本文主要是介绍小样本异常检测新突破!全新FSAD方法全类别通用,idea代码已开源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小样本异常检测FSAD,一种适用于标注数据稀缺情况下的异常检测技术。在仅有少量标注数据的情况下,它比传统方法更能提高准确性和效率,是工业监控、医疗诊断等领域的关键技术。
目前FSAD还存在很多问题等我们解决,不过换个思路想,这些都是可挖掘的创新方向,而且已经有效果绝赞的成果可参考,比如GraphCore,突破工业视觉极限,减少冗余视觉特征的数量;再比如CAReg,首个全类别通用的开源FSAD方法,完美解决计算成本高且效率低的问题。
为了帮各位论文er省下查找资料的时间,我从中挑选了11个FSAD相关最新成果来和大家分享,idea都非常值得学习,当然开源代码也都整理了,大家有任何复现问题都可以来讨论~
论文原文+开源代码需要的同学看文末
Pushing the limits of few-shot anomaly detection in industry vision: GraphCore
方法:作者针对工业产品的少样本视觉异常检测提出一种新方法GraphCore,通过提取视觉同构不变特征(VIIF)来进行异常测量,实验结果表明该方法在MVTec AD和MPDD数据集上的性能显著优于现有方法,并且只需极少量的正常样本进行训练。
