本文主要是介绍基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(四),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python环境
- TensorFlow 环境
- Jupyter Notebook环境
- Pycharm 环境
- 微信开发者工具
- OneNET云平台
- 模块实现
- 1. 数据预处理
- 2. 创建模型并编译
- 3. 模型训练及保存
- 1)模型训练
- 2)模型保存
- 4. 上传结果
- 1)图片拍摄
- 2)模型导入及调用
- 3)数据上传OneNET云平台
- (1)图片信息上传
- (2)预测结果上传
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目基于Keras框架,引入CNN进行模型训练,采用Dropout梯度下降算法,按比例丢弃部分神经元,同时利用IOT及微信小程序实现自动化远程监测果实成熟度以及移动端实时监测的功能,为果农提供采摘指导,有利于节约劳动力,提高生产效率,提升经济效益。
本项目基于Keras框架,采用卷积神经网络(CNN)进行模型训练。通过引入Dropout梯度下降算法,实现了对神经元的按比例丢弃,以提高模型的鲁棒性和泛化性能。同时,利用物联网(IoT)技术和微信小程序,项目实现了自动化远程监测果实成熟度,并在移动端实时监测果园状态的功能。这为果农提供了采摘的实时指导,有助于节约劳动力、提高生产效率,从而提升果园经济效益。
首先,项目采用Keras框架构建了一个卷积神经网络,利用深度学习技术对果实成熟度进行准确的识别和预测。
其次,引入Dropout梯度下降算法,通过随机丢弃神经元的方式,防止模型过拟合,提高了对新数据的泛化能力。
接着,项目整合了物联网技术,通过传感器等设备对果园中的果实进行远程监测。这样,果农可以在不同地点远程了解果实的成熟度状况。
同时,通过微信小程序,果农可以实时监测果园状态,了解果实成熟度、采摘时机等信息,从而更加科学地安排采摘工作。
总体来说,该项目不仅在模型训练上引入了先进的深度学习技术,还通过物联网和微信小程序实现了智能化的果园管理系统,为果农提供了更加便捷、高效的农业生产解决方案。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
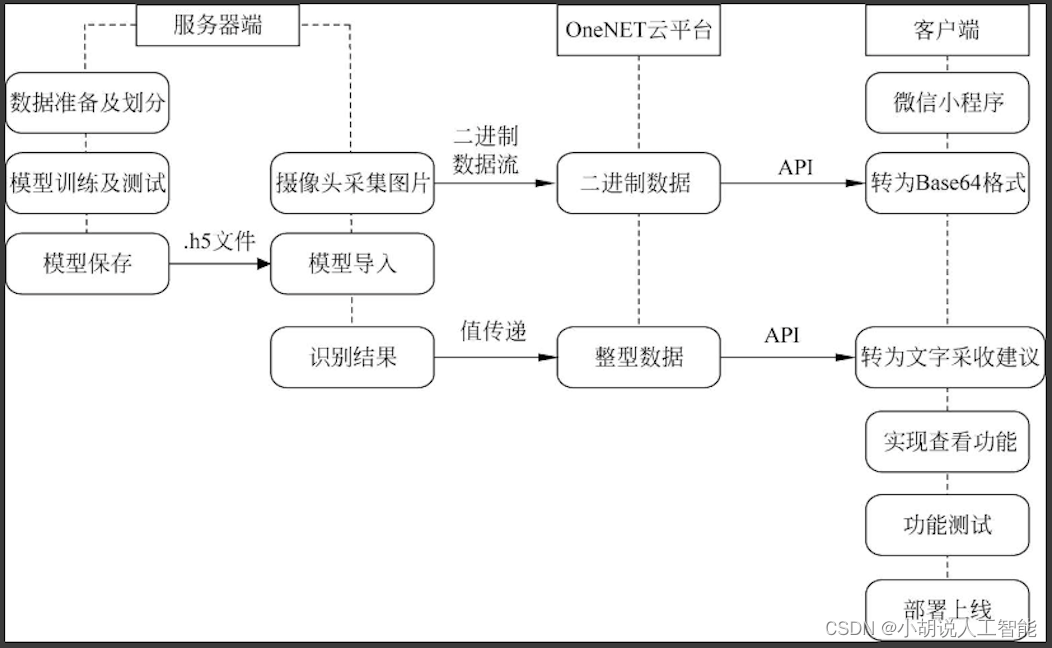
系统流程图
模型训练流程如图所示。
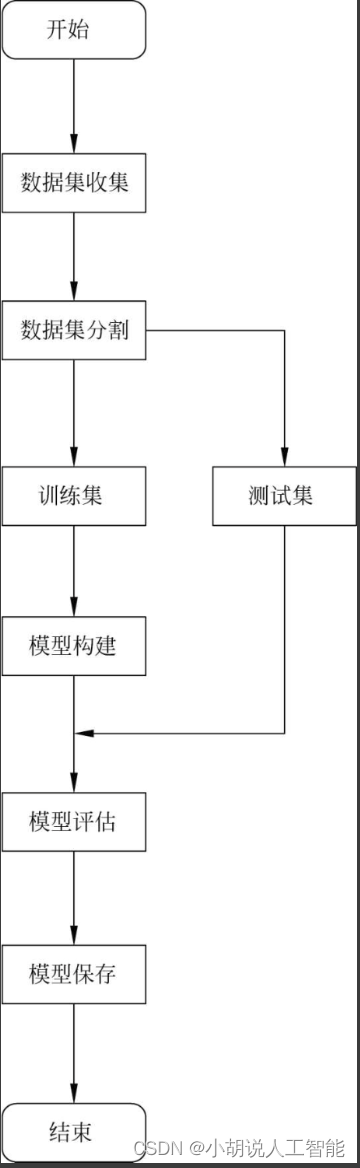
数据上传流程如图所示。
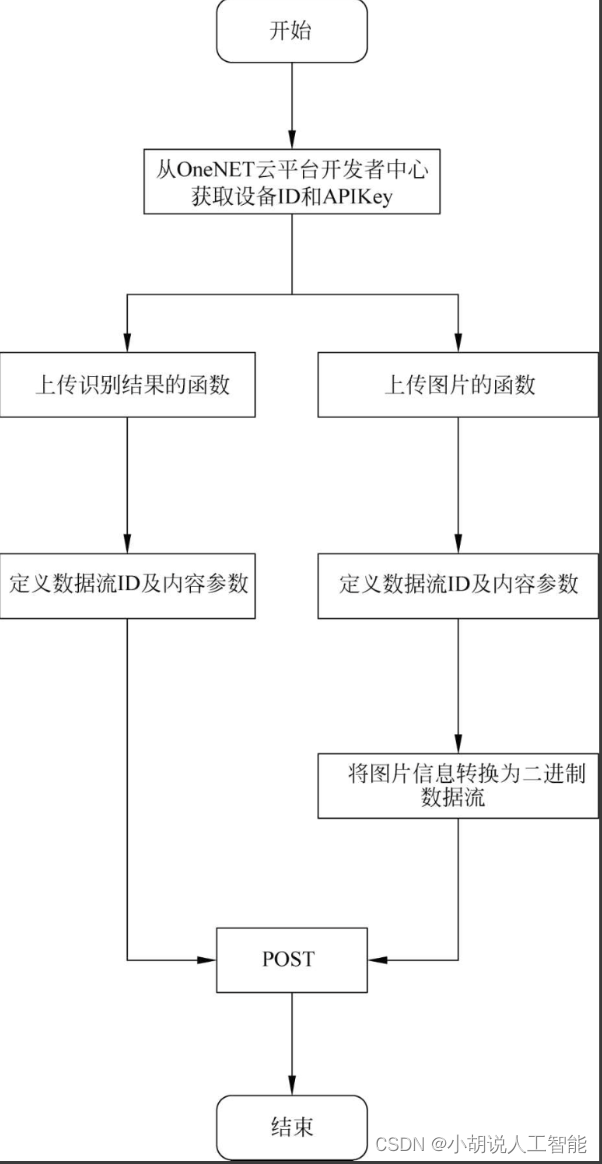
小程序流程如图所示。
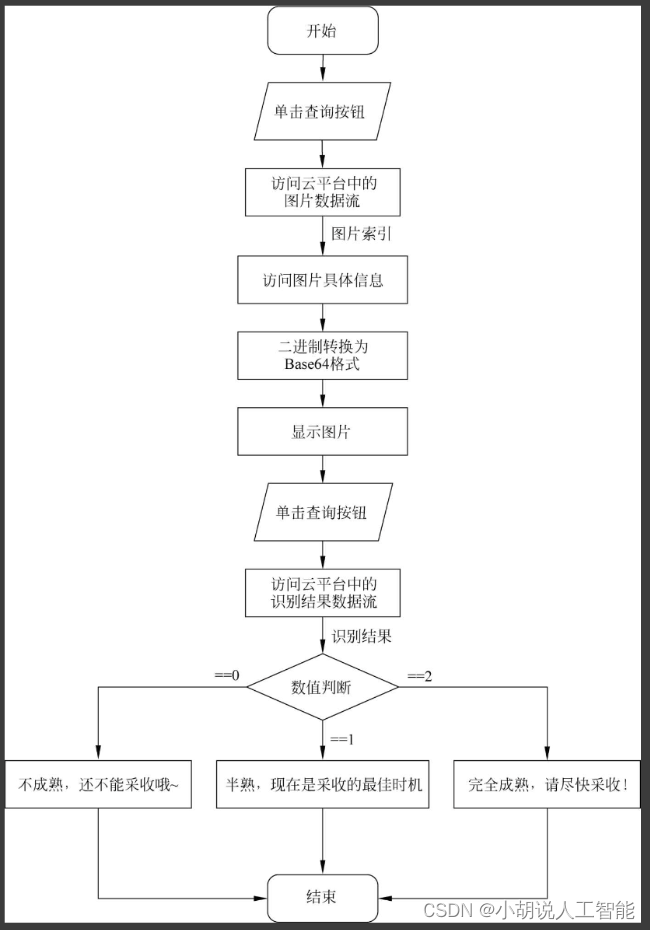
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境、微信开发者工具和OneNET云平台。
Python环境
详见博客。
TensorFlow 环境
详见博客。
Jupyter Notebook环境
详见博客。
Pycharm 环境
详见博客。
微信开发者工具
详见博客。
OneNET云平台
详见博客。
模块实现
本项目包括本项目包括5个模块:数据预处理、创建模型与编译、模型训练及保存、上传结果、小程序开发。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
