(R-Adapter),可以在微调零样本模型用于下游任务的同时解决这两个问题。该方法将轻量级模块集成到预训练模型中,并采用新颖的自我集成技术以提高超出分布范围的鲁棒性

学术分享|无惧数据匮乏!上海交大博士后周子宜详解蛋白质语言模型的小样本学习方法 FSFP
预训练蛋白质语言模型 (PLMs) 能够以无监督的方式学习数百万蛋白质中氨基酸序列的分布特征,在揭示蛋白质序列与其功能之间的隐含关系方面显示出了巨大的潜力。 在此背景下,上海交通大学自然科学研究院/物理天文学院/张江高研院/药学院洪亮教授课题组,联合上海人工智能实验室青年研究员谈攀,开发了一种针对蛋白质语言模型的小样本学习方法,能够在使用极少数湿实验数据的情况下大幅提升传统蛋白质语言模型的突变效

零样本学习(zero-shot learning)——综述
-------本文内容来自对论文A Survey of Zero-Shot Learning: Settings, Methods, and Applications 的理解和整理,这里省去了众多的数学符号,以比较通俗的语言对零样本学习做一个简单的入门介绍,用词上可能缺乏一定的严谨性。一些图和公式直接来自于论文,并且省略了论文中讲的比较细的东西,如果感兴趣建议还是去通读论文 注1:为了方便,文中

CVPR2019 少样本学习
分类任务上的少样本学习 1.Edge-Labeling Graph Neural Network for Few-shot Learning(classification) paper: https://arxiv.org/abs/1905.01436 code: https://github.com/khy0809/fewshot-egnn 图网络(Graph Neural Ne

NLP-信息抽取-NER-2015-BiLSTM+CRF(一):命名实体识别【预测每个词的标签】【评价指标:精确率=识别出正确的实体数/识别出的实体数、召回率=识别出正确的实体数/样本真实实体数】
一、命名实体识别介绍 命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取, 问答系统, 句法分析, 机器翻译等应用领域的重要基础工具, 在自然语言处理技术走向实用化的过程中占有重要地位. 包含行业, 领域专有名词, 如人名, 地名, 公司名, 机构名, 日期, 时间, 疾病名, 症状名, 手术名称, 软