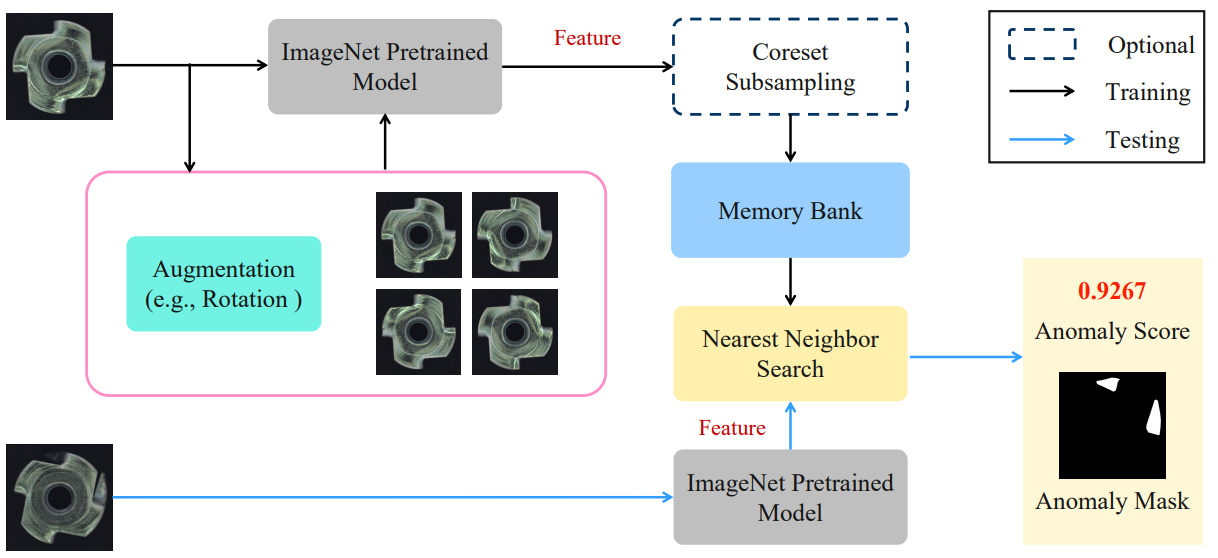
创新点:
-
提出了一种特征增强的方法,用于研究由CNN生成的视觉特征的属性。
-
提出了一种名为GraphCore的新的FSAD方法,通过使用少量正常样本进行快速训练,实现了新产品的竞争性AD准确性表现,并且能够防止旧产品的异常迁移和适应。
-
提出了一种新的模型VIIG,可以从少量正常样本中提取视觉等距不变特征(VIIF),并将其添加到特征存储器中,从而提高了异常检测的准确性。

Few-Shot Anomaly Detection via Category-Agnostic Registration Learning
方法:论文提出了一种新颖的少样本异常检测方法,称为CAReg,通过学习通用的跨类别注册技术,仅使用每个类别的正常图像进行训练,从而实现了对新类别的无需微调的模型应用,提高了异常检测的准确性和效率。
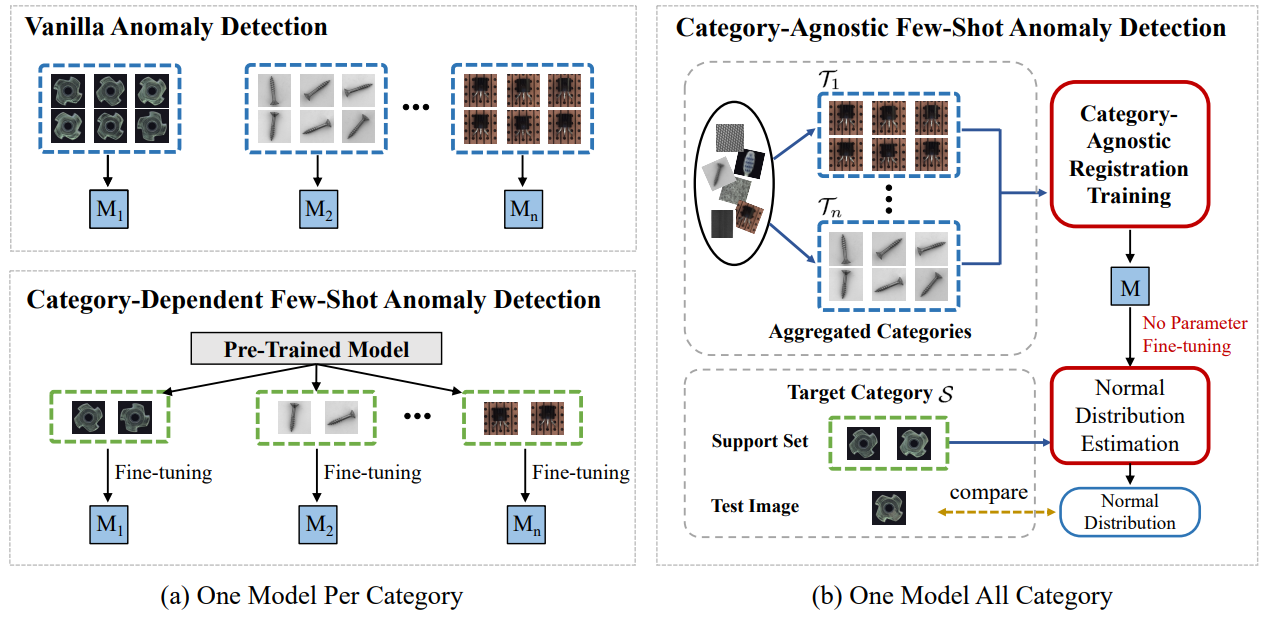
创新点:
-
引入了一种类别无关的异常检测模型:通过将异常检测建模为一个比较任务,模型可以在不需要了解图像类别的情况下进行异常检测。通过特征级别的配准,模型可以将不同类别的图像进行比较,从而实现跨类别的异常检测。
-
提出了一种基于Siamese网络和空间变换网络的特征配准模块:通过特征级别的配准,模型可以将不同类别的图像进行对齐,从而提高模型的泛化能力和鲁棒性。

