本文主要是介绍概率论之样本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
忧患
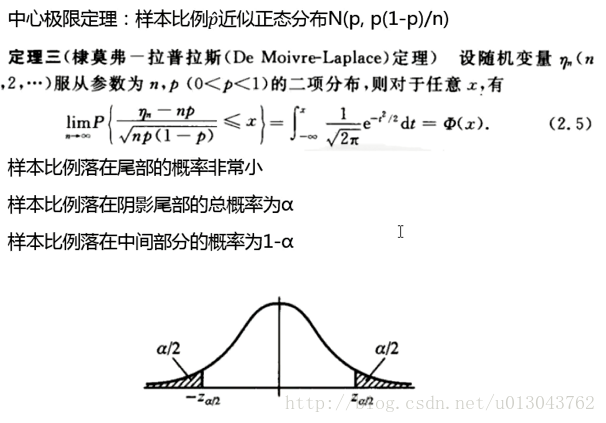
点估计—置信区间

置信区间—-名称解析
置信区间(confidence interval):用来估计总体参数真实值的一个区间,通常形式:估计值+-误差界限
误差界限(margin of error ) : 估计值的最大误差,使用E表示

置信区间
总体比例的区间估计
要求:
- 样本要为简单随机样本
- 二项分布的条件分布
- 至少要有5个成功,5个失败,即np>=5,nq>=5
更精确的方法


置信区间

样本容量的确定


扩展

总体均值估计

总体均值的估计—ρ已知

区间估计

例子

总体均值的估计—-ρ已知

样本容量的确定

总体均值估计–区间估计—-ρ未知

例子

总体方差的估计
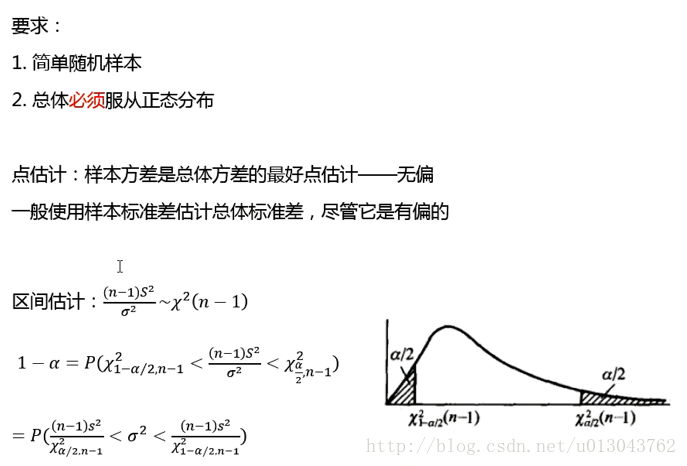
例子
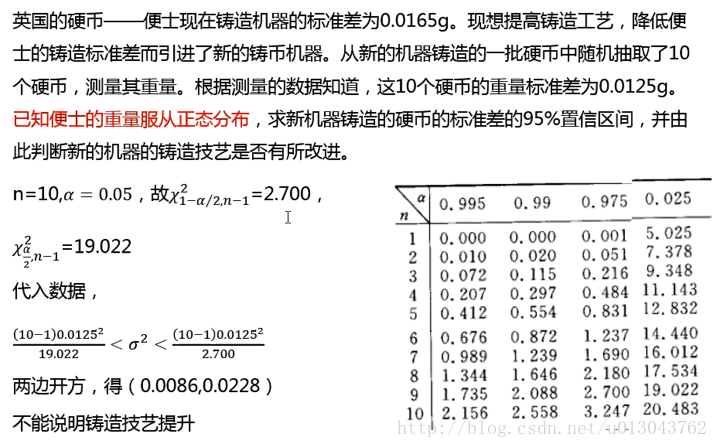
单侧区间估计
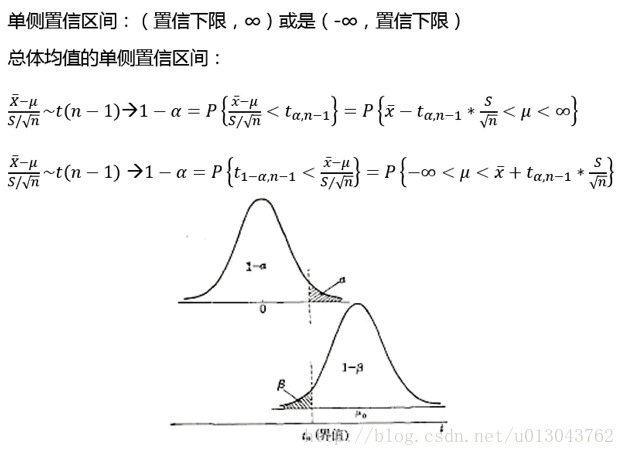
例子

这篇关于概率论之样本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