PyTorch数据加载:自定义数据集【Dataset:处理每个原始样本】【DataLoader:每次生成batch_size个样本】【collate_fn:重新设置一个Batch中所有样本的加载格式】
一、自定义Dataset Dataset是一个包装类: 用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。可以通过继承Dataset来将数据集的源文件、规模和其他非必要的功能打包,从而供DataLoader使用。 1、“文本分类”任务下使用自定义Dataset class.txt:所有类别 finance
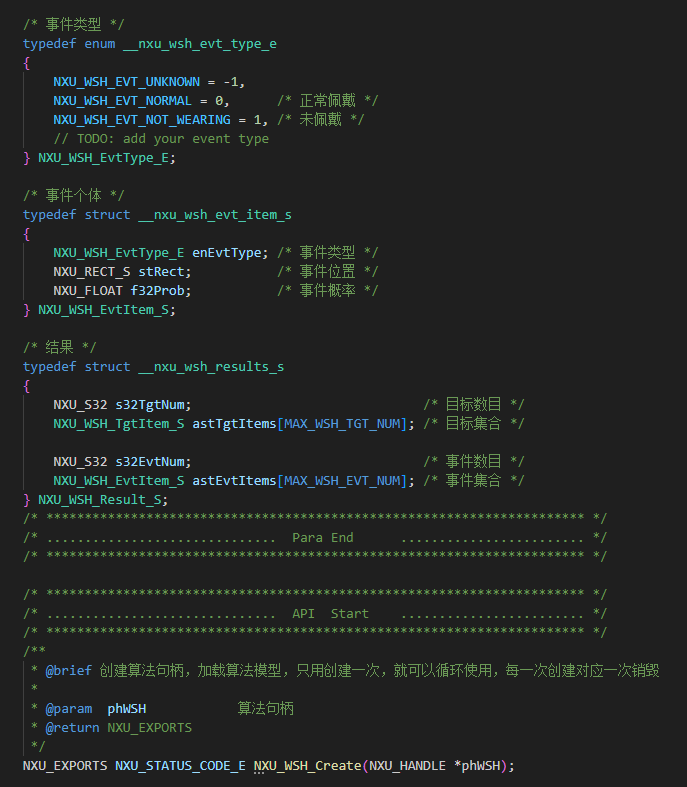
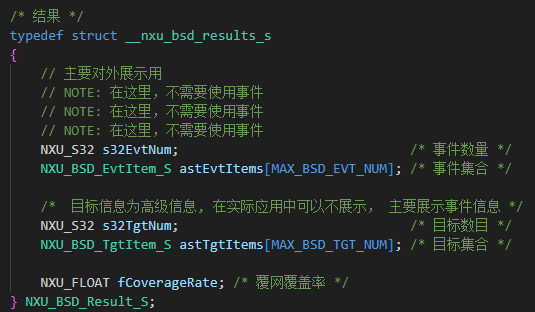
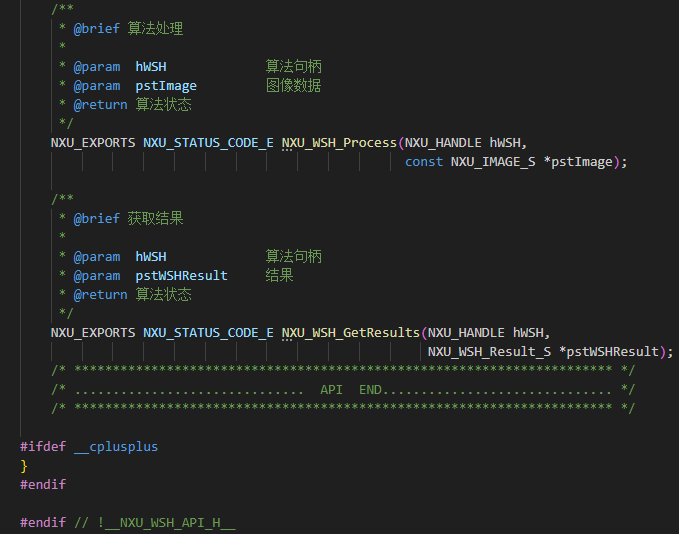
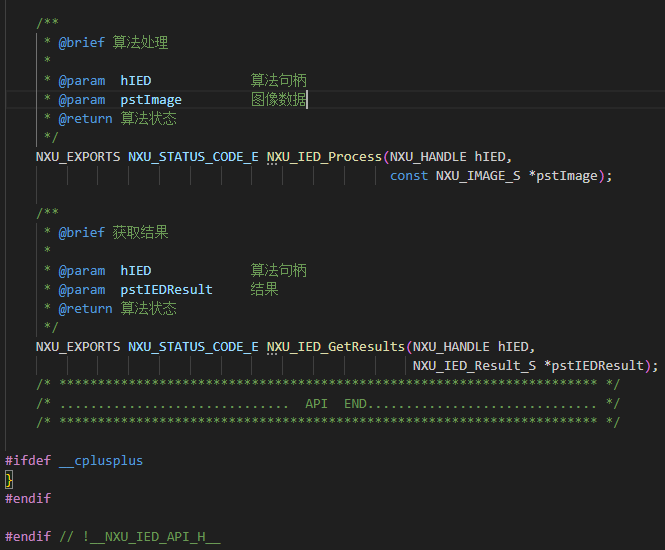
未戴安全帽算法检测源码样本安防监控视频分析未戴安全帽检测算法应用场景
未戴安全帽检测算法是一种基于计算机视觉和深度学习技术的智能分析算法,旨在通过分析图像或视频流,自动识别人员是否佩戴了安全帽,并在检测到未佩戴情况时采取相应的措施(如发出警报或记录事件)。 实际应用中的优势 1. 提高检测准确性 智能安全帽检测算法在识别的准确性上有显著提升。相比于人工检查,算法可以处理大量的图像数据,并且几乎不受疲劳和主观判断的影响。这种自动化检测方式减少了人为错误的可能性,

深度学习样本不均衡问题解决
在深度学习中,样本不均衡是指不同类别的数据量差别较大,利用不均衡样本训练出来的模型泛化能力差并且容易发生过拟合。 对不平衡样本的处理手段主要分为两大类:数据层面 (简单粗暴)、算法层面 (复杂) 。 数据层面 采样(Sample) 数据重采样:上采样或者下采样 上采样下采样使用情况数据不足时数据充足 (支撑得起你的浪费)数据集变化增加间接减少(量大类被截流了)具体手段大量复制量少类
浅析裸土检测算法的实际应用及裸土检测算法源码样本
在环境保护和农业管理的持续推进中,裸土检测算法作为一种先进的技术工具,发挥着越来越重要的作用。它不仅提升了裸土监测的效率和准确性,还在实际应用中展示了巨大的潜力。本文将探讨裸土检测算法在实际应用中的表现,揭示其带来的显著成效,并展望其未来的发展方向。 裸土,即缺乏植被覆盖的土壤,容易受到侵蚀和风化,对环境和农业产生负面影响。传统的裸土检测方法多依赖地面勘察,虽然直观,但效率低下且成本高。随着