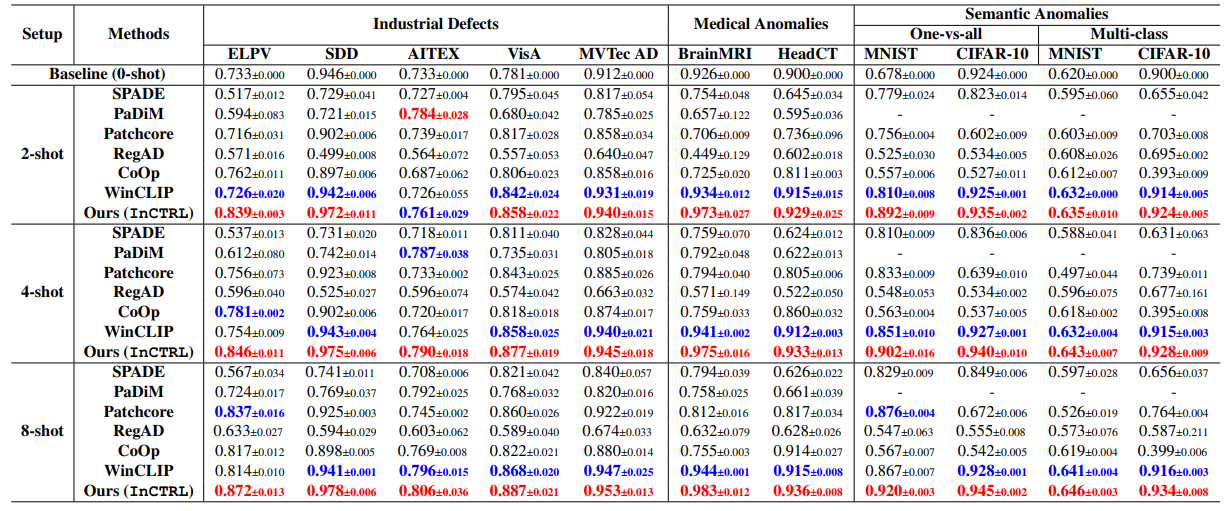
Toward Generalist Anomaly Detection via In-context Residual Learning with Few-shot Sample Prompts
方法:论文提出了一种名为 InCTRL 的新型小样本异常检测方法,旨在训练一个能够泛化到不同应用领域数据集的通用异常检测模型,而无需在目标数据上进行进一步训练。InCTRL通过对查询图像和少量正常样本提示之间的残差进行整体评估,实现了优秀的GAD泛化能力。
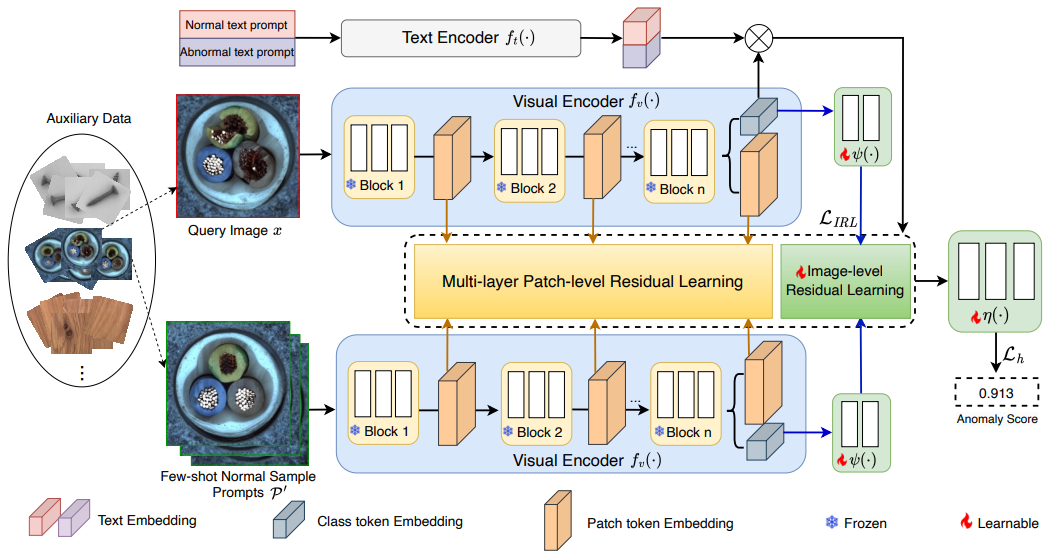
创新点:
-
引入了GAD任务,用于评估AD方法在不需要在目标数据集上进行训练/调优的情况下,在各种场景下识别异常的泛化能力。
-
提出了一种名为InCTRL的方法来解决这个问题。InCTRL通过在上下文中进行残差学习来实现优越的GAD泛化。通过图像级别和补丁级别的残差学习,InCTRL能够更好地捕捉查询图像和少样本正常样本之间的局部和全局差异。
-
InCTRL允许将文本提示引导的正常/异常先验知识无缝整合到检测模型中,为文本-图像对齐的语义空间提供了额外的优势。