以红枣为实验对象,在互联网上爬取1000张图片作为数据集。
详见博客。
2. 创建模型并编译
数据加载进模型之后,需要定义模型结构并优化损失函数。
详见博客。
3. 模型训练及保存
定义模型架构和编译之后,通过训练集训练,使模型可以识别红枣的成熟程度。这里将使用训练集和测试集来拟合并保存模型。
1)模型训练
本部分相关代码如下:
#model.fit函数返回一个History的对象
#History属性记录了损失函数和其他指标的数值随epoch变化的情况
hist =model.fit(x = train_data, y = train_label,validation_data=[test_data, test_label], epochs = 500, batch_size = 64)
hist.history['val_acc'][0]#记录运行输出
preds = model.evaluate(test_data, test_label)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
其中,一个batch就是在一次前向/后向传播过程用到的训练样例数量,本项目中每一次用64张图片进行训练。预处理数据集后,按照8:2的比例划分训练集和测试集,如图所示。

通过观察训练集和测试集的损失函数、准确率的大小来评估模型的训练程度,并进行模型训练的进一步决策。一般来说,训练集和测试集的损失函数(或准确率)不变且基本相等为模型训练的最佳状态。
可以将训练过程中保存的准确率和损失函数以图片的形式呈现。
import numpy as np
import matplotlib.pyplot as plt
#绘制曲线
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是“-”显示为方块的问题
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
lns1 = ax1.plot(np.arange(500), loss, label="Loss")
#按一定间隔显示实现方法
#ax2.plot(200 * np.arange(len(fig_accuracy)), fig_accuracy, 'r')
lns2 = ax2.plot(np.arange(500), acc, 'r', label="Accuracy")
ax1.set_xlabel('训练轮次')
ax1.set_ylabel('训练损失值')
ax2.set_ylabel('训练准确率')
#合并图例
lns = lns1 + lns2
labels = ["损失", "准确率"]
#labels = [l.get_label() for l in lns]
plt.legend(lns, labels, loc=7)
plt.show()
2)模型保存
为能够被Python程序读取,将模型保存为.h5格式,利用Keras中的Model模块进行保存。模型被保存后,可以被重用,也可以移植到其他环境中使用。
from keras.models import Model
model = HappyModel((IMG_H,IMG_W,3))
#保存为.h5文件
model.save('C:/Users/SeverusSnape/Desktop/myProject/classifier_3.h5')
