本文主要是介绍基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)
目录
- 系列文章目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 计算型云服务器
- Python环境
- TensorFlow环境
- MySQL环境
- Django环境
- 其他相关博客
- 工程源代码下载
- 其它资料下载

前言
本项目以卷积神经网络(CNN)模型为基础,对收集到的猫咪图像数据进行训练。通过采用数据增强技术和结合残差网络的方法,旨在提高模型的性能,以实现对不同猫的种类进行准确识别。
首先,项目利用CNN模型,这是一种专门用于图像识别任务的深度学习模型。该模型通过多个卷积和池化层,能够有效地捕捉图像中的特征,为猫的种类识别提供强大的学习能力。
其次,通过对收集到的数据进行训练,本项目致力于建立一个能够准确辨识猫的种类的模型。包括各种猫的图像,以确保模型能够泛化到不同的种类和场景。
为了进一步提高模型性能,采用了数据增强技术。数据增强通过对训练集中的图像进行旋转、翻转、缩放等操作,生成更多的变体,有助于模型更好地适应不同的视角和条件。
同时,引入残差网络的思想,有助于解决深层网络训练中的梯度消失问题,提高模型的训练效果。这种结合方法使得模型更具鲁棒性和准确性。
最终,通过本项目,实现了对猫的种类进行精准识别的目标。这对于宠物领域、动物学研究等方面都具有实际应用的潜力,为相关领域提供了一种高效而可靠的工具。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
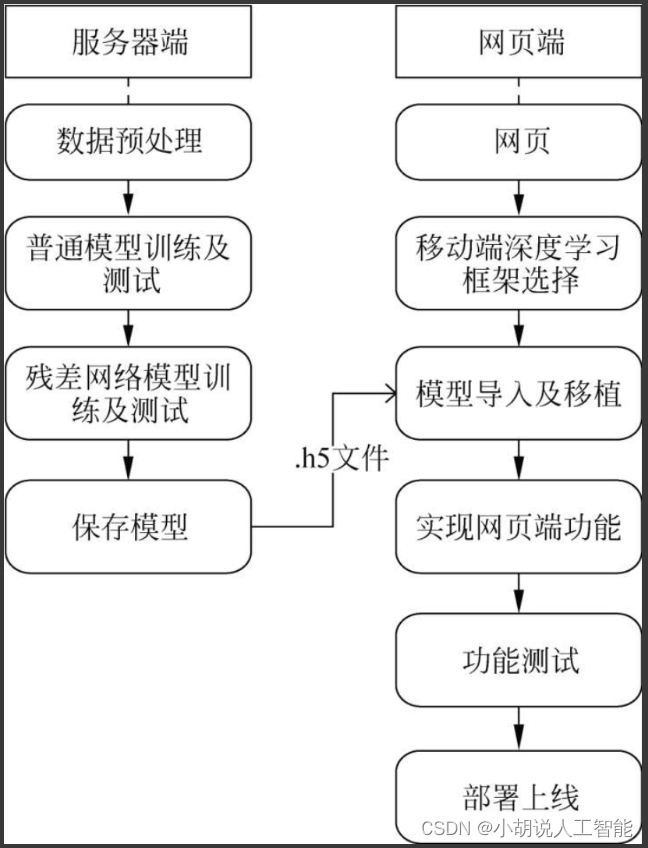
系统流程图
系统流程如图所示。
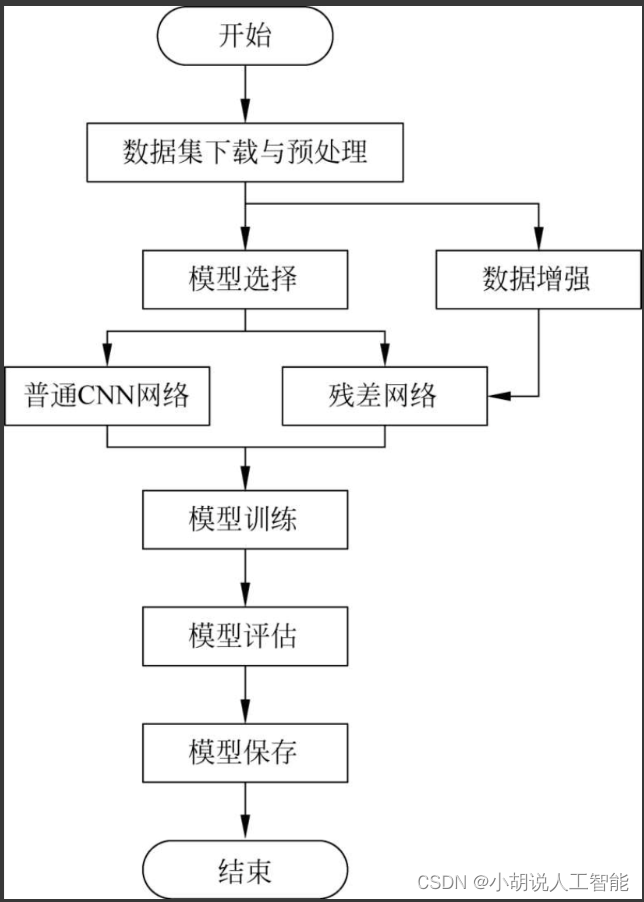
运行环境
本部分包括计算型云服务器、Python环境、TensorFlow环境和MySQL环境。
计算型云服务器
在阿里云官网注册并充值后,搜索"云服务器ESC",即可购买计算型云服务器。
付费模式下选择抢占式实例,地域及可用区选择华北5,类型依次选择异构计算GPU/FPGA/NPU→GPU计算型→实例规格:ecs.gn5-c4g1.xlarge。
单台实例规格上限价使用自动出价,数量为1,镜像选择市场中CentOS7.3(预装NVIDIAGPU驱动和深度学习框架)V1.0。
设置密码后,单击"创建实例"即可。远程连接时,输入密码登录。
Python环境
需要Python 3.6及以上配置,以Linux环境下安装为例,安装依赖环境,输入命令:
yum-y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
下载Python3,输入命令:
wget https://www.python.org/ftp/python/3.6.1/Python-3.6.1.tgz
安装Python3,在/usr/local/python3目录下,输入命令:
mkdir -p /usr/local/python3
tar -zxvf Python-3.6.1.tgz
进入解压后的目录,编译安装,输入命令:
cd Python-3.6.1
./configure--prefix=/usr/local/python
建立Python3的软链,输入命令:
ln -s /usr/local/python3/bin/python3/usr/bin/python3
将/usr/local/python3/bin加入PATH,输入命令:
vim ~/.bash_profile
.bash_profile
获取别名和函数,输入命令:
if[-f~/.bashrc];then
.~/.bashrc
fi
增加新环境的目录,输入命令:
PATH=$PATH:$HOME/bin:/usr/local/python3/bin
export PATH
按Esc键,输入wq,按回车键退出。使上一步的修改生效,输入命令:
source ~/.bash_profile
检查Python3及pip3能否正常使用,输入命令:
python3 -V
pip3 -V
TensorFlow环境
安装TensorFlow环境及各种库,升级pip3,输入命令:
pip3 install --upgrade pip
查询CUDA版本,输入命令:
cat /usr/local/cuda/version.txt
查看CUDA版本,输入命令:
cat /usr/local/cuda/include/cudnn.h | grep cuDNN_MAJOR-A 2
安装对应GPU版本的TensorFlow,如图所示。
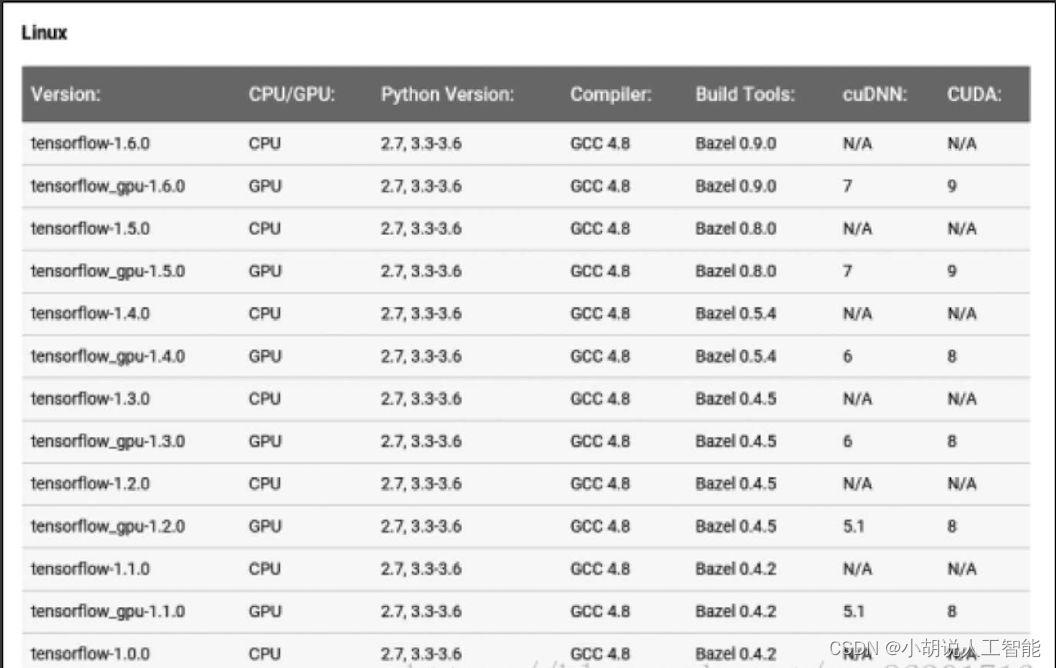
安装TensorFlow,输入命令:
pip3 install tensorflow_gpu==1.4
安装TensorFlow对应的Keras库,输入命令:
pip3 install keras=2.2.4
安装其他需要使用的库,输入命令:
pip3 install pillow
pip3 install numpy
pip3 install h5py
pip3 install tqdm
安装完毕。
MySQL环境
在http://www.mysql.com中下载MySQL安装包,选择Community版本。
选择MySQL Community Server,单击Go to DownloadPage,打开下载界面,选择本地安装包下载,然后直接下载。
打开下载好的安装包,按照默认设置安装MySQL(地址可更改)。在Accounts and Roles处设置root用户名和密码,用于登录数据库。
安装Navicat for MySQL,便于操作数据库。官网地址为:https://navicat.com.cn/products/navicat-for-mysql,按照默认设置安装即可。
当Navicat for MySQL客户端连接到数据库后,鼠标右键"连接名",新建名为catkind的数据库,使用UTF-8编码。
Django环境
下载PyCharm以及Anaconda,完成Python所需环境的配置,本项目使用Python 3.6版本。打开Anaconda Prompt,输入清华仓库镜像,输入命令:
conda config--add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config-set show_channel_urls yes
创建Python3.6的环境,名称为TensorFlow,输入命令:
conda create -n tensorflow python=3.6
有需要确认的地方,都输入y。
在Anaconda Prompt或者终端中激活TensorFlow环境,输入命令:
conda activate tensorflow
安装Django,输入命令:
pip install django==1.8.2
pip install pymysql==0.8.0
其他相关博客
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