从零样本学习理论模型到工业应用—–动机、演变与挑战
源自:控制与决策 作者:赵健程 冯良骏 岳嘉祺 张堡霖 赵春晖 付永鹏 王福利 注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章 人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习 摘 要 随着工业大数据技术的发展,应用于工业对象的有监督方法得
加油站等重点区域吸烟检测算法应用方案实时监控吸烟检测算法样本算法源码展示
重点区域抽烟检测算法是一种基于计算机视觉和深度学习技术的应用,旨在自动监控并检测特定区域内的吸烟行为。这种算法对于维护无烟环境、保障公共安全以及执行禁烟法规具有重要作用。以下是关于重点区域抽烟检测算法源码及其实际应用的详细阐述: 1. 算法实现 - 深度学习框架:抽烟检测算法通常采用卷积神经网络(CNN)等深度学习模型,这些模型能够从图像或视频中提取烟雾和点燃香烟的视觉特征。 -


概率论学习笔记--简单随机抽样样本
简单随机抽样:总体中每个个体被抽中的概率都相等 统计量 样本均值 样本方差 卡方分布 t分布–student 分布 f分布 F分布的分位点 抽样分布 正态总体的样本分布 两个正态总体的样本均值与样本方差

YOLOv9改进策略【损失函数篇】| Slide Loss,解决简单样本和困难样本之间的不平衡问题
一、本文介绍 本文记录的是改进YOLOv9的损失函数,将其替换成Slide Loss,并详细说明了优化原因,注意事项等。Slide Loss函数可以有效地解决样本不平衡问题,为困难样本赋予更高的权重,使模型在训练过程中更加关注困难样本。若是在自己的数据集中发现容易样本的数量非常大,而困难样本相对稀疏,可尝试使用Slide Loss来提高模型在处理复杂样本时的性能。 文章目录 一、本文介绍

【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
目录 一、引言 二、零样本物体检测(zero-shot-object-detection) 2.1 概述 2.2 技术原理 2.3 应用场景 2.4.1 pipeline对象实例化参数 2.4.2 pipeline对象使用参数 2.4 pipeline实战 2.5 模型排名 三、总结 一、引言 pipeline(管道)是huggingface trans

机器学习之样本不均衡
样本不平衡问题在很多场景中存在,例如欺诈检测,风控识别,在这些样本中,负样本(一般为存在问题的样本)的数量一般远少于正样本(正常样本)。 上采样(过采样)和下采样(负采样)策略是解决类别不平衡问题的基本方法之一。 上采样即增加少数类样本的数量,对小类的数据样本进行过采样来增加小类的数据样本个数,即采样的个数大于该类样本的个数。 这种方法的缺点是如果样本特征少而可能导致过拟合的问题; 下采样即
工业排污检测算法的算法样本及工业排污检测的源码展示
工业排污检测算法是一种结合了先进人工智能、图像识别、声音识别、数据分析等技术的解决方案,专门用于实时监测和评估工业排放的污染物。这种算法在环境保护、合规管理、数据支持等方面具有显著的优势,并且可以广泛应用于各种工业场景。 主要作用 1、实时监测与预警:通过安装在工业设施附近的传感器和摄像头,实时收集排污数据和图像信息,并进行预处理和分析,以实现对工业排污的实时监测。一旦发现异常情况,如污染物浓