模型被保存后,可以被重用,也可以移植到其他环境中使用。
4. 上传结果
上传结果有两种方法:一是调用计算机摄像头拍摄图片,将图片信息转换为二进制数据流后上传至OneNET云平台;二是将数字图片输入Keras模型中,获取输出后将识别结果上传至OneNET云平台。
1)图片拍摄
图片拍摄具体操作如下:
(1)调用摄像头需要引入cv2类,对数据进行保护。
import cv2
(2)调用cv2类中的VideoCapture函数,实现调用笔记本内置摄像头拍摄的功能。
#调用笔记本内置摄像头,参数为0,如果有其他的摄像头可以调整参数为1,2
cap=cv2.VideoCapture(0)
while True:#从摄像头读取图片sucess,img=cap.read()#显示摄像头cv2.imshow("img",img)#等待时延为1ms,保持画面的持续k=cv2.waitKey(1)if k == 27:#通过ESC键退出摄像cv2.destroyAllWindows()breakelif k == 13:#通过回车保存图片,并退出cv2.imwrite('C:/Users/SeverusSnape/Desktop/myProject/images/try.png',img)cv2.destroyAllWindows()break
#关闭摄像头
cap.release()
2)模型导入及调用
模型导入及调用的相关操作如下:
(1)把训练好的.h5文件放入myProject项目目录。
(2)加载Keras模型库,调用Keras模型得到预测结果。
from keras.models import load_model
(3)在xxxtsj.ipynb中声明模型存放路径,调用load_model()函数。
#加载模型.h5文件
model=load_model('C:/Users/SeverusSnape/Desktop/myProject/classifier_3.h5')
#定义规范化图片大小和像素值的函数
def get_inputs(src=[]):rsltData = []for s in src:input = cv2.imread(s)#读入图像,BGRinput = cv2.resize(input, (IMG_W, IMG_H))#缩放input = cv2.cvtColor(input, cv2.COLOR_BGR2RGB)#将BGR图片转成RGB
pre_y=model.predict(np.reshape(input,[1,IMG_H,IMG_W,3]),batch_size=1)print(np.argmax(pre_y, axis=1))#打印最大概率对应的标签a=np.argmax(pre_y,axis=1)#必须通过遍历否则格式不对,不止包含数还包括btypyfor i in a:rsltData.append(i)#将最大概率对应的标签加入rsltData列表尾部return rsltData
predict_dir = 'C:/Users/SeverusSnape/Desktop/myProject/images/'
#要预测图片所在的文件夹
picName = os.listdir(predict_dir)#获得文件夹内的文件名
images = []
for testpath in picName:fn = os.path.join(predict_dir, testpath)if fn.endswith('png'):#后缀是png的文件会被存入images列表picData = fnprint(picData)#打印被存入的图片地址images.append(picData)#地址存入images列表