Few Shot Part Segmentation Reveals Compositional Logic for Industrial Anomaly Detection
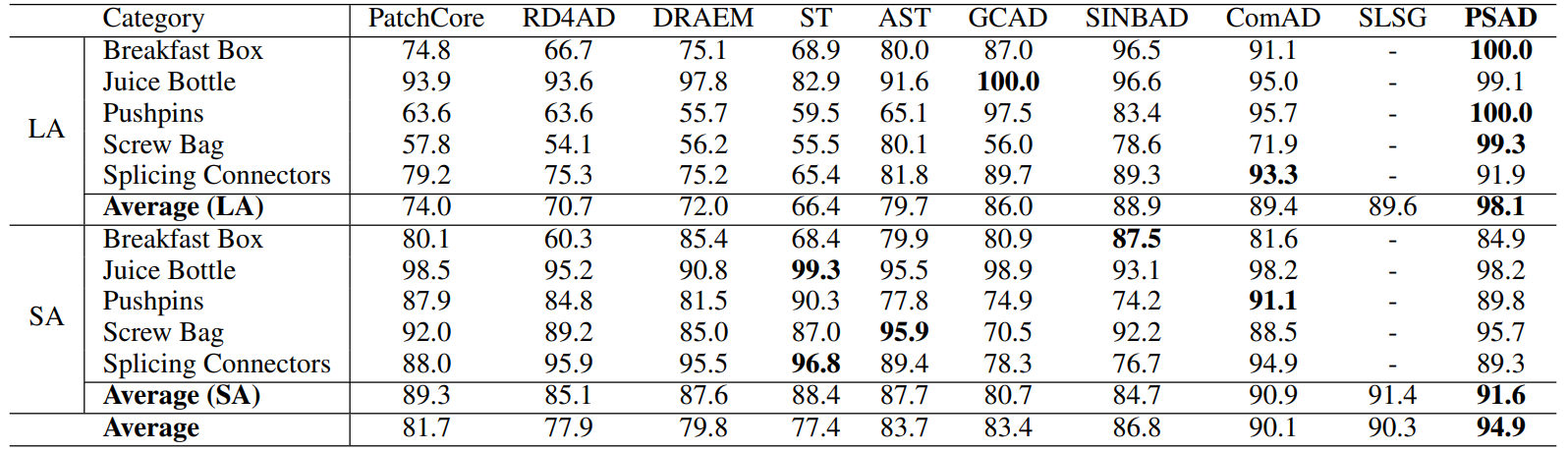
方法:论文提出了一种新的分割模型,利用少量标记图像和正常图像之间共享的逻辑约束。作还提出了一种新颖的AD方法,其中包括基于分割的构建3个不同存储器的方法。为了生成统一的异常分数,作者引入了自适应缩放策略,这样该模型能够检测LA和SA,并且在用户所需的最小工作量下取得了显著的改进。
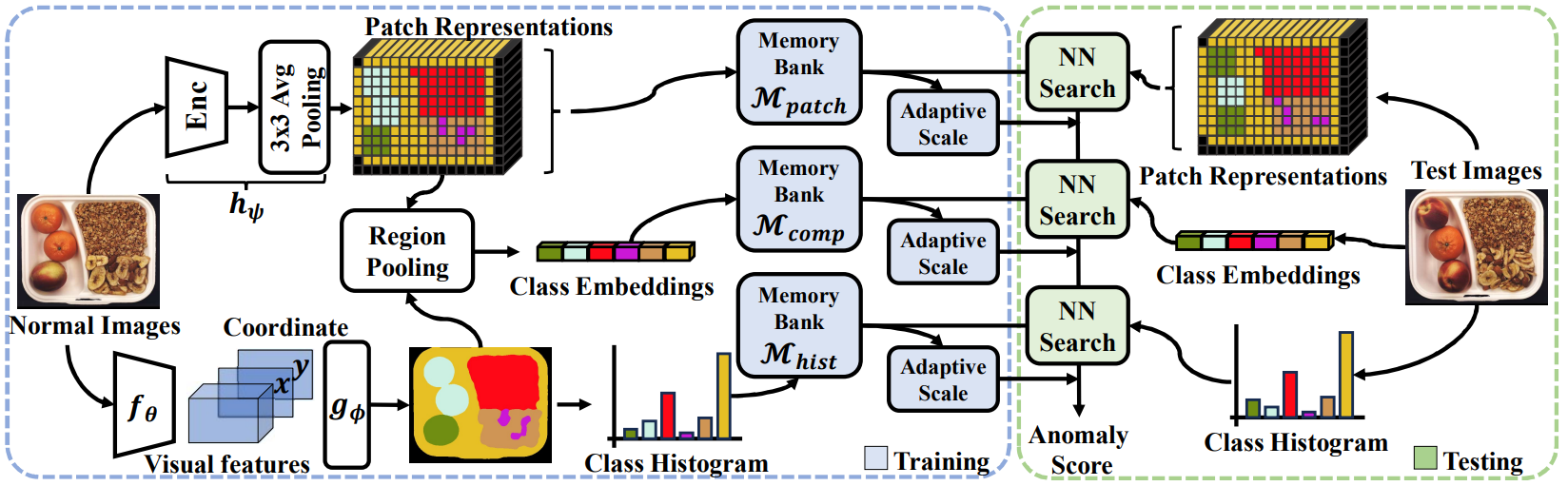
创新点:
-
利用部分分割进行异常检测(PSAD):提出了一种新的异常检测方法,使用三个不同的内存库,利用视觉特征和语义分割来检测元素的局部和全局依赖关系。
-
自适应缩放方法:提出了一种自适应缩放方法,用于聚合具有不同尺度的异常分数,以确保可以可靠地比较分数。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“FSAD”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏
这篇关于小样本异常检测新突破!全新FSAD方法全类别通用,idea代码已开源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