【机器学习】小样本学习的实战技巧:如何在数据稀缺中取得突破
我的主页:2的n次方_ 在机器学习领域,充足的标注数据通常是构建高性能模型的基础。然而,在许多实际应用中,数据稀缺的问题普遍存在,如医疗影像分析、药物研发、少见语言处理等领域。小样本学习(Few-Shot Learning, FSL)作为一种解决数据稀缺问题的技术,通过在少量样本上进行有效学习,帮助我们在这些挑战中取得突破。 1. 小样本学习的基础 小样本学习,
样本不平衡--SMOTE算法-学习笔记
1 SMOTE算法的简单理解 一个数集中的数据是分布在特征空间中的,假设数据是2维的,那么数据的就是一个平面上的点。对于类别不平衡数据来说,假设负样本数据是少量的,那么这个数据只占据了空间的一小部分。SMOTE 算法就是对这些小样本数据占据的空间中进行插值。 而不影响到正样本的空间。 2 如何插值 SMOTE算法采取了一种策略,选择两个距离接近的点进行插值。
车辆类型检测算法、车辆类型源码及其样本与模型解析
车辆类型检测算法是利用计算机视觉和深度学习技术,对车辆图像进行自动分析和识别,以判断车辆的类型(如轿车、SUV、货车等)的一种算法。以下是对车辆类型检测算法的详细解析: 一、算法基础 车辆类型检测算法的基础是图像处理和深度学习技术。通过摄像头捕捉到的车辆图像,算法会对图像进行预处理,包括去噪、增强对比度等,以提高后续处理的准确性。 二、优势与应用 优势: 高准确率:深度学习算法的引入
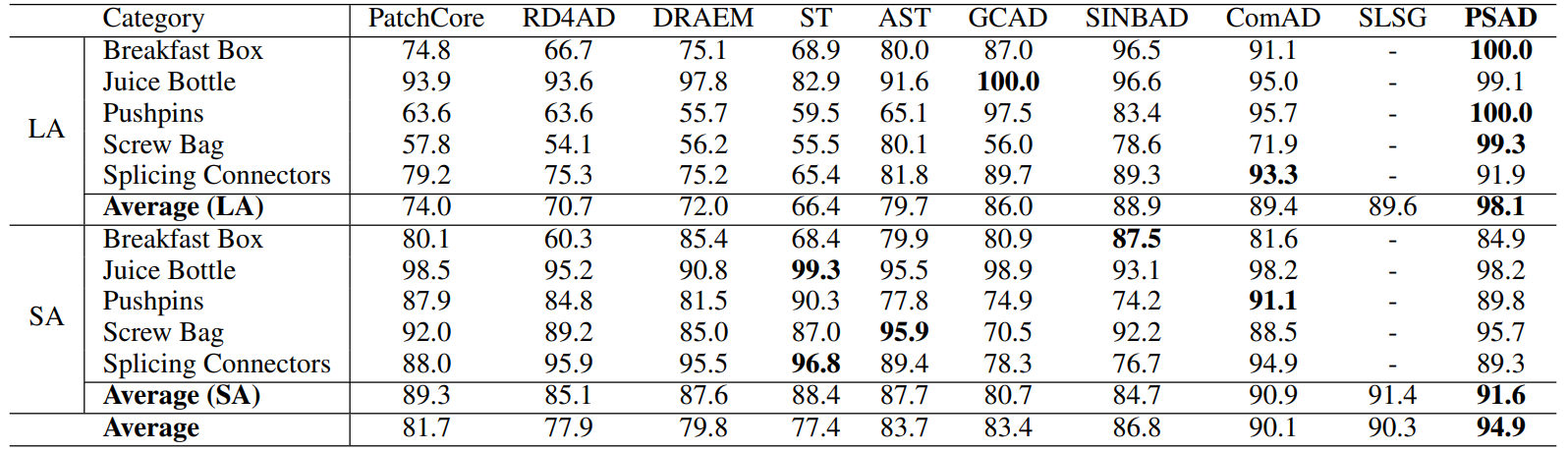
小样本异常检测新突破!全新FSAD方法全类别通用,idea代码已开源
小样本异常检测FSAD,一种适用于标注数据稀缺情况下的异常检测技术。在仅有少量标注数据的情况下,它比传统方法更能提高准确性和效率,是工业监控、医疗诊断等领域的关键技术。 目前FSAD还存在很多问题等我们解决,不过换个思路想,这些都是可挖掘的创新方向,而且已经有效果绝赞的成果可参考,比如GraphCore,突破工业视觉极限,减少冗余视觉特征的数量;再比如CAReg,首个全类别通用的开源FSAD方法
服装门店神秘顾客监测样本及频次
服装门店神秘顾客调查的关键目的:1、根据不同顾客体验的关键维度,形成测量指标体系 ;2、通过暗访了解服装门店销售服务表现 ;3、通过数据分析,对服务流程和标准提出改进建议。 神秘顾客是以潜在消费者或真实消费者的身份对某一顾客服务过程进行体验和评价,然后以特定的方式详细客观的反馈其消费体验。了解各种类型窗口行业营业/服务的环境、服务人员的服务态度、查业务素质和技能等情况,广泛应用到如电信、银行、超