rsltData = get_inputs(images)#调用规范化图片函数得到最大概率对应标签
3)数据上传OneNET云平台
本部分包括图片信息上传和识别结果上传。
(1)图片信息上传
将图片信息转换成二进制数据流,使用POST方法上传。
#定义图片上传函数
http_put_pic(data):url = "http://api.heclouds.com/bindata"headers = {"Content-Type": "image/png", #格式"api-key": "93IlIl2tfXddMN8sgQIInc7qbXs=", }#device_id是设备ID#datastream_id是数据流IDquerystring = {"device_id": "586488389", "datastream_id": "pic"}#流式上传with open(data, 'rb') as f:requests.post(url, params=querystring, headers=headers, data=f)
(2)预测结果上传
因为识别的结果是整型数据,直接使用POST方法上传数值。
#定义预测结果上传函数
def http_put_rslt(data):url = "http://api.heclouds.com/devices/" + deviceId + '/datapoints'd = time.strftime('%Y-%m-%dT%H:%M:%S')data = int(data) #将Numpy数据int64转化成json可识别的intvalues = {"datastreams": [{"id": "rslt", "datapoints": [{"value": data}]}]}jdata = json.dumps(values).encode("utf-8")request = urllib.request.Request(url, jdata) #获取链接数据request.add_header('api-key', APIKey)request.get_method = lambda: 'POST' #POST方法request = urllib.request.urlopen(request)return request.read()
相关其它博客
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(一)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(二)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(三)
基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(五)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于基于OpenCV+CNN+IOT+微信小程序智能果实采摘指导系统——深度学习算法应用(含pytho、JS工程源码)+数据集+模型(四)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








